核心: 标记正在传输、已经确认段、 已经重传段,然后调整拥塞窗口以及重传算法达到最优传输!
enum tcp_ca_state { TCP_CA_Open = 0, #define TCPF_CA_Open (1<<TCP_CA_Open) TCP_CA_Disorder = 1, #define TCPF_CA_Disorder (1<<TCP_CA_Disorder) TCP_CA_CWR = 2, #define TCPF_CA_CWR (1<<TCP_CA_CWR) TCP_CA_Recovery = 3, #define TCPF_CA_Recovery (1<<TCP_CA_Recovery) TCP_CA_Loss = 4 #define TCPF_CA_Loss (1<<TCP_CA_Loss) };
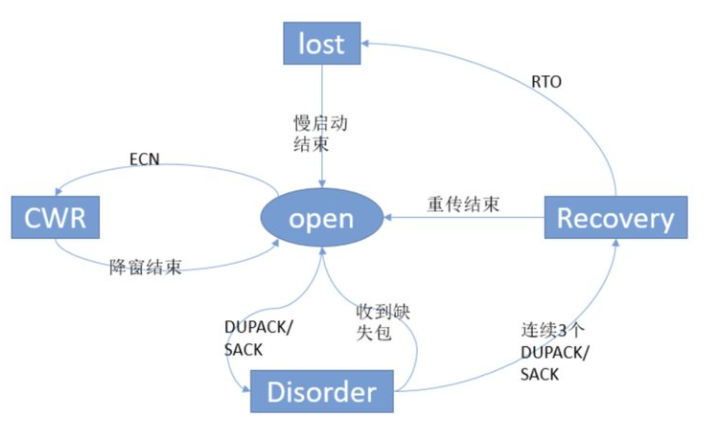
上图中描述了各个状态!
open状态:
open状态是常态, 这种状态下tcp 发送放通过优化后的快速路径来接收处理ack,当一个ack到达时, 发送方根据拥塞窗口是小于还是大于 满启动阈值,按照慢启动或者拥塞避免来增大拥塞窗口
disorder 状态:
当发送方收到 DACK 或者SACK的时候, 将变为disorder 状态, 再次状态下拥塞窗口不做调整,但是没到一个新到的段 就回触发发送一个新的段发送出去此时TCP 遵循发包守恒原则,就是一个新包只有在一个老的包离开网络后才发送;拥塞窗口恒定,网络中数据包守恒
cwr 状态:
发送发被通知出现拥塞通知, 直接告知!! 比喻通过icmp 源端抑制 等方式通知,当收到拥塞通知时,发送方并不是立刻减少拥塞窗口, 而是每个一个新到的ack减小一个段 知道窗口减小到原来的一半为止,发送方在减小窗口过程中如果没有明显重传,就回保持cwr 状态, 但是如果出现明显重传,就回被recovery 或者loss 中断而进入 loss recovery 状态;拥塞窗口减小,且没有明显的重传。
recovery状态:
在收到足够多的连续重复的ack 后,发送方重传第一个没有被确认的段,进入recovery 状态,默认情况下 连续收到三个重复的ack 就回进入recovery状态,在recovery状态期间,拥塞窗口的大小每隔一个新到的确认就会减少一个段, 和cwr 一样 出于拥塞控制期间,这种窗口减少 终止于大小等于ssthresh,也就是进入recovery状态时窗口的一半。发送方重传被标记为丢失的段,或者根据包守恒原则 发送数据,发送方保持recovery 状态直到所有recovery状态中被发送的数据被确认,此时recovery状态就回变为open,超时重传可能中断recovery状态;、
- 经典 Reno 模式(非 SACK 模式)下,
时退出 Recovery 状态。

如上图,数据包 A、B、C 可能没有丢失只是被延迟接收,然而没有 SACK 机制下无法判断是 A、B、C 的重传触发的 3 次重复 ACK 还是新数据 1、2、3 丢失 1(或者 1、2 或者 1、2、3)导致的重复 ACK,两种情况均会马上把拥塞状态机带入到 Recovery 状态,然而前一种是不必要的。如果在 SND_UNA== SND_HIGH 即转为 Open 态,那么当发生上述 1、2、3 的延迟到达后,紧接着的 Recovery 状态会再次将拥塞窗口减半,最终降低到一个极低值。
- SACK/FACK 模式下,
时退出 Recovery 状态。 因为即使发生经典 Reno 模式下的 A、B、C 失序到达,由于存在 SACK 信息,状态机会将此三个重复 ACK 记为三个重复的 DSACK,在 SACK 模式下,判断是否进入 Recovery 状态的条件是被 SACK 的数据包数量大于 dupthresh,而 DSACK 不被计入到 SACKed 数量中。FACK 模式下只影响进入 Recovery 状态的时机,其核心仍建立在 SACK 之上,所以不影响退出的时机。

Loss 状态 :
当一个RTO到期,发送方进入Loss 状态 , 所有正在发送的段都被标记为丢失段,拥塞窗口设置为一个段。发送方启动满启动算法增大窗口。Loss 状态是 拥塞窗口在被重置为一个段后增大,但是recovery状态是拥塞窗口只能被减小, Loss 状态不能被其他状态中断,所以只有所有loss 状态下开始传输的数据得到确认后,才能到open状态, 也就是快速重传不能在loss 状态下触发。当一个RTO 超时, 或者收到ack 的确认已经被以前的sack 确认过, 则意味着我们记录的sack信息不能反应接收方实际的状态,此时就回进入Loss 状态。
- (1)Open:Normal state, no dubious events, fast path.
