这篇文章 netfilter: implement netfilter SYN proxy介绍了syn proxy
SYNPROXY是一个TCP握手代理,该代理截获TCP连接建立的请求,原生支持是从Linux内核3.13开始的。当一个TCP请求从客户端发出时,首先与该握手代理进行三次握手,其采用SYNCookie技术,只有该请求通过cookie合法性校验,代理服务器才会与服务器进行真正的TCP三次握手,此时客户端和服务端之间的连接才真正建立,进入数据传输阶段。流程图如下
关于SYN-ACK的接收窗口
第2步中握手代理回复给客户端的SYN-ACK携带的接收窗口大小为0
第5步中真实服务器回复给握手代理的SYN-ACK携带的接收窗口要透传给客户端
问题1:为什么要这样做?
关于SYN-ACK的ISN(初始序列号)
第2步中握手代理回复给客户端的SYN-ACK中的ISN是由握手代理生成的
第5步中真实服务器回复给握手代理的SYN-ACK中的ISN是由真实服务器生成的 问题2:代理既然要做到透明,一个连接怎么调和两个不同的ISN?
关于窗口的问题
什么第二步握手代理回复的SYN-ACK报文的接收窗口大小为0?
在客户端和服务器端真正建立连接前,首先,握手代理和客户端要进行三次握手,其次才是握手代理和服务端的三次握手,若是在此时,客户端发送数据过来,无疑不会被服务端正确接收。为了避免这种情况的发生,握手代理回复给客户端一个大小为0的窗口,告诉客户端“我还没有准备好接收数据”,因为此时仅仅是握手代理和客户端之间的三次握手,真正的连接尚未建立,无法传输数据。
那么,何时何法将服务端真正的窗口大小透传给客户端?当握手代理和服务器完成了三次握手,握手代理再将服务端回复的SYN-ACK报文中真正的窗口大小(图中第五步)透传给客户端,告诉客户端“我准备好了,可以开始传输数据了”。
关于序列号的问题
第二步握手代理回复的SYN-ACK报文中所携带的初始序列号是如何产生的?
这个序列号是握手代理采用SYNCookie技术计算得出的cookie值,这个cookie值根据客户端的SYN报文中的源地址、目的地址、源端口、目的端口等信息计算出来的,准确性很高,使得客户端第三次握手发来的ACK报文几乎无法被伪造。
第五步服务端回复的SYN-ACK报文中所携带的初始序列号,握手代理又如何透传给客户端?
可以看出,两个ISN(ISN1、ISN2)是独立生成的,由于客户端并不知道握手代理的存在,会将握手代理发送的SYN-ACK记录在TCP连接中,在握手代理透传服务端的ACK-SYN时,携带的是服务端生成的ISN2,与之前的ISN1不一样,因此这个透传的SYN-ACK应当是不会被客户端正确接收的。那么,SYNPROXY是如何解决这个问题呢
- 1.握手代理将服务端的SYN-ACK报文去掉SYN标记,仅保留ACK标记,作为一个窗口更新动作发送给客户端;
- 2.对于从服务端收到的任何数据报文,在发往客户端前,调整其序列号使得与客户端握手时的ISN相适应;
- 3.对于从客户端收到的任何数据报文,在发往服务端前,调整其ACK使得与服务端握手时的ISN相适应。
Unfortunately I couldn’t come up with a nicer way to catch just the first SYN and final ACK from the client and not have any more packets hit the target, but even though it doesn’t look to nice, it works well.
任重道远!!!
SYNPROXY的代码实现

代码见内核见ipt_SYNPROXY.c nf_synproxy_core.c文件
初始化
static int __net_init synproxy_net_init(struct net *net) { struct synproxy_net *snet = synproxy_pernet(net); struct nf_conn *ct; int err = -ENOMEM; //创建了一个ct模板,会设置IPS_TEMPLATE_BIT标志 ct = nf_ct_tmpl_alloc(net, &nf_ct_zone_dflt, GFP_KERNEL); if (!ct) goto err1; //添加序列号调整扩展控制块 if (!nfct_seqadj_ext_add(ct)) goto err2; //添加synproxy扩展控制块 if (!nfct_synproxy_ext_add(ct)) goto err2; //设置已经IPS_CONFIRMED_BIT __set_bit(IPS_CONFIRMED_BIT, &ct->status); nf_conntrack_get(&ct->ct_general); snet->tmpl = ct; snet->stats = alloc_percpu(struct synproxy_stats); if (snet->stats == NULL) goto err2; err = synproxy_proc_init(net); if (err < 0) goto err3; return 0; err3: free_percpu(snet->stats); err2: nf_ct_tmpl_free(ct); err1: return err; }
synproxy_target处理:
static unsigned int synproxy_tg4(struct sk_buff *skb, const struct xt_action_param *par) { //获取synproxy配置参数 const struct xt_synproxy_info *info = par->targinfo; struct net *net = xt_net(par); struct synproxy_net *snet = synproxy_pernet(net); struct synproxy_options opts = {}; struct tcphdr *th, _th; if (nf_ip_checksum(skb, xt_hooknum(par), par->thoff, IPPROTO_TCP)) return NF_DROP; th = skb_header_pointer(skb, par->thoff, sizeof(_th), &_th); if (th == NULL) return NF_DROP; //解析syn报文选项 if (!synproxy_parse_options(skb, par->thoff, th, &opts)) return NF_DROP; if (th->syn && !(th->ack || th->fin || th->rst)) {//syn报文 /* Initial SYN from client */ this_cpu_inc(snet->stats->syn_received); if (th->ece && th->cwr) opts.options |= XT_SYNPROXY_OPT_ECN; //取交集 opts.options &= info->options; //只有客户端和服务器端都支持时间戳选项,才有可能使用syn-cookie //因为只有在syn报文中才会存在sack-perm,mss,窗口缩放因子等选项。 //syn-cookie借助时间戳选项保存这些信息,从而可以在ack报文中还原 //这些信息。 if (opts.options & XT_SYNPROXY_OPT_TIMESTAMP) synproxy_init_timestamp_cookie(info, &opts); else//当时间戳选项不支持的话,只能宣告不支持这些选项。 opts.options &= ~(XT_SYNPROXY_OPT_WSCALE | XT_SYNPROXY_OPT_SACK_PERM | XT_SYNPROXY_OPT_ECN); //发送synack报文给客户端 synproxy_send_client_synack(net, skb, th, &opts); consume_skb(skb); return NF_STOLEN; } else if (th->ack && !(th->fin || th->rst || th->syn)) {//ack报文 /* ACK from client */ if (synproxy_recv_client_ack(net, skb, th, &opts, ntohl(th->seq))) { consume_skb(skb); return NF_STOLEN; } else { return NF_DROP; } } return XT_CONTINUE; }
