并发(concurrency)和并行(parallelism)
前者是逻辑上的同时发生(simultaneous),而后者是物理上的同时发生;
- 并发性(concurrency),又称共行性,是指能处理多个同时性活动的能力,并发事件之间不一定要同一时刻发生。
- 并行(parallelism)是指同时发生的两个并发事件,具有并发的含义,而并发则不一定并行
并发指的是程序的“结构”;正确的并发设计的标准是:使多个操作可以在重叠的时间段内进行(two tasks can start, run, and complete in overlapping time periods)。所以并发执行就是指:指多个操作可以在重叠的时间段内进行;如下图所示:
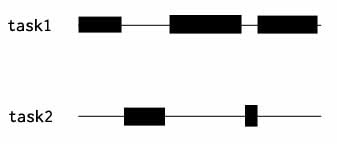
并行,就是同时执行的意思;判断程序是否处于并行的状态,就看同一时刻是否有超过一个“工作单位”在运行就好了。所以,单线程永远无法达到并行状态。
concurrency-is-not-parallelism :Different concurrent designs enable different ways to parallelize. 并发设计让并发执行成为可能,而并行是并发执行的一种模式。
go 并发的机制
go的并发机制是指支撑goroutine 的channel的底层原理;
go并发的时候肯定会涉及到调度问题;目前Thread很大程度上是对Unix process进场模型的一个逻辑描述和扩展;Thread有自己的信号掩码,CPU affinity等。但是很多特征对于Go程序来说都是累赘。 尤其是context上下文切换的耗时。另一个原因是Go的垃圾回收需要所有的goroutine停止,使得内存在一个一致的状态。垃圾回收的时间点是不确定的,如果依靠OS自身的scheduler来调度,那么会有大量的线程需要停止工作。
单独的开发一个Go的调度器,其是知道在什么时候内存状态是一致的,即当开始垃圾回收时,运行时只需要为当时正在CPU核上运行的那个线程等待即可,而不是让所有的线程等待
用户空间线程和内核空间线程之间的映射关系有:N:1、1:1和M:N
- N:1是说,多个(N)用户线程始终在一个内核线程上跑,context上下文切换确实很快,但是无法真正的利用多核。
- 1:1是说,一个用户线程就只在一个内核线程上跑,这时可以利用多核,但是上下文switch很慢。
- M:N是说, 多个goroutine在多个内核线程上跑,这个看似可以集齐上面两者的优势,但是无疑增加了调度的难度。
go的线程模型:goroutine 看做是go特有的应用层线程-->go 协程;go的线程模型有几个概念M,P,G
M:machine 一个M代表一个内核线程,或者叫做工作线程
P:processor 一个P代表一个go 代码片段所必须的资源,或者称为上下文环境;可以把它看做一个局部的调度器,使go代码在一个线程上跑,它是实现从N:1到N:M映射的关键
G:goroutine 一个G代表一个go代码片段,它有自己的栈,instruction pointer和其他信息(正在等待的channel等等),用于调度
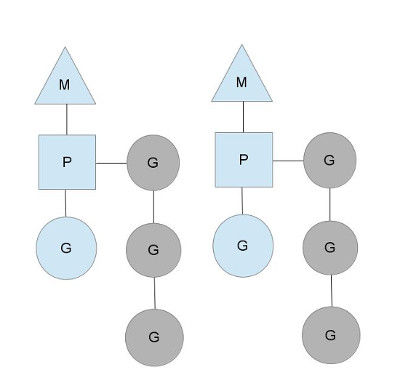
图中看,有2个物理线程M,每一个M都拥有一个context(P),每一个也都有一个正在运行的goroutine。P的数量可以通过runtime.GOMAXPROCS()来设置,它其实也就代表了真正的并发度,即有多少个goroutine可以同时运行。图中灰色的那些goroutine并没有运行,而是出于ready的就绪态,正在等待被调度。P维护着这个队列(称之为runqueue),Go语言里,启动一个goroutine很容易:go function 就行,所以每有一个go语句被执行,runqueue队列就在其末尾加入一个goroutine,在下一个调度点,就从runqueue中取出(如何决定取哪个goroutine?)一个goroutine执行
为何要维护多个上下文P?因为当一个OS线程被阻塞时,P可以转而投奔另一个OS线程!