- (2)Disorder:In all respects it is Open, but requres a bit more attention.It is entered when we see some SACKs or dupacks. It is split of Openmainly to move some processing from fast path to slow one.
- (3)CWR:cwnd was reduced due to some Congestion Notification event.It can be ECN, ICMP source quench, local device congestion.
- (4)Recovery:cwnd was reduced, we are fast-retransmitting.
- (5)Loss:cwnd was reduced due to RTO timeout or SACK reneging.
/* If cwnd > ssthresh, we may raise ssthresh to be half-way to cwnd. * The exception is cwnd reduction phase, when cwnd is decreasing towards * ssthresh. */ static inline __u32 tcp_current_ssthresh(const struct sock *sk) { const struct tcp_sock *tp = tcp_sk(sk); if (tcp_in_cwnd_reduction(sk)) return tp->snd_ssthresh;/*CWR和Recovery时cwnd在减小*/ else return max(tp->snd_ssthresh, /*调大ssthresh*/ ((tp->snd_cwnd >> 1) + (tp->snd_cwnd >> 2))); }
内核只有在报文的重传定时器到期时,在tcp_retransmit_timer函数中,进入TCP_CA_Loss拥塞状态;
/* Enter Loss state. If we detect SACK reneging, forget all SACK information * and reset tags completely, otherwise preserve SACKs. If receiver * dropped its ofo queue, we will know this due to reneging detection. 有关slow start以及Congestion avoidance算法描述可以看rfc2001: http://www.faqs.org/rfcs/rfc2001.html CWND - Sender side limit RWND - Receiver side limit Slow start threshold ( SSTHRESH ) - Used to determine whether slow start is used or congestion avoidance When starting, probe slowly - IW <= 2 * SMSS Initial size of SSTHRESH can be arbitrarily high, as high as the RWND Use slow start when SSTHRESH > CWND. Else, use Congestion avoidance Slow start - CWND is increased by an amount less than or equal to the SMSS for every ACK Congestion avoidance - CWND += SMSS*SMSS/CWND When loss is detected - SSTHRESH = max( FlightSize/2, 2*SMSS ) 在传输过程中,client 和 server 协商接收窗口 rwnd,再结合拥塞控制窗口 cwnd 计算滑动窗口 swnd。 