static void synproxy_send_client_synack(struct net *net, const struct sk_buff *skb, const struct tcphdr *th, const struct synproxy_options *opts) { struct sk_buff *nskb; struct iphdr *iph, *niph; struct tcphdr *nth; unsigned int tcp_hdr_size; u16 mss = opts->mss; iph = ip_hdr(skb); tcp_hdr_size = sizeof(*nth) + synproxy_options_size(opts); nskb = alloc_skb(sizeof(*niph) + tcp_hdr_size + MAX_TCP_HEADER, GFP_ATOMIC); if (nskb == NULL) return; skb_reserve(nskb, MAX_TCP_HEADER); //构建IP头 niph = synproxy_build_ip(net, nskb, iph->daddr, iph->saddr); skb_reset_transport_header(nskb); nth = skb_put(nskb, tcp_hdr_size); nth->source = th->dest; nth->dest = th->source; //计算synproxy的初始序列号,这里使用了syncookie。将mss掩藏到初始序列号中。 //收到客户端的ack报文后,将会还原出来。 nth->seq = htonl(__cookie_v4_init_sequence(iph, th, &mss));//使用mss作为因数计算syncookie nth->ack_seq = htonl(ntohl(th->seq) + 1); tcp_flag_word(nth) = TCP_FLAG_SYN | TCP_FLAG_ACK; if (opts->options & XT_SYNPROXY_OPT_ECN) tcp_flag_word(nth) |= TCP_FLAG_ECE; nth->doff = tcp_hdr_size / 4; nth->window = 0; nth->check = 0; nth->urg_ptr = 0; //构建tcp选项 synproxy_build_options(nth, opts); //首包为notrack,所以没有ct synproxy_send_tcp(net, skb, nskb, skb_nfct(skb), IP_CT_ESTABLISHED_REPLY, niph, nth, tcp_hdr_size); }
发送syn报文给真实服务器
//发送syn报文给真实服务器。 //recv_seq为ack报文的发送序列号,它比syn报文的发送序列号多1,我们将 //使用该序列号减去1作为发送给服务器的syn报文的发送序列号,那么请求方向就不 //需要进行序列号调整了。 static void synproxy_send_server_syn(struct net *net, const struct sk_buff *skb, const struct tcphdr *th, const struct synproxy_options *opts, u32 recv_seq) { struct synproxy_net *snet = synproxy_pernet(net); struct sk_buff *nskb; struct iphdr *iph, *niph; struct tcphdr *nth; unsigned int tcp_hdr_size; iph = ip_hdr(skb); //计算报文头部大小 tcp_hdr_size = sizeof(*nth) + synproxy_options_size(opts); nskb = alloc_skb(sizeof(*niph) + tcp_hdr_size + MAX_TCP_HEADER, GFP_ATOMIC); if (nskb == NULL) return; skb_reserve(nskb, MAX_TCP_HEADER); //构建IP头 niph = synproxy_build_ip(net, nskb, iph->saddr, iph->daddr); //复位传输层头 skb_reset_transport_header(nskb); nth = skb_put(nskb, tcp_hdr_size); nth->source = th->source; nth->dest = th->dest; nth->seq = htonl(recv_seq - 1);//将ack报文的序列号减去1作为syn报文的序列号 /* ack_seq is used to relay our ISN to the synproxy hook to initialize * sequence number translation once a connection tracking entry exists. * 这里设置nth->ack_seq有很重要的意义,这里将客户端发送给synproxy的应答序列号-1(实际就是 * synproxy的初始发送序列号)填充在nth->ack_seq中,是为了在hook处理的时候记录到 * synproxy扩展控制块中。详细查看函数ipv4_synproxy_hook。 */ nth->ack_seq = htonl(ntohl(th->ack_seq) - 1); tcp_flag_word(nth) = TCP_FLAG_SYN;//设置syn标志 if (opts->options & XT_SYNPROXY_OPT_ECN)//设置ECN标志 tcp_flag_word(nth) |= TCP_FLAG_ECE | TCP_FLAG_CWR; nth->doff = tcp_hdr_size / 4; nth->window = th->window;//使用客户端的窗口 nth->check = 0; nth->urg_ptr = 0; //构建选项 synproxy_build_options(nth, opts); //设置了标志位syn,这里将为syn代理建立请求方向的ct,该报文会创建ct。这里传递了一个&snet->tmpl->ct_general //ct模板给synproxy_send_tcp,会设置报文nfct,将来在output hook点会根据模板创建ct。 //该模板添加了seqadj和synproxy控制块。 synproxy_send_tcp(net, skb, nskb, &snet->tmpl->ct_general, IP_CT_NEW, niph, nth, tcp_hdr_size); } static void synproxy_send_tcp(struct net *net, const struct sk_buff *skb, struct sk_buff *nskb, struct nf_conntrack *nfct, enum ip_conntrack_info ctinfo, struct iphdr *niph, struct tcphdr *nth, unsigned int tcp_hdr_size) { nth->check = ~tcp_v4_check(tcp_hdr_size, niph->saddr, niph->daddr, 0); nskb->ip_summed = CHECKSUM_PARTIAL; nskb->csum_start = (unsigned char *)nth - nskb->head; nskb->csum_offset = offsetof(struct tcphdr, check); skb_dst_set_noref(nskb, skb_dst(skb)); nskb->protocol = htons(ETH_P_IP); if (ip_route_me_harder(net, nskb, RTN_UNSPEC)) goto free_nskb; if (nfct) { nf_ct_set(nskb, (struct nf_conn *)nfct, ctinfo); nf_conntrack_get(nfct); } ip_local_out(net, nskb->sk, nskb); return; free_nskb: kfree_skb(nskb); }
在synproxy_tg4中完成了synproxy与客户端的三次握手,同时启动了与服务端的三次握手,这些报文由synproxy_tg4处理,synproxy注册的钩子函数不会处理这三个报文;目前使用的都是netfilter的target 处理
synproxy注册的钩子函数
static const struct nf_hook_ops ipv4_synproxy_ops[] = { { .hook = ipv4_synproxy_hook, .pf = NFPROTO_IPV4, .hooknum = NF_INET_LOCAL_IN, .priority = NF_IP_PRI_CONNTRACK_CONFIRM - 1,//优先级非常低,在CONFIRM之前。 }, { .hook = ipv4_synproxy_hook, .pf = NFPROTO_IPV4, .hooknum = NF_INET_POST_ROUTING, .priority = NF_IP_PRI_CONNTRACK_CONFIRM - 1,//优先级非常低,在CONFIRM之前。 }, };