图中看到,当一个OS线程M0陷入阻塞时,P转而在OS线程M1上运行。调度器保证有足够的线程来运行所有的context P。
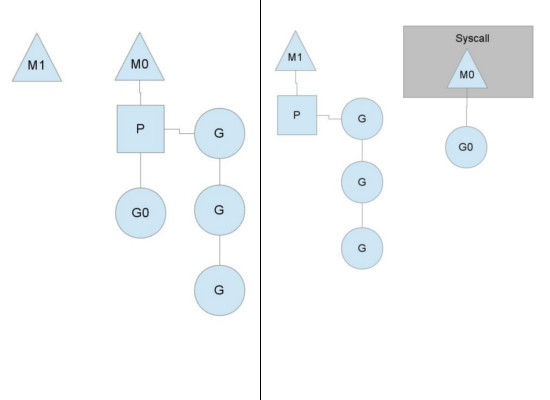 阻塞系统调用(如打开文件),goroutine 会从逻辑处理器上分离,线程继续阻塞,等待调用返回。调度器创建一个新的线程,继续绑定到该逻辑处理器上,然后调度器从本地队列中选择另一个 goroutine 来运行。一旦被阻塞的系统调用执行完成并返回,对应的 goroutine 会放回本地本地运行队列,之前的线程被保存好,以便之后可以继续使用。
阻塞系统调用(如打开文件),goroutine 会从逻辑处理器上分离,线程继续阻塞,等待调用返回。调度器创建一个新的线程,继续绑定到该逻辑处理器上,然后调度器从本地队列中选择另一个 goroutine 来运行。一旦被阻塞的系统调用执行完成并返回,对应的 goroutine 会放回本地本地运行队列,之前的线程被保存好,以便之后可以继续使用。
LIST:
Go 中并发的基本单元 Goroutine 存在于用户空间,其并不是由操作系统调度(Go 有自己的调度器),总之,Goroutine 比线程更加的轻量,其调度也非常高效,这便是 Go 高并发的重要原因。
Go 语言并发模型中的 M 其实表示的是操作系统线程
在默认情况下,runtime.GOMAXPROCS= CPU_NR数;也就是 #thread == #CPU,在这种情况下不会触发操作系统级别的线程调度和上下文切换,所有的调度都会发生在用户态,由 Go 语言调度器触发,能够减少非常多的额外开销。
runtime.GOMAXPROCS 方法用来改变当前程序中最大的线程数。
操作系统线程在 Go 语言中就会使用私有结构体 m 来表示,这个结构体中也包含了几十个私有的字段,目前只看一部分
type m struct { g0 *g // goroutine with scheduling stack curg *g // current running goroutine ... }
其中 g0 是持有调度堆栈的 Goroutine,curg 是在当前线程上运行的 Goroutine,这也是作为操作系统线程唯一关心的两个 Goroutine 了。
P是G能够在M 中运行的关键。Go的运行时系统会适时的让P与不同的M建立或者断开关联,以便让P中那些课运行的G获得及时运行的机会,这个和os的内核在CPU之上实时的切换不同进程线程一样。。。
P的结构体以及状态有:见runtime2.go 文件


type p struct { id int32 status uint32 // one of pidle/prunning/... link puintptr schedtick uint32 // incremented on every scheduler call syscalltick uint32 // incremented on every system call sysmontick sysmontick // last tick observed by sysmon m muintptr // back-link to associated m (nil if idle) mcache *mcache pcache pageCache raceprocctx uintptr deferpool [5][]*_defer // pool of available defer structs of different sizes (see panic.go) deferpoolbuf [5][32]*_defer // Cache of goroutine ids, amortizes accesses to runtime·sched.goidgen. goidcache uint64 goidcacheend uint64 // Queue of runnable goroutines. Accessed without lock. runqhead uint32 runqtail uint32 runq [256]guintptr // runnext, if non-nil, is a runnable G that was ready'd by // the current G and should be run next instead of what's in // runq if there's time remaining in the running G's time // slice. It will inherit the time left in the current time // slice. If a set of goroutines is locked in a // communicate-and-wait pattern, this schedules that set as a // unit and eliminates the (potentially large) scheduling // latency that otherwise arises from adding the ready'd // goroutines to the end of the run queue. // // Note that while other P's may atomically CAS this to zero, // only the owner P can CAS it to a valid G. runnext guintptr // Available G's (status == Gdead) gFree struct { gList n int32 } sudogcache []*sudog sudogbuf [128]*sudog // Cache of mspan objects from the heap. mspancache struct { // We need an explicit length here because this field is used // in allocation codepaths