在 Linux 内核实现中,滑动窗口 cwnd 是以包pkt mss为单位,所以在计算 swnd 时需要乘上 mss(最大分段大小) swnd = min(rwnd, cwnd * mss) */ //进入Loss状态 这个函数主要用来标记丢失的段(也就是没有acked的段),然后通过执行slow start来降低传输速率. void tcp_enter_loss(struct sock *sk) { const struct inet_connection_sock *icsk = inet_csk(sk); struct tcp_sock *tp = tcp_sk(sk); struct sk_buff *skb; bool new_recovery = icsk->icsk_ca_state < TCP_CA_Recovery; bool is_reneg; /* is receiver reneging on SACKs? */ /* Reduce ssthresh if it has not yet been made inside this window. */ /* 1 拥塞控制状态小于TCP_CA_Disorder * 2 发送未确认的序列号等于拥塞开始时的下一个将要发送的序列号 * 3 状态为TCP_CA_Loss,并且还未重新传输过。 * 如果有一个满足说明有数据丢失,因此降低threshold。 */ if (icsk->icsk_ca_state <= TCP_CA_Disorder || !after(tp->high_seq, tp->snd_una) || (icsk->icsk_ca_state == TCP_CA_Loss && !icsk->icsk_retransmits)) { /* 保留当前阈值,以便在拥塞窗口调整撤销时使用*/ tp->prior_ssthresh = tcp_current_ssthresh(sk); /* 减小慢启动阈值*/ tp->snd_ssthresh = icsk->icsk_ca_ops->ssthresh(sk); /* 通知CA_EVENT_LOSS事件给具体的拥塞控制算法*/ tcp_ca_event(sk, CA_EVENT_LOSS); tcp_init_undo(tp); } tp->snd_cwnd = 1; /*调整拥塞窗口为1*/ tp->snd_cwnd_cnt = 0;//上次调整拥塞窗口后 到目前位置接收到的总ack段数 tp->snd_cwnd_stamp = tcp_time_stamp;//设置时间 tp->retrans_out = 0; tp->lost_out = 0; if (tcp_is_reno(tp)) tcp_reset_reno_sack(tp);/* 清零sacked_out */ skb = tcp_write_queue_head(sk); is_reneg = skb && (TCP_SKB_CB(skb)->sacked & TCPCB_SACKED_ACKED); if (is_reneg) {/* is receiver reneging on SACKs */ NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_TCPSACKRENEGING); tp->sacked_out = 0; tp->fackets_out = 0; } tcp_clear_all_retrans_hints(tp);//清空所有相关的计数器。 tcp_for_write_queue(skb, sk) {//遍历sk->sk_write_queue发送队列 if (skb == tcp_send_head(sk)) break; //判断sack段。 TCP_SKB_CB(skb)->sacked &= (~TCPCB_TAGBITS)|TCPCB_SACKED_ACKED; //is_reneg为1,则说明不管sack段,此时标记所有的段为丢失 if (!(TCP_SKB_CB(skb)->sacked&TCPCB_SACKED_ACKED) || is_reneg) { TCP_SKB_CB(skb)->sacked &= ~TCPCB_SACKED_ACKED;/*清除SACK标志*/ TCP_SKB_CB(skb)->sacked |= TCPCB_LOST;/*标志为丢失*/ tp->lost_out += tcp_skb_pcount(skb);/*统计丢失段的数量*/ tp->retransmit_high = TCP_SKB_CB(skb)->end_seq; } } tcp_verify_left_out(tp);///*left_out > packets_out则发出警告*/ /* Timeout in disordered state after receiving substantial DUPACKs * suggests that the degree of reordering is over-estimated. */ if (icsk->icsk_ca_state <= TCP_CA_Disorder && tp->sacked_out >= sysctl_tcp_reordering) tp->reordering = min_t(unsigned