ipv4_synproxy_hook
synproxy在接收到客户端的ack后,会发送syn报文给服务器,此时会根据模板创建CT,状态为NEW。走到NF_INET_POST_ROUTING节点的时候会经过ipv4_synproxy_hook钩子函数。
static unsigned int ipv4_synproxy_hook(void *priv, struct sk_buff *skb, const struct nf_hook_state *nhs) { struct net *net = nhs->net; struct synproxy_net *snet = synproxy_pernet(net); enum ip_conntrack_info ctinfo; struct nf_conn *ct; struct nf_conn_synproxy *synproxy; struct synproxy_options opts = {}; const struct ip_ct_tcp *state; struct tcphdr *th, _th; unsigned int thoff; //前面几个syn,syn-ack,ack报文没有ct,所以直接退出 ct = nf_ct_get(skb, &ctinfo); if (ct == NULL) return NF_ACCEPT; //获取连接跟踪的synproxy控制块 synproxy = nfct_synproxy(ct); if (synproxy == NULL) return NF_ACCEPT; //从lo接口收到的报文,非tcp报文直接退出。 if (nf_is_loopback_packet(skb) || ip_hdr(skb)->protocol != IPPROTO_TCP) return NF_ACCEPT; //获取tcp头地址 thoff = ip_hdrlen(skb); th = skb_header_pointer(skb, thoff, sizeof(_th), &_th); if (th == NULL) return NF_DROP; state = &ct->proto.tcp; switch (state->state) { case TCP_CONNTRACK_CLOSE: if (th->rst && !test_bit(IPS_SEEN_REPLY_BIT, &ct->status)) { nf_ct_seqadj_init(ct, ctinfo, synproxy->isn - ntohl(th->seq) + 1); break; } if (!th->syn || th->ack || CTINFO2DIR(ctinfo) != IP_CT_DIR_ORIGINAL) break; /* Reopened connection - reset the sequence number and timestamp * adjustments, they will get initialized once the connection is * reestablished. */ nf_ct_seqadj_init(ct, ctinfo, 0); synproxy->tsoff = 0; this_cpu_inc(snet->stats->conn_reopened); /* fall through */ case TCP_CONNTRACK_SYN_SENT: if (!synproxy_parse_options(skb, thoff, th, &opts)) return NF_DROP; /* ** 代理发送给sever的syn报文丢失,或者server发送过来的syn-ack丢失,导致连接跟踪处于该状态。客户端发送 ** 保活报文。 ** 保活报文: ** 保活探测报文为一个空报文段(或1个字节),序列号等于对方主机发送的ACK报文的最大序列号减1。 ** 因为这一序列号的数据段已经被成功接收,所以不会对到达的报文段造成影响,但探测报文返回的响应 ** 可以确定连接是否仍在工作。接收方收到该报文以后,会认为是之前丢失的报文,所以不会添加进数据流中。 ** 但是仍然要发送一个ACK确认。探测及其响应报文丢失后都不会重传。探测方主动不重传,相应方的ACK报文 ** 并不能自己重传,所以需要保活探测数。 */ if (!th->syn && th->ack && CTINFO2DIR(ctinfo) == IP_CT_DIR_ORIGINAL) { /* Keep-Alives are sent with SEG.SEQ = SND.NXT-1, * therefore we need to add 1 to make the SYN sequence * number match the one of first SYN. */ if (synproxy_recv_client_ack(net, skb, th, &opts, ntohl(th->seq) + 1)) { this_cpu_inc(snet->stats->cookie_retrans); consume_skb(skb); return NF_STOLEN; } else { return NF_DROP; } } //前面在填充报文的时候将发送给服务器的syn报文的th->ack_seq填充为synproxy的初始发送序列号了。 synproxy->isn = ntohl(th->ack_seq); //这里记录了 if (opts.options & XT_SYNPROXY_OPT_TIMESTAMP) synproxy->its = opts.tsecr;//应答时间戳即为syn+ack报文的初始时间戳 nf_conntrack_event_cache(IPCT_SYNPROXY, ct); break; case TCP_CONNTRACK_SYN_RECV://服务器端发送过来的syn+ack报文经过output节点后处于该状态。 if (!th->syn || !th->ack) break; //解析选项 if (!synproxy_parse_options(skb, thoff, th, &opts)) return NF_DROP; //这段代码放在这里是不合适的,会导致发送给server的ack报文时间戳出错。 //应该放到synproxy_send_server_ack之后。 if (opts.options & XT_SYNPROXY_OPT_TIMESTAMP) { //记录时间戳差值 synproxy->tsoff = opts.tsval - synproxy->its; nf_conntrack_event_cache(IPCT_SYNPROXY, ct); } opts.options &= ~(XT_SYNPROXY_OPT_MSS | XT_SYNPROXY_OPT_WSCALE | XT_SYNPROXY_OPT_SACK_PERM); //opts.tsecr为synproxy的组合时间戳 //opts.tsval为服务器端的syn+ack的时间戳,这里需要回应一个ack给服务器 swap(opts.tsval, opts.tsecr); //发送应答报文给服务器端,该报文的时间戳将会被修改,这里是一个bug。 //实际该报文是不需要修改的。 synproxy_send_server_ack(net, state, skb, th, &opts); //初始化序列号调整上下文。这个时候是应答方向的连接跟踪。 //需要调整服务器端发送给客户端的序列号,因为在第一次握手的时候 //客户端记录的是synproxy提供的初始发送序列号。这里比较synproxy与真实服务器的 //的初始发送序列号的差值。 //同时需要调整客户端发给服务器端的应答序列号。这里记录差值。 //这里的th->seq为服务器发送给客户端的初始发送序列号。 nf_ct_seqadj_init(ct, ctinfo, synproxy->isn - ntohl(th->seq)); nf_conntrack_event_cache(IPCT_SEQADJ, ct); //发送给客户端一个ack报文,用于同步时间戳,窗口缩放因子等选项。 //再次交换回来,与发往server的时间戳相反,这里报文会再次从output出去 //然后在post-routing再次进入该函数,调用synproxy_tstamp_adjust进行 //时间戳调整。 swap(opts.tsval, opts.tsecr); synproxy_send_client_ack(net, skb, th, &opts); consume_skb(skb); return NF_STOLEN; default: break; } //发往客户端的tcp window update报文会走这里进行时间戳调整。 synproxy_tstamp_adjust(skb, thoff, th, ct, ctinfo, synproxy); return NF_ACCEPT; }
