背景
一个具体的文件在打开后,内核会在内存中为之建立一个struct inode结构(该inode结构也会在对应的file结构体中引用),其中的i_mapping域指向一个address_space结构。这样一个文件就对应一个address_space结构;address_space对象是文件系统中关于内存中页高速缓存的核心数据结构。
页高速缓存
页高速缓存,它是一种对完整的数据页进行操作的磁盘高速缓存,即把磁盘的数据块缓存在页高速缓存中。而address_space对页高速缓存进行管理。linux中几乎所有文件的读和写操作都依赖于页高速缓存。只有在O_DIRECT标志置为才会出现意外:此时,I/O数据的传送绕过了页高速缓存而使用了进程用户态地址空间的缓冲区;另外,少量的数据库软件为了采用自己的磁盘高速缓存算法而使用了O_DIRECT标志。
why设计页高速缓存?
- 快速定位所有者相关数据页的位置(基树)
- 区分不同所有者页的不同读写操作,如普通文件、块设备文件、交换区文件读一个数据页必须使用不同的方式实现,故内核根据页的不同所有者进行不同的操作。
ps:一个物理页面可能包含多个不连续的物理块,由于构成每个页面的块的不连续性,检查page cache以查看是否已缓存某些数据变得更加困难。因此,不可能仅使用设备名称和块号来索引页面缓存中的数据,否则这将是最简单的解决方案。
例如,在x86架构上,物理页面的大小为4KB,而大多数文件系统上的磁盘块可以小到512字节。因此,一个页面中可能包含8个块。块不必是连续的,因为文件本身可能会在整个磁盘上布局
一般情况下用户进程调用mmap()时,只是在进程空间内新增了一块相应大小的缓冲区,并设置了相应的访问标识,但并没有建立进程空间到物理页面的映射。因此第一次访问该空间时,会引发一个缺页异常。对于共享内存映射情况,缺页异常处理程序首先在swap cache中寻找目标页(符合address_space以及偏移量的物理页),如果找到,则直接返回地址;如果没有找到,则判断该页是否在交换区 (swap area),如果在,则执行一个换入操作;如果上述两种情况都不满足,处理程序将分配新的物理页面,并把它插入到page cache中。进程最终将更新进程页表。注:对于映射普通文件情况(非共享映射),缺页异常处理程序首先会在page cache中根据address_space以及数据偏移量寻找相应的页面。如果没有找到,则说明文件数据还没有读入内存,处理程序会从磁盘读入相应的页面,并返回相应地址,同时,进程页表也会更新。
/* 它是用于管理文件(struct inode)某些部分映射到内存的页面(struct page)的,其实就是每个file都有这么一个结构, 将文件系统中这个file对应的数据与这个file对应的内存绑定到一起;与之对应,address_space_operations 就是用来 操作该文件映射到内存的页面,比如把内存中的修改写回文件、从文件中读入数据到页面缓冲等。 file结构体和inode结构体中都有一个address_space结构体指针,实际上,file->f_mapping是从对应inode->i_mapping而来, inode->i_mapping->a_ops是由对应的文件系统类型在生成这个inode时赋予的。 */ struct address_space { struct inode *host; /* owner: inode, block_device拥有它的节点 */ struct radix_tree_root page_tree; /* radix tree of all pages 包含全部页面的radix树 */ spinlock_t tree_lock; /* and lock protecting it 保护page_tree的自旋锁*/ atomic_t i_mmap_writable;/* count VM_SHARED mappings 享映射数 VM_SHARED记数*/ struct rb_root i_mmap; /* tree of private and shared mappings 优先搜索树的树根*/ struct rw_semaphore i_mmap_rwsem; /* protect tree, count, list 保护i_mmap的信号量*/ /* Protected by tree_lock together with the radix tree */ unsigned long nrpages; /* number of total pages页总数 */ unsigned long nrshadows; /* number of shadow entries */ pgoff_t writeback_index;/* writeback starts here回写的起始偏移 */ const struct address_space_operations *a_ops; /* methods 操作函数表*/ unsigned long flags; /* error bits/gfp mask gfp_mask掩码与错误标识 */ spinlock_t private_lock; /* for use by the address_space 私有address_space锁 */ struct list_head private_list; /* ditto 私有address_space链表 */ void *private_data; /* ditto 相关的缓冲*/ } __attribute__((aligned(sizeof(long))));
address_space 结构其中的一个作用就是用于存储文件的 页缓存,下面介绍一下各个字段的作用:
host:指向当前address_space对象所属的文件inode对象(每个文件都使用一个inode对象表示)。page_tree:用于存储当前文件的页缓存。tree_lock:用于防止并发访问page_tree导致的资源竞争问题。
从 address_space 对象的定义可以看出,文件的 页缓存 使用了 radix树 来存储。
radix树:又名基数树,它使用键值(key-value)对的形式来保存数据,并且可以通过键快速查找到其对应的值。内核以文件读写操作中的数据偏移量作为键,以数据偏移量所在的页缓存作为值,存储在address_space结构的page_tree字段中。
address_space对象
每一个所有者(可以理解为一个具体的文件,一个inode指向的文件)对应着一个address_space对象,页高速缓存的多个页可能属于一个所有者,从而可以链接到一个address_space对象。那么一个页(page)怎么和一个address_space产生关联的呢?每个页描述符都包括把页链接到页高速缓存的两个字段mapping和index。mapping指向拥有该页的索引节点的address_space对象(inode结构有一个i_mapping指向对应address_space对象),index字段表示在所有者的地址空间中以页大小为单位的偏移量,也就是在所有者的磁盘映像中页中数据的位置。address_space中有一个host字段,该字段指向其所属的inode,也就是address_space中的host字段 与 对应inode中的 i_data字段形成互相指向的关系。若为普通文件,那么inode结点和address_space结构的相应指针的指向关系如下图:
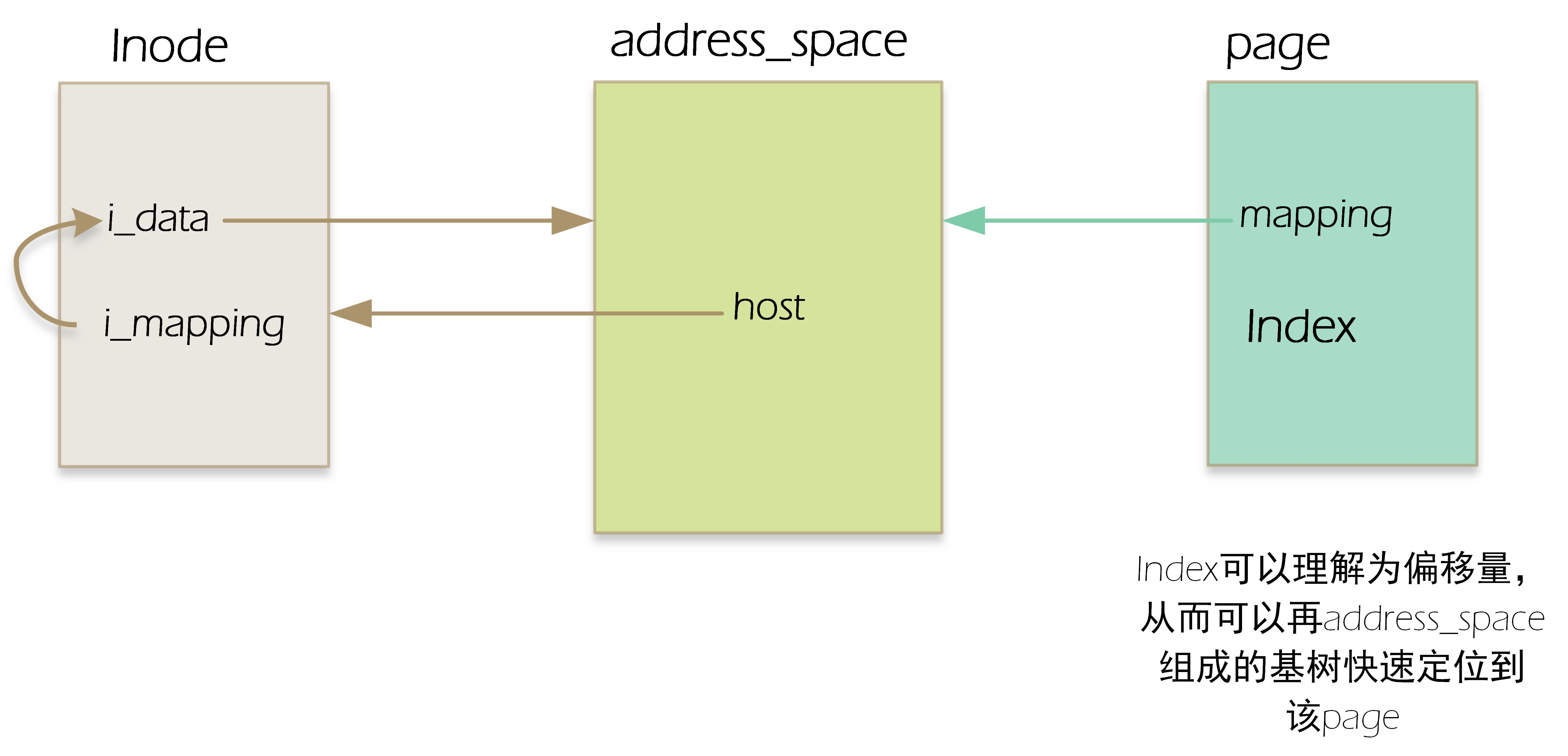
/* * Keep mostly read-only and often accessed (especially for * the RCU path lookup and 'stat' data) fields at the beginning * of the 'struct inode' inode有两种,一种是VFS的inode,一种是具体文件系统的inode。前者在内存中,后者在磁盘中。所以每次其实是将磁盘中的inode调进填充内存中的inode, 这样才是算使用了磁盘文件inode。 inode和文件的关系:当创建一个文件的时候,就给文件分配了一个inode。一个inode只对应一个实际文件,一个文件也会只有一个inode。 inodes最大数量就是文件的最大数量。 */ struct inode { umode_t i_mode;//文件的类型和访问权限 unsigned short i_opflags; kuid_t i_uid;//文件拥有者标号 kgid_t i_gid;//文件所在组标号 unsigned int i_flags; const struct inode_operations *i_op;//索引节点操作函数集 struct super_block *i_sb;//inode所属文件系统的超级块指针 struct address_space *i_mapping;//表示向谁请求页面 于描述页高速缓存中的页面的 /* Stat data, not accessed from path walking */ unsigned long i_ino;//索引节点号,每个inode都是唯一的
struct address_space i_data;//--------------------------------------》 void *i_private; /* fs or device private pointer */ };
struct file { ... struct address_space *f_mapping; };
4 基树
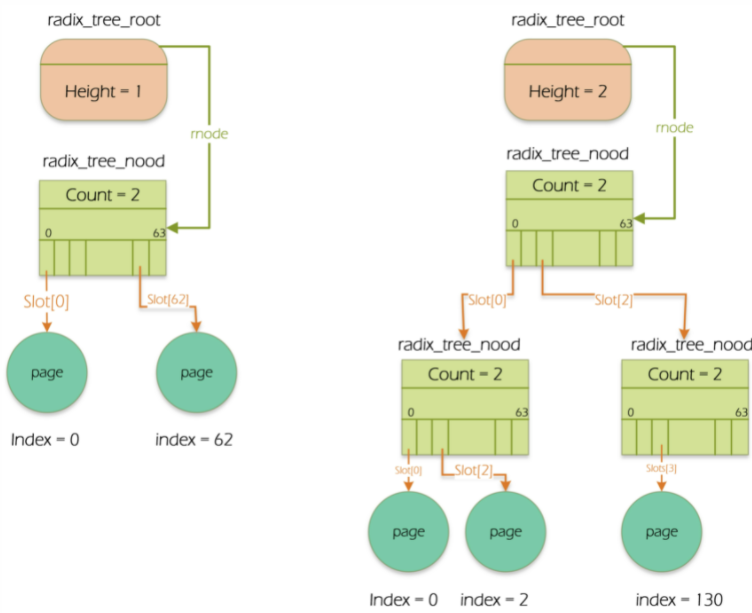
linux支持TB级的文件,ext4甚至支持到了PB级文件,访问大文件时,高速缓存中存在着有关该文件太多的页,故设计了基树这个结构来加快查找。一个address_space对象对应一个基树。
address_space中有一个字段(page_tree)指向是基树的根(radix_tree_root)。基树根中的rnode指向基树的最高层节点(radix_tree_node),基树节点都是radix_tree_node结构,节点中存放的都是指针,叶子节点的指针指向页描述符,上层节点指向存放其他节点的指针。一般一个radix_tree_node最多可以有64个指针,字段count表示该radix_tree_node已用节点数。
怎么快速找到所需页在基树中的位置呢?
