查看之前的blog:浅析sack
dsack检测
根据RFC 2883,DSACK的处理流程如下:
1)look at the first SACK block :
—If the first SACK block is covered by the Cumulative Acknowledgement field, then it is a D-SACK
block, and is reporting duplicate data.
—Else, if the first SACK block is covered by the second SACK block, then the first SACK block is a
D-SACK block, and is reporting duplicate data.
2)otherwise, interpret the SACK blocks using the normal SACK procedures.
简单来说,符合以下任一情况的,就是DSACK:
1)第一个SACK块的起始序号小于它的确认序号,说明此SACK块包含了确认过的数据。
2)第一个SACK块包含在第二个SACK块中,说明第一个SACK块是重复的
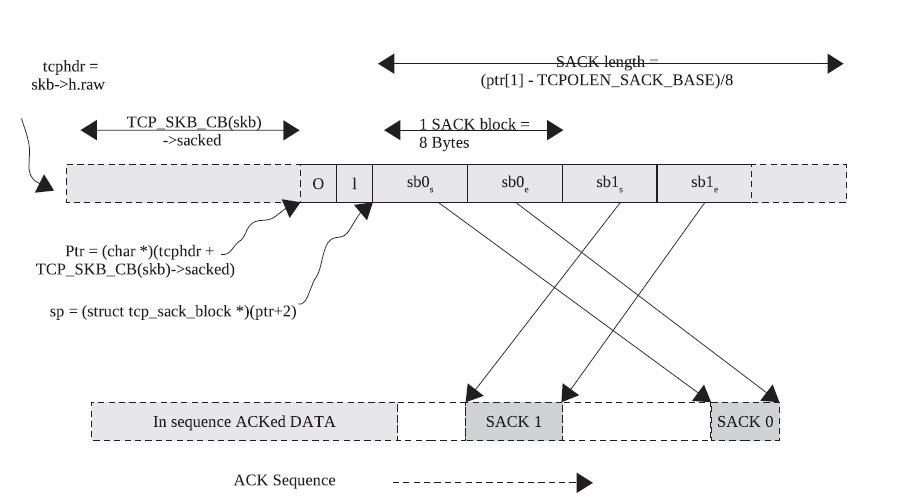
static bool tcp_check_dsack(struct sock *sk, const struct sk_buff *ack_skb, struct tcp_sack_block_wire *sp, int num_sacks, u32 prior_snd_una) { struct tcp_sock *tp = tcp_sk(sk); u32 start_seq_0 = get_unaligned_be32(&sp[0].start_seq);/* 第一个SACK块的起始 */ u32 end_seq_0 = get_unaligned_be32(&sp[0].end_seq);/* 第一个SACK块的结束 */ bool dup_sack = false; /* 如果第一个SACK块的起始序号小于它的确认序号,说明此SACK块包含了确认过的数据, * 所以第一个SACK块是DSACK。 */ if (before(start_seq_0, TCP_SKB_CB(ack_skb)->ack_seq)) { dup_sack = true; tcp_dsack_seen(tp); NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_TCPDSACKRECV); } else if (num_sacks > 1) { u32 end_seq_1 = get_unaligned_be32(&sp[1].end_seq);/* 第二个块的结束序号 */ u32 start_seq_1 = get_unaligned_be32(&sp[1].start_seq);/* 第二个块的起始序号 */ if (!after(end_seq_0, end_seq_1) && !before(start_seq_0, start_seq_1)) {/* 如果第一个SACK块包含在第二个SACK块中,说明第一个SACK块是重复的,即为DSACK */ dup_sack = true; tcp_dsack_seen(tp); NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_TCPDSACKOFORECV); } } /* D-SACK for already forgotten data... Do dumb counting. undo_retrans记录重传数据包的个数,如果undo_retrans降到0, * 就说明之前的重传都是不必要的,进行拥塞调整撤销 */ /* undo_marker为进入Recovery或FRTO状态时记录的snd_una,prior_snd_una为根据该ACK 更新窗口前的snd_una。如果回复的DSACK在这块中间,说明是超时重传或FRTO后进行的重传,因此需要减 少undo_retrans。当undo_retrans减小到0,说明之前的重传都是不必要的,网络并没有拥塞,因此要进行拥 塞调整撤销。*/ if (dup_sack && tp->undo_marker && tp->undo_retrans > 0 && !after(end_seq_0, prior_snd_una) && after(end_seq_0, tp->undo_marker)) tp->undo_retrans--; return dup_sack; }
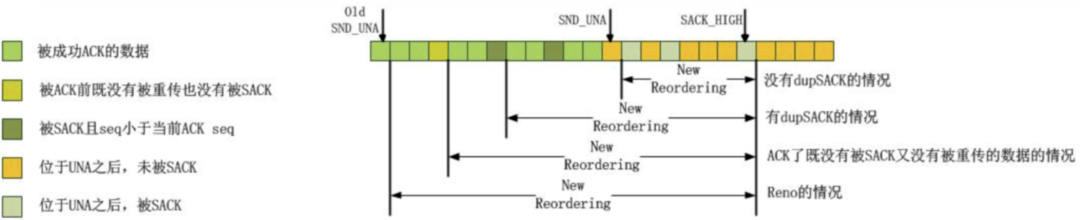
乱序检测的目的时探测网络是否发生重排导致的丢包,并以此来更新 dupthresh 值。只要能收到一个 ACK 或者 SACK,其序列号位于当前已经被 ACK 或 SACK 的数据包最大的序列号之前,就说明网络发生了重排造成了乱序,此时如果涉及的数据包大小大于当前能容忍的网络乱序值,即 dupthresh 值,就说明网络乱序加重了,此时应该更新 dupthresh 值。之所以保持 dupthresh 的值递增,是考虑其初始值 3 只是一个经验值,既然真实检测到乱序,如果其值比 3 小,并不能说明网络的乱序度估计偏大,同时 TCP 保守地递增乱序度,也是为了让快速重传的进入保持保守的姿态,从而增加友好性。