时间戳调整
seqadj调整
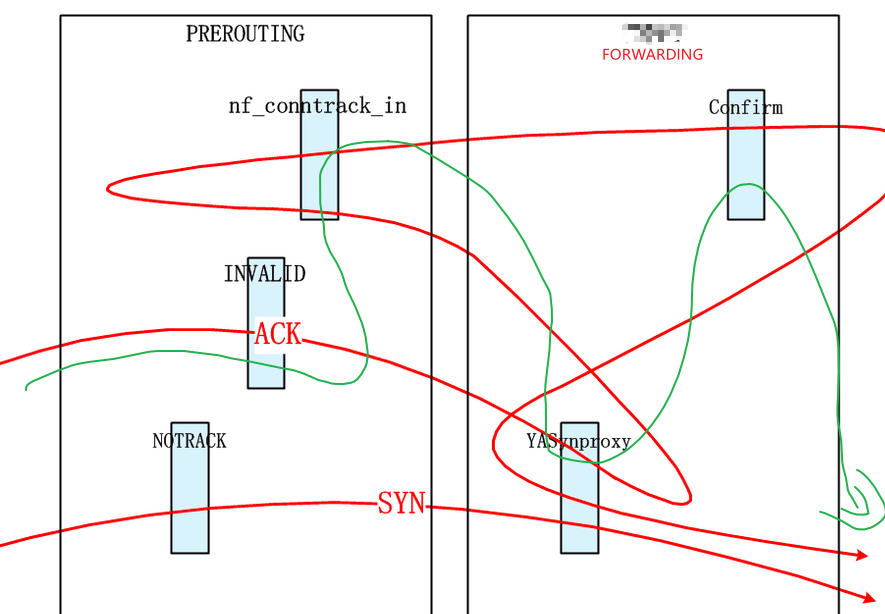
nf_conntrack_tcp_loose的作用
echo 0 > /proc/sys/net/netfilter/nf_conntrack_tcp_loose
设置该值,表示要求连接跟踪严格校验tcp的状态变化,会使得不符合三次握手顺序的报文不会创建CT(在用户态看来就是状态为INVALID的报文)。需要与下面的命令配合使用,下面的命令让syn包不进行连接跟踪,从而破坏连接跟踪的三次握手。
iptables -t raw -A PREROUTING -i eth0 -p tcp --dport 80 --syn -j NOTRACK
synproxy连接跟踪处理
synproxy在给server发送syn报文的时候,有如下调用,在这种情况下给报文设置了一个模板CT,这是与其它情况最大的不同,这直接影响了该报文在OUTPUT节点进入连接跟踪时的创建动作:
//设置了标志位syn,这里将为syn代理建立请求方向的ct,该报文会创建ct。 synproxy_send_tcp(net, skb, nskb, &snet->tmpl->ct_general, IP_CT_NEW, niph, nth, tcp_hdr_size);
unsigned int nf_conntrack_in(struct net *net, u_int8_t pf, unsigned int hooknum, struct sk_buff *skb) { const struct nf_conntrack_l3proto *l3proto; const struct nf_conntrack_l4proto *l4proto; struct nf_conn *ct, *tmpl; enum ip_conntrack_info ctinfo; unsigned int *timeouts; unsigned int dataoff; u_int8_t protonum; int ret; //对于该syn报文,是有一个模板的 tmpl = nf_ct_get(skb, &ctinfo); if (tmpl || ctinfo == IP_CT_UNTRACKED) { /* Previously seen (loopback or untracked)? Ignore. */ if ((tmpl && !nf_ct_is_template(tmpl)) ||//synproxy会设置模板标志,所以不会进去 ctinfo == IP_CT_UNTRACKED) { NF_CT_STAT_INC_ATOMIC(net, ignore); return NF_ACCEPT; } skb->_nfct = 0;//清0 } ... /* It may be an special packet, error, unclean... * inverse of the return code tells to the netfilter * core what to do with the packet. */ if (l4proto->error != NULL) { ret = l4proto->error(net, tmpl, skb, dataoff, pf, hooknum); if (ret <= 0) { NF_CT_STAT_INC_ATOMIC(net, error); NF_CT_STAT_INC_ATOMIC(net, invalid); ret = -ret; goto out; } /* ICMP[v6] protocol trackers may assign one conntrack. */ if (skb->_nfct) goto out; } repeat: //查找其对应的连接跟踪模块。如果是首包的话,会进行创建。 ret = resolve_normal_ct(net, tmpl, skb, dataoff, pf, protonum, l3proto, l4proto); ... return ret; } /* On success, returns 0, sets skb->_nfct | ctinfo */ static int resolve_normal_ct(struct net *net, struct nf_conn *tmpl, struct sk_buff *skb, unsigned int dataoff, u_int16_t l3num, u_int8_t protonum, const struct nf_conntrack_l3proto *l3proto, const struct nf_conntrack_l4proto *l4proto) { const struct nf_conntrack_zone *zone; struct nf_conntrack_tuple tuple; struct nf_conntrack_tuple_hash *h; enum ip_conntrack_info ctinfo; struct nf_conntrack_zone tmp; struct nf_conn *ct; u32 hash; ... /* look for tuple match 从模板中获取zone */ zone = nf_ct_zone_tmpl(tmpl, skb, &tmp); hash = hash_conntrack_raw(&tuple, net); h = __nf_conntrack_find_get(net, zone, &tuple, hash); if (!h) { //根据模板进行初始化 h = init_conntrack(net, tmpl, &tuple, l3proto, l4proto, skb, dataoff, hash); if (!h) return 0; if (IS_ERR(h)) return PTR_ERR(h); } ... return 0; } /* Allocate a new conntrack: we return -ENOMEM if classification failed due to stress. Otherwise it really is unclassifiable. */ static noinline struct nf_conntrack_tuple_hash * init_conntrack(struct net *net, struct nf_conn *tmpl, const struct nf_conntrack_tuple *tuple, const struct nf_conntrack_l3proto *l3proto, const struct nf_conntrack_l4proto *l4proto, struct sk_buff *skb, unsigned int dataoff, u32 hash) { struct nf_conn *ct; struct nf_conn_help *help; struct nf_conntrack_tuple repl_tuple; struct nf_conntrack_ecache *ecache; struct nf_conntrack_expect *exp = NULL; const struct nf_conntrack_zone *zone; struct nf_conn_timeout *timeout_ext; struct nf_conntrack_zone tmp; unsigned int *timeouts; if (!nf_ct_invert_tuple(&repl_tuple, tuple, l3proto, l4proto)) { pr_debug("Can't invert tuple.