--->分页系统如何利用页表实现线性地址到物理地址的转换?线性地址的最高20位分为两个10为的字段:第一个字段是页目录的偏移,第二个字段是页目录所指向也表的偏移。
基树中使用类似的方法。页索引相当于线性地址,不过页索引中要考虑的字段的数量依赖于基树的深度。如果基树的深度为1,就只能表示从0~63范围的索引,因此页索引的低6位被解释为slots数组的下标,每个下标对应第一层的一个节点。如果基树的深度为2,就可以表示从0~4095范围的索引,页索引的低12位分成两个6位的字段,高位的字段用于表示第一层节点数组的下标,而低位的字段用于表示第二层数组的下标。
读文件操作
现在我们来分析一下读取文件数据的过程,用户可以通过调用 read 系统调用来读取文件中的数据,其调用链如下:
read()
└→ sys_read()
└→ vfs_read()
└→ --------()
└→ do_generic_file_read()
磁盘高速缓存。包括页高速缓存(Page Cache,对完整数据页进行操作的磁盘高速缓存) + 目录项高速缓存(Dentry Cache,描述文件系统路径名的目录项对象) + 索引节点高速缓存(Buffer Cache,存放的是描述磁盘索引节点的索引节点对象),本文主要讨论页高速缓存,有了页高速缓存,内核的代码和数据结构不必从磁盘读,也不必写入磁盘。页高速缓存可以看作特定文件系统层的一部分
read 系统调用最终会调用 do_generic_file_read 函数来读取文件中的数据,其实现如下:
void do_generic_file_read(struct address_space *mapping, struct file_ra_state *_ra, struct file *filp, loff_t *ppos, read_descriptor_t *desc, read_actor_t actor) { struct inode *inode = mapping->host; unsigned long index; struct page *cached_page; ... cached_page = NULL; index = *ppos >> PAGE_CACHE_SHIFT; ... for (;;) { struct page *page; ... find_page: // 1. 查找文件偏移量所在的页缓存是否存在 page = find_get_page(mapping, index); if (!page) { ... // 2. 如果页缓存不存在, 那么跳到 no_cached_page 进行处理 goto no_cached_page; } ... page_ok: ... // 3. 如果页缓存存在, 那么把页缓存的数据拷贝到用户应用程序的内存中 ret = actor(desc, page, offset, nr); ... if (ret == nr && desc->count) continue; goto out; ... readpage: // 4. 从文件读取数据到页缓存中 error = mapping->a_ops->readpage(filp, page); ... goto page_ok; ... no_cached_page: if (!cached_page) { // 5. 申请一个内存页作为页缓存 cached_page = page_cache_alloc_cold(mapping); ... } // 6. 把新申请的页缓存添加到文件页缓存中 error = add_to_page_cache_lru(cached_page, mapping, index, GFP_KERNEL); ... page = cached_page; cached_page = NULL; goto readpage; } out: ... }
do_generic_mapping_read 函数的实现比较复杂,经过精简后,上面代码只留下最重要的逻辑,可以归纳为以下几个步骤:
- 通过调用
find_get_page函数查找要读取的文件偏移量所对应的页缓存是否存在,如果存在就把页缓存中的数据拷贝到应用程序的内存中。 - 否则调用
page_cache_alloc_cold函数申请一个空闲的内存页作为新的页缓存,并且通过调用add_to_page_cache_lru函数把新申请的页缓存添加到文件页缓存和 LRU 队列中(后面会介绍)。 - 通过调用
readpage接口从文件中读取数据到页缓存中,并且把页缓存的数据拷贝到应用程序的内存中。
从上面代码可以看出,当页缓存不存在时会申请一块空闲的内存页作为页缓存,并且通过调用 add_to_page_cache_lru 函数把其添加到文件的页缓存和 LRU 队列中。我们来看看 add_to_page_cache_lru 函数的实现:
int add_to_page_cache_lru(struct page *page, struct address_space *mapping, pgoff_t offset, gfp_t gfp_mask) { // 1. 把页缓存添加到文件页缓存中 int ret = add_to_page_cache(page, mapping, offset, gfp_mask); if (ret == 0) lru_cache_add(page); // 2. 把页缓存添加到 LRU 队列中 return ret; }
add_to_page_cache_lru 函数主要完成两个工作:
- 通过调用
add_to_page_cache函数把页缓存添加到文件页缓存中,也就是添加到address_space结构的page_tree字段中。 - 通过调用
lru_cache_add函数把页缓存添加到 LRU 队列中。LRU 队列用于当系统内存不足时,对页缓存进行清理时使用。
PS:想起来了一个内存问题:
Linux 刚引入的时候, i386 4G 的进程空间典型的是 3G user + 1G kernel 的划分,这教科书上都有说。 那按前面的线性方法, 1G 内核空间,只能映射 1G 物理地址空间,这对内核来说,太掣肘了。所以,折衷方案是, Linux 内核只对 1G 内核空间的前 896 MB 按前面所说的方法线性映射, 剩下的 128 MB 的内核空间, 采用动态映射[1]的方式,即按需映射的方式 ,这样,内核态的访问空间更多了。到了 64 位时代, 内核空间大大增大, 这种限制就没了,内核空间可以完全进行线性映射,不过,基于[1]的缘故, 仍保留有动态映射这部分。
动态映射不全是为了内核空间可以访问更多的物理内存,还有一个重要原因: 当内核需要连续多页面的空间时,如果内核空间全线性映射,那么,可能会出现内核空间碎片化而满足不了这么多连续页面分配的需求。基于此,内核空间也必须有一部分是非线性映射,从而在这碎片化物理地址空间上,用页表构造连续虚拟地址空间,这就是所谓vmalloc空间。