int, tp->reordering, sysctl_tcp_reordering); tcp_set_ca_state(sk, TCP_CA_Loss); tp->high_seq = tp->snd_nxt; tcp_ecn_queue_cwr(tp); /*表示发送发进入拥塞状态*/ /* F-RTO RFC5682 sec 3.1 step 1: retransmit SND.UNA if no previous * loss recovery is underway except recurring timeout(s) on * the same SND.UNA (sec 3.2). Disable F-RTO on path MTU probing *///如果已经在loss/recovery状态或者网络上有重传包,则收到重传包的ack会导致frto误判,认为超时是spurious tp->frto = sysctl_tcp_frto && (new_recovery || icsk->icsk_retransmits) &&//rto超时前不在recovery状态,或者重传过 !inet_csk(sk)->icsk_mtup.probe_size;//没有在mtu探测 }
伪超时与重传
在很多情况下,即使没有出现数据丢失也可能引发重传。这种不必要的重传称为伪重传,其主要造成原因是伪超时,即过早判定超时,其他因素如包失序、包重复,或 ACK 丢失也可能导致该现象。在实际 RTT 显著增长,超过当前 RTO 时,可能出现伪超时。在下层协议性能变化较大的环境中(如无线环境),这种情况出现得比较多。
TCP 为处理伪超时问题提出了许多方法。这些方法通常包含检测算法与响应算法。检测算法用于判断某个超时或基于计时器的重传是否真实,一旦认定出现伪超时则执行响应算法,用于撤销或减轻该超时带来的影响。 检测算法包含 DSACK 、Eifel 检测算法、迁移 RTO 恢复算法(F-RTO) 三种
DSACK 扩展
DSACK 的主要目的是判断何时的重传是不必要的,并了解网络中的其他事项。通过 DSACK 发送端至少可以推断是否发生了包失序、 ACK 丢失、包重复或伪重传。 D-SACK 使用了 SACK 的第一个段来做标志, a. 如果 SACK 的第一个段的范围被 ACK 所覆盖,那么就是 D-SACK。 b.如果 SACK 的第一个段的范围被 SACK 的第二个段覆盖,那么就是 D-SACK。 RFC2883]没有具体规定发送端对 DSACK 怎样处理。 [RFC3708]给出了一种实验算法,利用 DSACK 来检测伪重传,响应算法可采用 Eifel 响应算法。
Eifel 检测算法 [RFC3522]
实验性的 Eifel 检测算法利用了 TCP 的 TSOPT 来检测伪重传。在发生超时重传后,Eifel 算法等待接收下一个 ACK,若为针对第一次传输(即原始传输)的确认,则判定该重传是伪重传。
与 DSACK 的比较: 利用 Eifel 检测算法能比仅采用 DSACK更早检测到伪重传行为,因为它判断伪重传的 ACK 是在启动丢失恢复之前生成的。相反, DSACK 只有在重复报文段到达接收端后才能发送,并且在 DSACK 返回至发送端后才能有所响应。及早检测伪重传更为有利,它能使发送端有效避免“回退 N”行为。
SACK 重传
- 未启用 SACK 时,TCP 重复 ACK 定义为收到连续相同的 ACK seq。[RFC5681]
- 启用 SACK 时,携带 SACK 的 ACK 也被认为重复 ACK。[RFC6675]
如下图所示(绿色为已发送并且被 ack 的数据包,黄色表示已发送还未确认的数据包,浅绿色为被 Sack 确认的数据包,蓝色表示还未发送的数据包),设 dupthresh = 3,SACKed_count = 6,从 unAcked 包开始的 SACKed_count - dupthresh 个数据包,即 3 个数据包会被标记为 LOST。
dupthresh 是指重复ACK阈值,一定数目的重复ACK,默认通常为3

记分板状态如下,红色表示该数据包丢失:

RACK重传
RACK(Recent ACKnowledgment)是一种新的基于时间的丢包探测算法,RACK的目的是取代传统的基于dupthresh门限的各种快速重传及其变种。
RACK基本思想:如果发送端收到的确认包中的SACK选项确认收到了一个数据包,那么在这个数据包之前发送的数据包要么是在传输过程中发生了乱序,要么是发生了丢包。RACK使用最近投递成功的数据包的发送时刻来推测在这个数据包之前传输的数据包是否已经过期(expired),RACK把这些过期的数据包标记为lost。RACK可以修复丢包而不用等一个比较长的RTO超时,RACK可以用于快速恢复也可以用于超时恢复,既可以利用初传的数据包探测丢包也可以利用重传的数据包探测丢包,而且可以探测初传丢包也可以探测重传丢包,因此RACK是一个适应多种场景的丢包恢复机制。