\n"); return NULL; } zone = nf_ct_zone_tmpl(tmpl, skb, &tmp); //分配连接跟踪 ct = __nf_conntrack_alloc(net, zone, tuple, &repl_tuple, GFP_ATOMIC, hash); if (IS_ERR(ct)) return (struct nf_conntrack_tuple_hash *)ct; //模板必须添加了synproxy扩展控制块 if (!nf_ct_add_synproxy(ct, tmpl)) { nf_conntrack_free(ct); return ERR_PTR(-ENOMEM); } //超时时间使用模板的超时时间 timeout_ext = tmpl ? nf_ct_timeout_find(tmpl) : NULL; if (timeout_ext) { timeouts = nf_ct_timeout_data(timeout_ext); if (unlikely(!timeouts)) timeouts = l4proto->get_timeouts(net); } else { timeouts = l4proto->get_timeouts(net); } /* 协议相关初始化,对于tcp而言会进行状态转换检查,比如首包不是syn包则建不起连接 */ if (!l4proto->new(ct, skb, dataoff, timeouts)) { nf_conntrack_free(ct); pr_debug("can't track with proto module\n"); return NULL; } if (timeout_ext) nf_ct_timeout_ext_add(ct, rcu_dereference(timeout_ext->timeout), GFP_ATOMIC); nf_ct_acct_ext_add(ct, GFP_ATOMIC); nf_ct_tstamp_ext_add(ct, GFP_ATOMIC); nf_ct_labels_ext_add(ct); ecache = tmpl ? nf_ct_ecache_find(tmpl) : NULL; nf_ct_ecache_ext_add(ct, ecache ? ecache->ctmask : 0, ecache ? ecache->expmask : 0, GFP_ATOMIC); ... return &ct->tuplehash[IP_CT_DIR_ORIGINAL]; } //添加synproxy控制块的时候会添加seqadj扩展控制块 static inline bool nf_ct_add_synproxy(struct nf_conn *ct, const struct nf_conn *tmpl) { if (tmpl && nfct_synproxy(tmpl)) { if (!nfct_seqadj_ext_add(ct)) return false; if (!nfct_synproxy_ext_add(ct)) return false; } return true; }
synproxy 对四次挥手是怎样处理?
对于tcp 四次挥手的 更新需要关注 tcp_packet 这个函数
old_state = ct->proto.tcp.state; dir = CTINFO2DIR(ctinfo); index = get_conntrack_index(th); new_state = tcp_conntracks[dir][index][old_state]; tuple = &ct->tuplehash[dir].tuple; switch (new_state) { case TCP_CONNTRACK_SYN_SENT: case TCP_CONNTRACK_IGNORE: case TCP_CONNTRACK_TIME_WAIT: case TCP_CONNTRACK_CLOSE: --------------------


old_state = ct->proto.tcp.state; dir = CTINFO2DIR(ctinfo); index = get_conntrack_index(th); new_state = tcp_conntracks[dir][index][old_state]; tuple = &ct->tuplehash[dir].tuple; switch (new_state) { case TCP_CONNTRACK_SYN_SENT: if (old_state < TCP_CONNTRACK_TIME_WAIT) break; /* RFC 1122: "When a connection is closed actively, * it MUST linger in TIME-WAIT state for a time 2xMSL * (Maximum Segment Lifetime). However, it MAY accept * a new SYN from the remote TCP to reopen the connection * directly from TIME-WAIT state, if..." * We ignore the conditions because we are in the * TIME-WAIT state anyway. * * Handle aborted connections: we and the server * think there is an existing connection but the client * aborts it and starts a new one. */ if (((ct->proto.tcp.seen[dir].flags | ct->proto.tcp.seen[!dir].flags) & IP_CT_TCP_FLAG_CLOSE_INIT) || (ct->proto.tcp.last_dir == dir && ct->proto.tcp.last_index == TCP_RST_SET)) { /* Attempt to reopen a closed/aborted connection. * Delete this connection and look up again. */ spin_unlock_bh(&ct->lock); /* Only repeat if we can actually remove the timer. * Destruction may already be in progress in process * context and we must give it a chance to terminate. */ if (nf_ct_kill(ct)) return -NF_REPEAT; return NF_DROP; } /* Fall through */ case TCP_CONNTRACK_IGNORE: /* Ignored packets: * * Our connection entry may be out of sync, so ignore * packets which may signal the real connection between * the client and the server. * * a) SYN in ORIGINAL * b) SYN/ACK in REPLY * c) ACK in reply direction after initial SYN in original. * * If the ignored packet is invalid, the receiver will send * a RST we'll catch below. */ if (index == TCP_SYNACK_SET && ct->proto.tcp.last_index == TCP_SYN_SET && ct->proto.tcp.last_dir != dir && ntohl(th->ack_seq) == ct->proto.tcp.last_end) { /* b) This SYN/ACK acknowledges a SYN that we earlier * ignored as invalid. This means that the client and * the server are both in sync, while the firewall is * not. We get in sync from the previously annotated * values. */ old_state = TCP_CONNTRACK_SYN_SENT; new_state = TCP_CONNTRACK_SYN_RECV; ct->proto.tcp.seen[ct->proto.tcp.last_dir].td_end = ct->proto.tcp.last_end; ct->proto.tcp.seen[ct->proto.tcp.last_dir].td_maxend = ct->proto.tcp.last_end; ct->proto.tcp.seen[ct->proto.tcp.last_dir].td_maxwin = ct->proto.tcp.last_win == 0 ? 