概念
由于网络乱序到达等原因,导致RTO超时重传,但是实际上包没有被丢弃,也就是说RTO超时是一次误判,称为虚假的重传超时(Spurious retransmission timeouts),比如RTT突然增加,比如链路的变更,或是带宽的竞争,或是链路本身rtt波动较大如无线,这些都有可能触发虚假RTO。
F-RTO算法就是为了检测这次重传超时是否是spurious, 然后根据之后的ack信息,决定是发送新数据,还是重传未被ack的包。因此F-RTO算法高效的避免了不必要的重传,并提升了因为超时重传而导致的性能问题
关于重传定时器相关代码可以看以前blog:重传定时器
当TCP段传送超时后,会引起段的重传,在重传定时器的处理过程中会判断是否可以使用F-RTO算法。RTO超时后,跟原来一样重传第一个未被ack的包,进入loss状态,cwnd=1, high_seq=snd_una, 开始慢启动
void tcp_enter_loss(struct sock *sk) { bool new_recovery = icsk->icsk_ca_state < TCP_CA_Recovery; ... tp->snd_cwnd = 1; //重新开始慢启动 ... tcp_set_ca_state(sk, TCP_CA_Loss); //进入loss状态 tp->high_seq = tp->snd_nxt; /* F-RTO RFC5682 sec 3.1 step 1: retransmit SND.UNA if no previous * loss recovery is underway except recurring timeout(s) on * the same SND.UNA (sec 3.2). Disable F-RTO on path MTU probing */ //如果已经在loss/recovery状态或者网络上有重传包,则收到重传包的ack会导致frto误判,认为超时是spurious tp->frto = sysctl_tcp_frto && (new_recovery || icsk->icsk_retransmits) && //rto超时前不在recovery状态,或者重传过 !inet_csk(sk)->icsk_mtup.probe_size; //没有在mtu探测 }
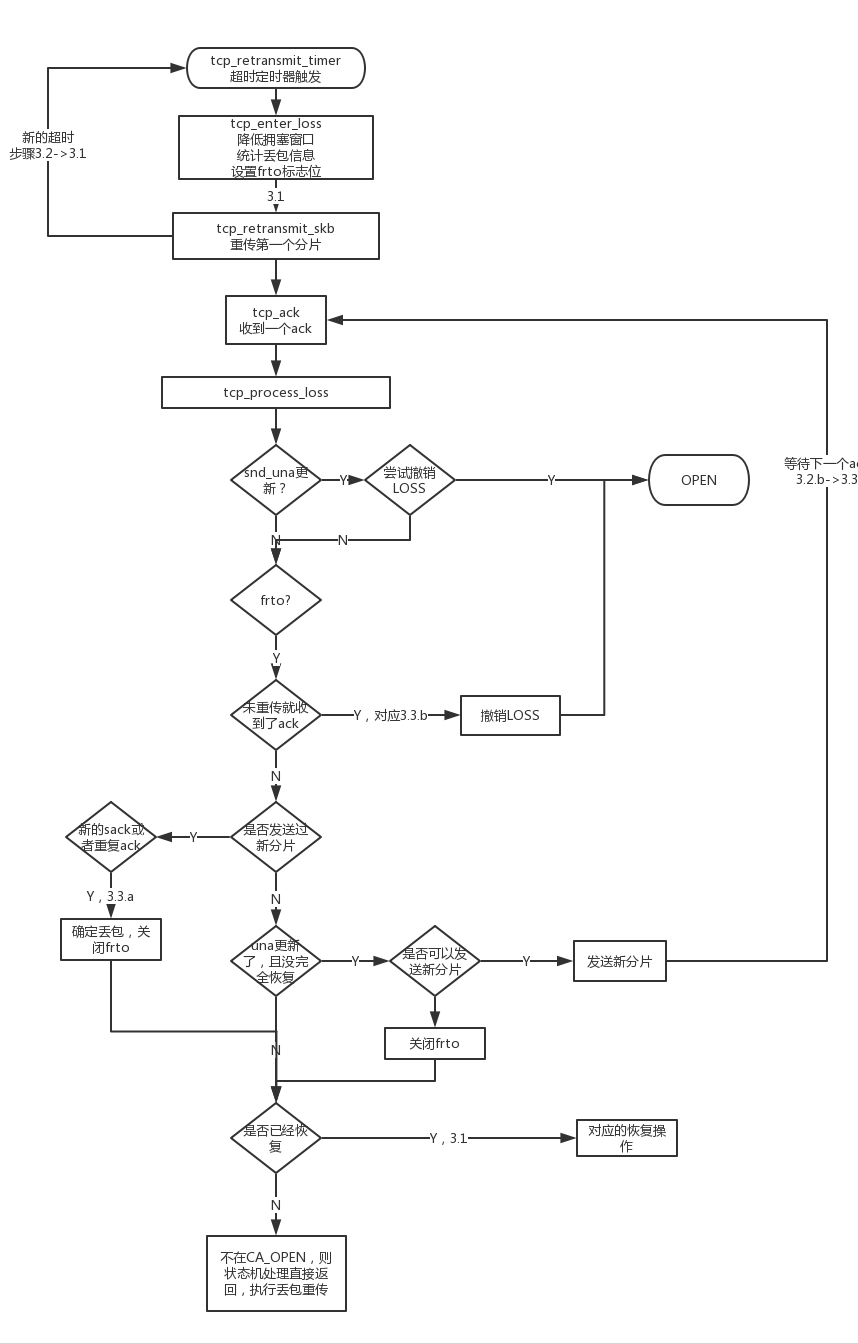
loss状态收到ack后,会调用tcp_process_loss来处理。
step-1: 观察收到的ack,优先尝试按传统undo loss。 如果收到high_seq之前非重传的包被ack/sack,则F-RTO直接判定重传是spurious, 直接undo loss。
step-2: 否则收到第一个让窗口移动的确认后,并且没有全部确认high_seq, 如果有新的数据可以发,则发送新的数据。 没有新数据可以发,则关闭F-RTO,使用传统方式。
step-3: 收到之后的第二个ack后,如果收到sack或者dupack,则说明很可能是新数据sack/dupack, 之前的包很可能真的丢了,frto=0退出F-RTO算法,使用原来的方式
step-4: high_seq之前的包全部被确认了,调用tcp_try_undo_recovery进入open。 因为F-RTO可能发送了新的数据,reno方式不能分辨是重传包导致的dupack还是新数据导致的,只能>high_seq的包被确认后才进入open
static void tcp_process_loss(struct sock *sk, int flag, bool is_dupack) { struct tcp_sock *tp = tcp_sk(sk); bool recovered = !before(tp->snd_una, tp->high_seq); //SND.UNA不在high_seq之前,表明恢复流程已经结束 if ((flag & FLAG_SND_UNA_ADVANCED) && tcp_try_undo_loss(sk, false))//如果ACK报文推进了SND.UNA序号,尝试使用tcp_try_undo_loss进行TCP_CA_Loss状态撤销 return; if (tp->frto) { /* F-RTO RFC5682 sec 3.1 (sack enhanced version). */ /* Step 3.b. A timeout is spurious if not all data are * lost, i.e., never-retransmitted data are (s)acked. 如果S/ACK确认了并没有重传的报文(原始报文),同样尝试进入撤销流程,因为此ACK报文表明RTO值设置的不够长(并非拥塞导致报文丢失), 过早进入了TCP_CA_Loss状态。 */ if ((flag & FLAG_ORIG_SACK_ACKED) &&//high_seq之前的非重传的数据被ack/sack tcp_try_undo_loss(sk, true)) //认为上次超时是spurious的,undo return; //走到这里表明 ----重传数据被ack/sack或者新发送的数据sack, 或者reno收到dupack if (after(tp->snd_nxt, tp->high_seq)) {//有新数据发送,说明是f-rto算法的第2个ack // 如果是刚进入LOSS状态,会先尝试重传,这时候snd_nxt总是等于high_seq的, // 这个分支主要对应3.2.b之后发送了两个新分片。 // 虽然发送了新分片,没有发重传,但是这时候收到的ack并没有更新una // 说明这个rtt中,之前una的包仍旧没有达到,因此这里认为他是真的超时// 关闭frto。对应3.3.a if (flag & FLAG_DATA_SACKED || is_dupack)//收到sack或者dupack,说明对方收到乱序包 tp->frto = 0; /* Step 3.a. loss was real loss 说明loss判断是对的,关闭frto算法*/ } else if (flag & FLAG_SND_UNA_ADVANCED && !recovered) {//窗口移动, 但high_seq没有全部确认 // 这里进入的条件为// 1. snd_nxt == high_seq,还没发送过新分片// 2. una更新过,且没有完全恢复 // 执行3.2.b,发送新分片。// 对应论文图中收到了一个更新过snd_una的ack。 tp->high_seq = tp->snd_nxt; __tcp_push_pending_frames(sk, tcp_current_mss(sk), TCP_NAGLE_OFF);//F-FTO发送新数据 /*/Else, if the acknowledgment advances the window AND the Acknowledgment field does not cover "recover", transmit up to two new (previously unsent) segments and enter step 3*/ if (after(tp->snd_nxt, tp->high_seq))//有新数据发送则返回,不重传 return; /* Step 2.b */ tp->frto = 0; } } //snd_una > high_seq // 已经完全恢复,则撤销对应的恢复操作,并进入TCP_CA_OPEN状态。后续将进入恢复状态。 // 这里主要处理了其他几个不在FRTO可处理的场景,如3.2.a和3.3.a // 唯一进入这里但frto还可能生效的场景为: // 发送新分片后,但是收到了一个不是新的sack,且不是一个dup sack。 // 在这种情况下的处理应该和上一个旧的sack相同。 if (recovered) {//为此ACK报文表明RTO值设置的不够长(并非拥塞导致报文丢失),过早进入了TCP_CA_Loss状态。 /* F-RTO RFC5682 sec 3.1 step 2.a and 1st part of step 3.a */ tcp_try_undo_recovery(sk); return; } //snd_una < high_seq, 进入loss前发送的包没有全部确认 if (tcp_is_reno(tp)) { /* A Reno DUPACK means new data in F-RTO step 2.b above are * delivered. Lower inflight to clock out (re)tranmissions. */ if (after(tp->snd_nxt, tp->high_seq) && is_dupack) //snd_nxt > high_seq 很可能是frto中发送的新数据被dupack tcp_add_reno_sack(sk);//就dupack,减少inflight包数量,从而减少重传包 else if (flag & FLAG_SND_UNA_ADVANCED)//本次窗口更新 una 在增长 tcp_reset_reno_sack(tp); //因为reno只会重传第一个包,窗口滑动reno就可以重置了 } tcp_xmit_retransmit_queue(sk); }
F-RTO发送新数据
static void tcp_process_loss(struct sock *sk, int flag, bool is_dupack) { struct tcp_sock *tp = tcp_sk(sk); bool recovered = !before(tp->snd_una, tp->high_seq); //SND.UNA不在high_seq之前,表明恢复流程已经结束 ------------------- else if (flag & FLAG_SND_UNA_ADVANCED && !recovered) {//窗口移动, 但high_seq没有全部确认 tp->high_seq = tp->snd_nxt; __tcp_push_pending_frames(sk, tcp_current_mss(sk), TCP_NAGLE_OFF);//F-FTO发送新数据 /*/Else, if the acknowledgment advances the window AND the Acknowledgment field does not cover "recover", transmit up to two new (previously unsent) segments and enter step 3*/ if (after(tp->snd_nxt, tp->high_seq))//有新数据发送则返回,不重传 return; /* Step 2.b */ tp->frto = 0; } } ---------------------------- }