传统的基于系列号空间的乱序度来探测丢包时,如果发生报文重传,初传报文和重传报文在系列号空间就会重叠。而RACK基于时间的乱序来探测丢包的时候,重传报文和初传报文在时间线上是不重叠的,因此RACK可以同时利用初传报文和重传报文来探测丢包。
RACK使用的需要三个条件:
- 1、TCP连接必须使用SACK选项
- 2、对于每个发送的数据包,发送端必须存储这个数据包的发送时间,时间精度至少要达到毫秒精度。如果连接的RTT小于1ms,那么微秒精度将会更有利于RACK探测丢包。
- 3、对于每个发送出去的数据包,发送端必须存储这个数据包是否已经重传过。
二、RACK算法描述
RACK目前还是一个实验算法,RACK需要使用到的几个状态变量:
- Packet.xmit_ts:数据包上次传输所对应的时间,如果是重传也需要记录这个时间。发送端需要对每个数据包都记录这个时间,且时间精度至少是毫秒
- RACK.xmit_ts:在所有被ack number或者SACK确认的数据包中,最近发送的数据包的Packet.xmit_ts
- RACK.end_seq:上面用于记录RACK.xmit_ts的数据包的终止系列号
- RACK.RTT:上面用于记录RACK.xmit_ts的数据包对应的RTT
- RACK.reo_wnd:表示这个TCP连接的时间乱序度,这个变量的单位是时间。RACK使用这个变量来推测丢包
- RACK.min_RTT:估计的这个连接的最小RTT
注意这些变量的粒度,每个数据包都有一个Packet.xmit_ts变量,每个TCP连接维护一组RACK.xmit_ts, RACK.RTT, RACK.reo_wnd和RACK.min_RTT变量
算法实现:
- 1、当传输一个新的数据包或者重传一个旧的数据包的时候,把当前时间记录在与这个数据包对应的Packet.xmit_ts变量中。
- 2、当接收到一个ACK的时候
Step2.1:根据测量到的RTT更新RACK.min_RTT。
发送端可以使用这个连接的全局最小RTT来维护RACK.min_RTT,也可以使用一个每发送窗口最小RTT的滤波值来维护RACK.min_RTT。
Step2.2:更新RACK.reo_wnd。RACK.reo_wnd默认值为1ms,当探测到包乱序的时候可以设置RACK.reo_wnd=RACK.min_RTT/4
Step2.3:更新RACK.xmit_ts、RACK.RTT 和 RACK.end_seq。
首先在这个ACK新确认的数据包(包括通过ack number和SACK确认的数据包)中排除下面两类重传数据包
1、如果这个数据包中的TSecr指示这个确认包并不是确认的重传数据包。这个实际上是Eifel探测算法。
2、这个数据包上次重传时间距离当前时间小于RACK.min_rtt。这个也意味着这个数据包多半是虚假重传。
接着在剩余的新确认的数据包中找出最近发送的数据包的Packet.xmit_ts,
如果Packet.xmit_ts比RACK.xmit_ts在时间上更靠后,那么更新RACK.xmit_ts = Packet.xmit_ts。
如果RACK.xmit_ts发生了更新,那么更新RACK.RTT = Now() - RACK.xmit_ts,RACK.end_seq = Packet.end_seq。
如果RACK.xmit_ts没有更新,那么退出针对这个确认包的RACK处理流程,不再执行下面的丢包探测过程。
- Step2.4:丢包探测
对于每个还没有被SACK完全确认的数据包,如果在时间上RACK.xmit_ts比Packet.xmit_ts + RACK.reo_wnd更靠后,说明这个数据包已经超过预计的时间乱序度,标记这个数据包为lost状态。另外对于未被标记为lost的数据包,发送端可以等待下次收到ACK确认包的时候再次进行RACK标记处理, 也可以设置一个"reordering settling"定时器,以待定时器超时的时候把这个数据包标记为lost。设置定时器的方法可以防止大量丢包或者应用层发送数据受限而造成RTO超时。定时器的超时时间协议给出的是timeout = Packet.xmit_ts + RACK.RTT + RACK.reo_wnd + 1。
这里值得一提的是,RACK功能可以很好的与TLP功能配合,因为RACK可以使用重传包来探测丢包,因此TLP其实可以发送第一个未被确认的数据包来进行丢包探测,这样就可以应用层传输时延。
拥塞控制
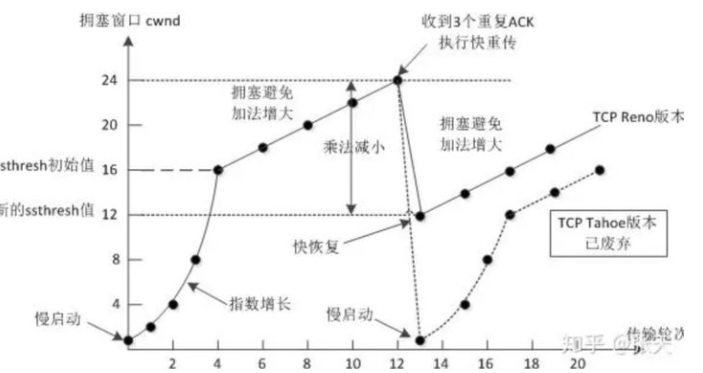
拥塞的发生是因为路由器缓存溢出,拥塞会导致丢包,但丢包不一定触发拥塞。拥塞控制是快速传输的基础。一个拥塞控制算法一般包括慢启动算法、拥塞避免算法、快速重传算法、快速恢复算法四部分。