1 : ct->proto.tcp.last_win; ct->proto.tcp.seen[ct->proto.tcp.last_dir].td_scale = ct->proto.tcp.last_wscale; ct->proto.tcp.last_flags &= ~IP_CT_EXP_CHALLENGE_ACK; ct->proto.tcp.seen[ct->proto.tcp.last_dir].flags = ct->proto.tcp.last_flags; memset(&ct->proto.tcp.seen[dir], 0, sizeof(struct ip_ct_tcp_state)); break; } ct->proto.tcp.last_index = index; ct->proto.tcp.last_dir = dir; ct->proto.tcp.last_seq = ntohl(th->seq); ct->proto.tcp.last_end = segment_seq_plus_len(ntohl(th->seq), skb->len, dataoff, th); ct->proto.tcp.last_win = ntohs(th->window); /* a) This is a SYN in ORIGINAL. The client and the server * may be in sync but we are not. In that case, we annotate * the TCP options and let the packet go through. If it is a * valid SYN packet, the server will reply with a SYN/ACK, and * then we'll get in sync. Otherwise, the server potentially * responds with a challenge ACK if implementing RFC5961. */ if (index == TCP_SYN_SET && dir == IP_CT_DIR_ORIGINAL) { struct ip_ct_tcp_state seen = {}; ct->proto.tcp.last_flags = ct->proto.tcp.last_wscale = 0; tcp_options(skb, dataoff, th, &seen); if (seen.flags & IP_CT_TCP_FLAG_WINDOW_SCALE) { ct->proto.tcp.last_flags |= IP_CT_TCP_FLAG_WINDOW_SCALE; ct->proto.tcp.last_wscale = seen.td_scale; } if (seen.flags & IP_CT_TCP_FLAG_SACK_PERM) { ct->proto.tcp.last_flags |= IP_CT_TCP_FLAG_SACK_PERM; } /* Mark the potential for RFC5961 challenge ACK, * this pose a special problem for LAST_ACK state * as ACK is intrepretated as ACKing last FIN. */ if (old_state == TCP_CONNTRACK_LAST_ACK) ct->proto.tcp.last_flags |= IP_CT_EXP_CHALLENGE_ACK; } spin_unlock_bh(&ct->lock); if (LOG_INVALID(net, IPPROTO_TCP)) nf_log_packet(net, pf, 0, skb, NULL, NULL, NULL, "nf_ct_tcp: invalid packet ignored in " "state %s ", tcp_conntrack_names[old_state]); return NF_ACCEPT; case TCP_CONNTRACK_MAX: /* Special case for SYN proxy: when the SYN to the server or * the SYN/ACK from the server is lost, the client may transmit * a keep-alive packet while in SYN_SENT state. This needs to * be associated with the original conntrack entry in order to * generate a new SYN with the correct sequence number. */ if (nfct_synproxy(ct) && old_state == TCP_CONNTRACK_SYN_SENT && index == TCP_ACK_SET && dir == IP_CT_DIR_ORIGINAL && ct->proto.tcp.last_dir == IP_CT_DIR_ORIGINAL && ct->proto.tcp.seen[dir].td_end - 1 == ntohl(th->seq)) { pr_debug("nf_ct_tcp: SYN proxy client keep alive\n"); spin_unlock_bh(&ct->lock); return NF_ACCEPT; } /* Invalid packet */ pr_debug("nf_ct_tcp: Invalid dir=%i index=%u ostate=%u\n", dir, get_conntrack_index(th), old_state); spin_unlock_bh(&ct->lock); if (LOG_INVALID(net, IPPROTO_TCP)) nf_log_packet(net, pf, 0, skb, NULL, NULL, NULL, "nf_ct_tcp: invalid state "); return -NF_ACCEPT; case TCP_CONNTRACK_TIME_WAIT: /* RFC5961 compliance cause stack to send "challenge-ACK" * e.g. in response to spurious SYNs. Conntrack MUST * not believe this ACK is acking last FIN. */ if (old_state == TCP_CONNTRACK_LAST_ACK && index == TCP_ACK_SET && ct->proto.tcp.last_dir != dir && ct->proto.tcp.last_index == TCP_SYN_SET && (ct->proto.tcp.last_flags & IP_CT_EXP_CHALLENGE_ACK)) { /* Detected RFC5961 challenge ACK */ ct->proto.tcp.last_flags &= ~IP_CT_EXP_CHALLENGE_ACK; spin_unlock_bh(&ct->lock); if (LOG_INVALID(net, IPPROTO_TCP)) nf_log_packet(net, pf, 0, skb, NULL, NULL, NULL, "nf_ct_tcp: challenge-ACK ignored "); return NF_ACCEPT; /* Don't change state */ } break; case TCP_CONNTRACK_CLOSE: if (index == TCP_RST_SET && (ct->proto.tcp.seen[!dir].flags & IP_CT_TCP_FLAG_MAXACK_SET) && before(ntohl(th->seq), ct->proto.tcp.seen[!dir].td_maxack)) { /* Invalid RST */ spin_unlock_bh(&ct->lock); if (LOG_INVALID(net, IPPROTO_TCP)) nf_log_packet(net, pf, 0, skb, NULL, NULL, NULL, "nf_ct_tcp: invalid RST "); return -NF_ACCEPT; } if (index == TCP_RST_SET && ((test_bit(IPS_SEEN_REPLY_BIT, &ct->status) && ct->proto.tcp.last_index == TCP_SYN_SET) || (!test_bit(IPS_ASSURED_BIT, &ct->status) && ct->proto.tcp.last_index == TCP_ACK_SET)) && ntohl(th->ack_seq) == ct->proto.tcp.last_end) { /* RST sent to invalid SYN or ACK we had let through * at a) and c) above: * * a) SYN was in window then * c) we hold a half-open connection. * * Delete our connection entry. * We skip window checking, because packet might ACK * segments we ignored. */ goto in_window; } /* Just fall through */ default: /* Keep compilers happy. */ break; }