上图转自:mercy_pm
RecoveryPoint:在进行RTO超时重传的时候,当前已发送的数据中的最高系列号,例如发送端发出P1(0-9)、P2(10-19)、P3(20-29)三个TCP报文后如果P1超时重传,那么此时RecoveryPoint就是29,实际linux内部使用high_seq状态变量维护记录的是(RecoveryPoint+1),也就是记录的30。
1、在RTO超时的时候,TCP发送端进入Loss状态,判断是否启动FRTO过程,如果tcp_frto开启,当前不是PMTU过程,且不是进入Loss状态前不是Loss状态或者Recovery状态,那么对这次RTO超时开启FRTO检验。接着发送RTO超时重传报文。
2、如果上一步判断对当前RTO超时启动了FRTO过程,那么对于收到的ACK,判断是否带有SACK信息,并且SACK确认了RecoveryPoint之前的数据且SACK确认的数据是没有在第一步重传的数据。那么认为RTO重传是虚假重传,通过两个操作尝试撤销Loss状态的部分影响,一个是尝试更改拥塞窗口cwnd,另外一个是标识先前的数据包为非丢失状态,重传完,进入Open状态,并退出FRTO过程,不在执行下面的其他步骤。因为先前的数据包标记为非lost状态了,接下来回到正常流程就会发送新的数据包。
3、如果上一步判断中没有认定虚假重传,那么如果这个ACK确认包确认的数据超过RecoveryPoint,那么退回到普通的重传恢复状态,不再执行下面的步骤。
4、如果收到的ACK确认包是RTO后的第一个ACK确认包,且ack number确认了新数据,那么把RecoveryPoint更新为当前发送的最高系列号并尝试发送新的未发送数据。如果没有新数据发送,则退出FRTO过程,执行普通的RTO超时重传处理,不在执行接下来的过程。
5、如果收到了第二个ACK确认包,如果这个确认包SACK了新的数据或者是dup ACK那么认为是真实重传,退出FRTO过程执行普通的RTO超时重传流程。
1) When the retransmission timer expires, retransmit the first unacknowledged segment and set SpuriousRecovery to FALSE. Following the recommendation in the SACK specification [MMFR96], reset the SACK scoreboard. If "RecoveryPoint" is larger than or equal to SND.UNA, do not enter step 2 of this algorithm. Instead, set variable "RecoveryPoint" to indicate the highest sequence number transmitted so far and continue with slow-start retransmissions following the conventional RTO recovery algorithm. 2) Wait until the acknowledgment of the data retransmitted due to the timeout arrives at the sender. If duplicate ACKs arrive before the cumulative acknowledgment for retransmitted data, adjust the scoreboard according to the incoming SACK information. Stay in step 2 and wait for the next new acknowledgment. If the retransmission timeout expires again, go to step 1 of the algorithm. When a new acknowledgment arrives, set variable "RecoveryPoint" to indicate the highest sequence number transmitted so far. a) If the Cumulative Acknowledgment field covers "RecoveryPoint" but not more than "RecoveryPoint", revert to the conventional RTO recovery and set the congestion window to no more than 2 * MSS, like a regular TCP would do. Do not enter step 3 of this algorithm. b) Else, if the Cumulative Acknowledgment field does not cover "RecoveryPoint" but is larger than SND.UNA, transmit up to two new (previously unsent) segments and proceed to step 3. If the TCP sender is not able to transmit any previously unsent data -- either due to receiver window limitation or because it does not have any new data to send -- the recommended action is to refrain from entering step 3 of this algorithm. Rather, continue with slow-start retransmissions following the conventional RTO recovery algorithm. It is also possible to apply some of the alternatives for handling window-limited cases discussed in Appendix A. 3) The next acknowledgment arrives at the sender. Either a duplicate ACK or a new cumulative ACK (advancing the window) applies in this step. Other types of ACKs are ignored without any action. a) If the Cumulative Acknowledgment field or the SACK information covers more than "RecoveryPoint", set the congestion window to no more than 3 * MSS and proceed with the conventional RTO recovery, retransmitting unacknowledged segments. Take this branch also when the acknowledgment is a duplicate ACK and it does not acknowledge any new, previously unacknowledged data below "RecoveryPoint" in the SACK information. Leave SpuriousRecovery set to FALSE. b) If the Cumulative Acknowledgment field or a SACK information in the ACK does not cover more than "RecoveryPoint" AND it acknowledges data that was not acknowledged earlier (either with cumulative acknowledgment or using SACK information), declare the timeout spurious and set SpuriousRecovery to SPUR_TO. The retransmission timeout can be declared spurious, because the segment acknowledged with this ACK was transmitted before the timeout.
翻译版本:
- 3.1: 当重传定时器超时了,首先重传第一个未确认的分片,同时设置SpuriousRecovery为false,并重置sack的计分板。 如果恢复点大于等于下一个要发的包(好像基本不可能,最多等于),则将恢复点设置为当前发送的最大包。进入常规恢复。否则进入step 2。 - 3.2: 等待重传数据的ack到来。如果重复的ack比新的ack更早到达,则更新相应的sack计分板,同时留在第二步,等待新的ack到来。如果重传定时器再次超时,回到第一步。当新的ack到来后,更新恢复点。 - a) 如果到来的ack中包括了恢复点,但不超过恢复点,撤销至普通恢复,同时拥塞窗口设置不大于2倍MSS。不进入第三步。 - b) 如果到来的ack中不包含恢复点,但是收到的包超过未确认包,发送两个新的分片,并进入步骤3。如果当前发送端无法发送新报文(接收窗口限制或者没有新的应用层数据),这里建议不要进入步骤3,而是使用恢复步骤。 -3.3: 下一个ack到来,除了新的ack或者是重复ack,其他ack在这个步骤中都被忽略。 - a) 如果新的ack包含了恢复点,则设置拥塞窗口不超过3倍MSS大小并执行恢复操作,重传未确认分片。这个分支也处理重复ack但是没有确认任何新块的场景。 - b) 如果新的ack或者sack信息中没有包含恢复点,且确认的数据是之前没有确认的,则认为这个超时是一个奇怪的超时,并设置SpuriousRecovery为SPUR_TO。这个重传被标记为奇怪的,因为这个分片在超时前被确认了。 其实论文中的图比rfc这段(恢复点的几个判断理解费力。。)更好理解,也更契合代码,为了识别出虚假的RTO: - 超时后先只重发丢失的一个包(3.1)。 - 判断重传后的第一个新的ack是否更新了snd_una,如果更新了snd_una,就发送新的数据,在判断虚假RTO之前不重传数据(3.2.b) - 如果没重传就已经收到数据,尝试撤销本次RTO,如果撤销成功,这就是一个虚假RTO,进入恢复流程(3.3.b)。如果还是重复ack,则认为这是一个丢包事件(3.3.a)。
F-RTO FRC 文档:rfc5682