where write barriers are not allowed, // and eliminating the write barrier/keeping it eliminated from // slice updates is tricky, moreso than just managing the length // ourselves. len int buf [128]*mspan } tracebuf traceBufPtr // traceSweep indicates the sweep events should be traced. // This is used to defer the sweep start event until a span // has actually been swept. traceSweep bool // traceSwept and traceReclaimed track the number of bytes // swept and reclaimed by sweeping in the current sweep loop. traceSwept, traceReclaimed uintptr palloc persistentAlloc // per-P to avoid mutex _ uint32 // Alignment for atomic fields below // The when field of the first entry on the timer heap. // This is updated using atomic functions. // This is 0 if the timer heap is empty. timer0When uint64 // The earliest known nextwhen field of a timer with // timerModifiedEarlier status. Because the timer may have been // modified again, there need not be any timer with this value. // This is updated using atomic functions. // This is 0 if there are no timerModifiedEarlier timers. timerModifiedEarliest uint64 // Per-P GC state gcAssistTime int64 // Nanoseconds in assistAlloc gcFractionalMarkTime int64 // Nanoseconds in fractional mark worker (atomic) // gcMarkWorkerMode is the mode for the next mark worker to run in. // That is, this is used to communicate with the worker goroutine // selected for immediate execution by // gcController.findRunnableGCWorker. When scheduling other goroutines, // this field must be set to gcMarkWorkerNotWorker. gcMarkWorkerMode gcMarkWorkerMode // gcMarkWorkerStartTime is the nanotime() at which the most recent // mark worker started. gcMarkWorkerStartTime int64 // gcw is this P's GC work buffer cache. The work buffer is // filled by write barriers, drained by mutator assists, and // disposed on certain GC state transitions. gcw gcWork // wbBuf is this P's GC write barrier buffer. // // TODO: Consider caching this in the running G. wbBuf wbBuf runSafePointFn uint32 // if 1, run sched.safePointFn at next safe point // statsSeq is a counter indicating whether this P is currently // writing any stats. Its value is even when not, odd when it is. statsSeq uint32 // Lock for timers. We normally access the timers while running // on this P, but the scheduler can also do it from a different P. timersLock mutex // Actions to take at some time. This is used to implement the // standard library's time package. // Must hold timersLock to access. timers []*timer // Number of timers in P's heap. // Modified using atomic instructions. numTimers uint32 // Number of timerDeleted timers in P's heap. // Modified using atomic instructions. deletedTimers