下面以一个TCP建立连接跟踪的例子来详细分析其过程。下述博客来自
场景:主机A与主机B,主机A向主机B发起TCP连接
站在B的角度,分析连接跟踪在TCP三次握手中的过程。
1. 收到SYN报文 [pre_routing -> local_in]
勾子点PRE_ROUTEING [ipv4_conntrack_in]
ipv4_conntrack_in() -> nf_conntrack_in()
nf_ct_l3protos和nf_ct_protos分别存储注册其中的3层和4层协议的连接跟踪操作,对ipv4而言,它们在__init_nf_conntrack_l3proto_ipv4_init()中被注册(包括tcp/udp/icmp/ipv4),其中ipv4是在nf_ct_l3protos中的,其余是在nf_ct_protos中的。下面函数__nf_ct_l3proto_find()根据协议簇(AF_INET)找到ipv4(即nf_conntrack_l3proto_ipv4)并赋给l3proto;下面函数__nf_ct_l4proto_find()根据协议号(TCP)找到tcp(即nf_conntrack_l4proto_tcp4)并赋给l4proto。
l3proto = __nf_ct_l3proto_find(pf); ret = l3proto->get_l4proto(skb, skb_network_offset(skb), &dataoff, &protonum); ...... l4proto = __nf_ct_l4proto_find(pf, protonum);
然后调用resolve_normal_ct()返回对应的连接跟踪ct(由于是第一次,它会创建ct),下面会详细分析这个函数。l4proto->packet()等价于tcp_packet(),作用是得到新的TCP状态,这里只要知道ct->proto.tcp.state被设置为TCP_CONNTRACK_SYN_SENT,下面也会具体分析这个函数。
ct = resolve_normal_ct(net, tmpl, skb, dataoff, pf, protonum, l3proto, l4proto, &set_reply, &ctinfo); ...... ret = l4proto->packet(ct, skb, dataoff, ctinfo, pf, hooknum); ...... if (set_reply && !test_and_set_bit(IPS_SEEN_REPLY_BIT, &ct->status)) nf_conntrack_event_cache(IPCT_REPLY, ct);
resolve_normal_ct()
先调用nf_ct_get_tuple()从当前报文skb中得到相应的tuple,然后调用nf_conntrack_find_get()来判断连接跟踪是否已存在,已记录连接的tuple都会存储在net->ct.hash中。如果已存在,则直接返回;如果不存在,则调用init_conntrack()创建新的,最后设置相关的连接信息。
就本例中收到SYN报文而言,是第一次收到报文,显然在hash表中是没有的,进而调用init_conntrack()创建新的连接跟踪,下面会具体分析该函数;最后根据报文的方向及所处的状态,设置ctinfo和set_reply,此时方向是IP_CT_DIR_ORIGIN,ct->status未置值,因此最终*ctinfo=IP_CT_NEW; *set_reply=0。ctinfo是很重要的,它表示连接跟踪所处的状态,如同TCP建立连接,连接跟踪建立也要经历一系列的状态变更,skb->nfctinfo=*ctinfo记录了此时的状态(注意与TCP的状态相区别,两者没有必然联系)。
if (!nf_ct_get_tuple(skb, skb_network_offset(skb), dataoff, l3num, protonum, &tuple, l3proto, l4proto)) { pr_debug("resolve_normal_ct: Can't get tuple\n"); return NULL; } h = nf_conntrack_find_get(net, zone, &tuple); if (!h) { h = init_conntrack(net, tmpl, &tuple, l3proto, l4proto, skb, dataoff); …… } ct = nf_ct_tuplehash_to_ctrack(h); if (NF_CT_DIRECTION(h) == IP_CT_DIR_REPLY) { *ctinfo = IP_CT_ESTABLISHED + IP_CT_IS_REPLY; *set_reply = 1; } else { if (test_bit(IPS_SEEN_REPLY_BIT, &ct->status)) { pr_debug("nf_conntrack_in: normal packet for %p\n", ct); *ctinfo = IP_CT_ESTABLISHED; } else if (test_bit(IPS_EXPECTED_BIT, &ct->status)) { pr_debug("nf_conntrack_in: related packet for %p\n", ct); *ctinfo = IP_CT_RELATED; } else { pr_debug("nf_conntrack_in: new packet for %p\n", ct); *ctinfo = IP_CT_NEW; } *set_reply = 0; } skb->nfct = &ct->ct_general; skb->nfctinfo = *ctinfo;
init_conntrack()
该函数创建一个连接跟踪,由触发的报文得到了tuple,然后调用nf_ct_invert_tuple()将其反转,得到反向的repl_tuple,nf_conntrack_alloc()为新的连接跟踪ct分配空间,并设置了
ct->tuplehash[IP_CT_DIR_ORIGINAL].tuple = tuple;
ct->tuplehash[IP_CT_DIR_REPLY].tuple = repl_tuple;
l4_proto是根据报文中协议号来查找到的,这里是TCP连接因此l4_proto对应于nf_conntrack_l4proto_tcp4;l4_proto->new()的作用在于设置TCP的状态,即ct->proto.tcp.state,这个是TCP协议所特有的(TCP有11种状态的迁移图),这里只要知道刚创建时ct->proto.tcp.state会被设置为TCP_CONNTRACK_NONE,最后将ct->tuplehash加入到了net->ct.unconfirmed,因为这个连接还是没有被确认的,所以加入的是uncorfirmed链表。
这样,init_conntrack()创建后的连接跟踪情况如下(列出了关键的元素):
tuple A_ip A_port B_ip B_port ORIG
repl_tuple B_ip B_port A_ip A_port REPLY
tcp.state NONE
tcp_packet()
函数的作用在于通过连接当前的状态,到达的新报文,得到连接新的状态并进行更新,其实就是一次查询,输入是方向+报文信息+旧状态,输出是新状态,因此可以用查询表来简单实现,tcp_conntracks[2][6][TCP_CONNTRACK_MAX]就是这张查询表,它在nf_conntrack_proto_tcp.c中定义。第一维[2]代表连接的方向,第二维[6]代表6种当前报文所带的信息(根椐TCP报头中的标志位),第三维[TCP_CONNTRACK_MAX]代表旧状态,而每个元素存储的是新状态。

下面代码完成了表查询,old_state是旧状态,dir是当前报文的方向(它在resolve_normal_ct中赋值,简单来说是最初的发起方向作为正向),index是当前报文的信息,get_conntrack_index()函数代码也贴在下面,函数很简单,通过TCP报头的标志位得到报文信息。在此例中,收到SYN,old_state是NONE,dir是ORIG,index是TCP_SYN_SET,最终的结果new_state通过查看tcp_conntracks就可以得到了,它在nf_conntrack_proto_tcp.c中定义,结果可以自行对照查看,本例中查询的结果应为TCP_CONNTRACK_SYN_SENT。
然后switch-case语句根据新状态new_state进行其它必要的设置。
old_state = ct->proto.tcp.state; dir = CTINFO2DIR(ctinfo); index = get_conntrack_index(th); new_state = tcp_conntracks[dir][index][old_state]; switch (new_state) { case TCP_CONNTRACK_SYN_SENT: if (old_state < TCP_CONNTRACK_TIME_WAIT) break; …… }
static unsigned int get_conntrack_index(const struct tcphdr *tcph) { if (tcph->rst) return TCP_RST_SET; else if (tcph->syn) return (tcph->ack ? TCP_SYNACK_SET : TCP_SYN_SET); else if (tcph->fin) return TCP_FIN_SET; else if (tcph->ack) return TCP_ACK_SET; else return TCP_NONE_SET; }
勾子点LOCAL_IN [ipv4_confirm]
ipv4_confirm() -> nf_conntrack_confirm() -> __nf_conntrack_confirm()
这里的ct是之前在PRE_ROUTING中创建的连接跟踪,然后调用hash_conntrack()取得连接跟踪ct的正向和反向tuple的哈希值hash和repl_hash;报文到达这里表示被接收,即可以被确认,将它从net->ct.unconfirmed链中删除(PRE_ROUTEING时插入的,那时还是未确认的),然后置ct->status位IPS_CONFIRMED_BIT,表示它已被确认,同时将tuple和repl_tuple加入net->ct.hash,这一步是由__nf_conntrack_hash_insert()完成的,net->ct.hash中存储所有的连接跟踪。
zone = nf_ct_zone(ct); hash = hash_conntrack(net, zone, &ct->tuplehash[IP_CT_DIR_ORIGINAL].tuple); repl_hash = hash_conntrack(net, zone, &ct->tuplehash[IP_CT_DIR_REPLY].tuple); /* Remove from unconfirmed list */ hlist_nulls_del_rcu(&ct->tuplehash[IP_CT_DIR_ORIGINAL].hnnode); …… set_bit(IPS_CONFIRMED_BIT, &ct->status); …… __nf_conntrack_hash_insert(ct, hash, repl_hash); ……
至此,接收SYN报文完成,生成了一条新的连接记录ct,状态为TCP_CONNTRACK_SYN_SENT,status设置了IPS_CONFIRMED_BIT位。
2. 发送SYN+ACK报文 [local_out -> post_routing]
勾子点LOCAL_OUT [ipv4_conntrack_local]
ipv4_conntrack_local() -> nf_conntrack_in()
这里可以看到PRE_ROUTEING和LOCAL_OUT的连接跟踪的勾子函数最终都进入了nf_conntrack_in()。但不同的是,这次由于在收到SYN报文时已经创建了连接跟踪,并且已添加到了net.ct->hash中,因此这次resolve_normal_ct()会查找到之前插入的ct而不会调用init_conntrack()创建,并且会设置*ctinfo=IP_CT_ESTABLISHED+IP_CT_IS_REPLY,set_reply=1(参见resolve_normal_ct函数)。
ct = resolve_normal_ct(net, tmpl, skb, dataoff, pf, protonum,
l3proto, l4proto, &set_reply, &ctinfo);
取得ct后,同样调用tcp_packet()更新连接跟踪状态,注意此时ct已处于TCP_CONNTRACK_SYN_SENT,在此例中,发送SYN+ACK,old_state是TCP_CONNTRACK_SYN_SENT,dir是REPLY,index是TCP_SYNACK_SET,最终的结果还是查看tcp_conntracks就可以得到了,为TCP_CONNTRACK_SYN_RECV。最后会设置ct->status的IPS_SEEN_REPLY位,因为这次已经收到了连接的反向报文。
ret = l4proto->packet(ct, skb, dataoff, ctinfo, pf, hooknum); ...... if (set_reply && !test_and_set_bit(IPS_SEEN_REPLY_BIT, &ct->status)) nf_conntrack_event_cache(IPCT_REPLY, ct);
勾子点POST_ROUTING [ipv4_confirm]
ipv4_confirm() -> nf_conntrack_confirm()
这里可以看到POST_ROUTEING和LOCAL_IN的勾子函数是相同的。但在进入到nf_conntrack_confirm()后会调用nf_ct_is_confirmed(),它检查ct->status的IPS_CONFIRMED_BIT,如果没有被确认,才会进入__nf_conntrack_confirm()进行确认,而在收到SYN过程的LOCAL_IN节点设置了IPS_CONFIRMED_BIT,所以此处的ipv4_confirm()不做任何动作。实际上,LOCAL_IN和POST_ROUTING勾子函数是确认接收或发送一个报文确实已完成,而不是在中途被丢弃,对完成这样过程的连接都会进行记录即确认,而已确认的连接就没必要再次进行确认了。
static inline int nf_conntrack_confirm(struct sk_buff *skb) { struct nf_conn *ct = (struct nf_conn *)skb->nfct; int ret = NF_ACCEPT; if (ct && ct != &nf_conntrack_untracked) { if (!nf_ct_is_confirmed(ct) && !nf_ct_is_dying(ct)) ret = __nf_conntrack_confirm(skb); if (likely(ret == NF_ACCEPT)) nf_ct_deliver_cached_events(ct); } return ret; }
至此,发送SYN+ACK报文完成,没有生成新的连接记录ct,状态变更为TCP_CONNTRACK_SYN_RECV,status设置了IPS_CONFIRMED_BIT+IPS_SEEN_REPLY位。
3. 收到ACK报文 [pre_routing -> local_in]
勾子点PRE_ROUTEING [ipv4_conntrack_in]
ipv4_conntrack_in() -> nf_conntrack_in()
由于之前已经详细分析了收到SYN报文的连接跟踪处理的过程,这里收到ACK报文的过程与收到SYN报文是相同的,只要注意几个不同点就行了:连接跟踪已存在,连接跟踪状态不同,标识位status不同。
resolve_normal_ct()会返回之前插入的ct,并且会设置*ctinfo=IP_CT_ESTABLISHED,set_reply=0(参见resolve_normal_ct函数)。
ct = resolve_normal_ct(net, tmpl, skb, dataoff, pf, protonum,
l3proto, l4proto, &set_reply, &ctinfo);
取得ct后,同样调用tcp_packet()更新连接跟踪状态,注意此时ct已处于TCP_CONNTRACK_SYN_RECV,在此例中,接收ACK,old_state是TCP_CONNTRACK_SYN_RECV,dir是ORIG,index是TCP_ACK_SET,最终的结果查看tcp_conntracks得到为TCP_CONNTRACK_ESTABLISHED。
ret = l4proto->packet(ct, skb, dataoff, ctinfo, pf, hooknum);
......
勾子点LOCAL_IN [ipv4_confirm]
ipv4_confirm() -> nf_conntrack_confirm()
同发送SYN+ACK报文时POST_ROUTING相同,由于连接是已被确认的,所以在nf_conntrack_confirm()函数中会退出,不会再次确认。
至此,接收ACK报文完成,没有生成新的连接记录ct,状态变更为TCP_CONNTRACK_ESTABLISHED,status设置了IPS_CONFIRMED_BIT+IPS_SEEN_REPLY位。