uint32 // Race context used while executing timer functions. timerRaceCtx uintptr // preempt is set to indicate that this P should be enter the // scheduler ASAP (regardless of what G is running on it). preempt bool // Padding is no longer needed. False sharing is now not a worry because p is large enough // that its size class is an integer multiple of the cache line size (for any of our architectures). }
const ( // P status // _Pidle means a P is not being used to run user code or the // scheduler. Typically, it's on the idle P list and available // to the scheduler, but it may just be transitioning between // other states. // // The P is owned by the idle list or by whatever is // transitioning its state. Its run queue is empty. _Pidle = iota // _Prunning means a P is owned by an M and is being used to // run user code or the scheduler. Only the M that owns this P // is allowed to change the P's status from _Prunning. The M // may transition the P to _Pidle (if it has no more work to // do), _Psyscall (when entering a syscall), or _Pgcstop (to // halt for the GC). The M may also hand ownership of the P // off directly to another M (e.g., to schedule a locked G). _Prunning // _Psyscall means a P is not running user code. It has // affinity to an M in a syscall but is not owned by it and // may be stolen by another M. This is similar to _Pidle but // uses lightweight transitions and maintains M affinity. // // Leaving _Psyscall must be done with a CAS, either to steal // or retake the P. Note that there's an ABA hazard: even if // an M successfully CASes its original P back to _Prunning // after a syscall, it must understand the P may have been // used by another M in the interim. _Psyscall // _Pgcstop means a P is halted for STW and owned by the M // that stopped the world. The M that stopped the world // continues to use its P, even in _Pgcstop. Transitioning // from _Prunning to _Pgcstop causes an M to release its P and // park. // // The P retains its run queue and startTheWorld will restart // the scheduler on Ps with non-empty run queues. _Pgcstop // _Pdead means a P is no longer used (GOMAXPROCS shrank). We // reuse Ps if GOMAXPROCS increases. A dead P is mostly // stripped of its resources, though a few things remain // (e.g., trace buffers). _Pdead )
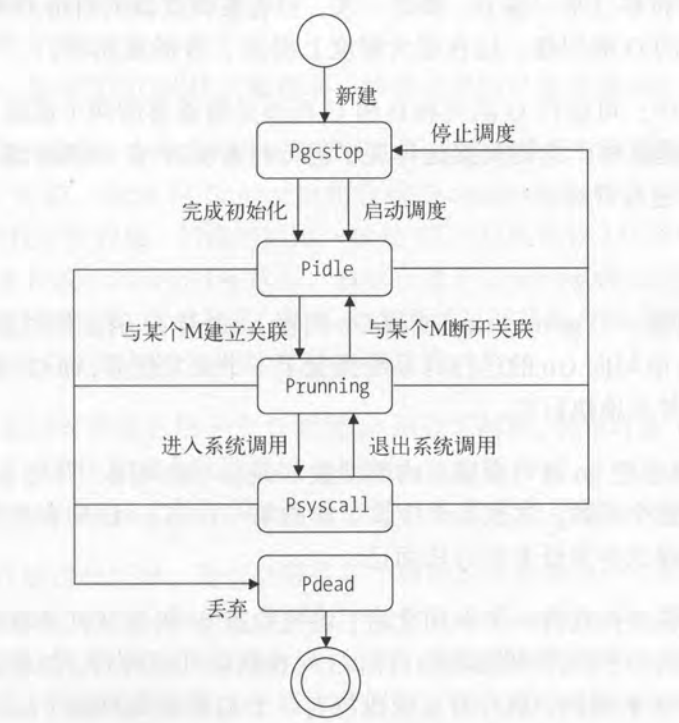
p 结构体中的状态 status 会是以下五种状态其中的一种
| 状态 | 描述 |
|---|---|
| _Pidle | 处理器没有运行用户代码或者调度器,被空闲队列或者改变其状态的结构持有,运行队列为空 |
| _Prunning | 被线程 M 持有,并且正在执行用户代码或者调度器 |
| _Psyscall |
当前p没有执行用户代码,运行的那个G正在执行系统调用导致当前线程陷入系统调用 |
| _Pgcstop | 被线程 M 持有,此时应该停止调度,比如当前处理器由于垃圾回收被停止 |
| _Pdead |
当前处理器已经不被使用;比如通过runtime.gomaxprocs 函数减少了P的最大数量, 多余的P就会被运行是的系统设置为此状态 |

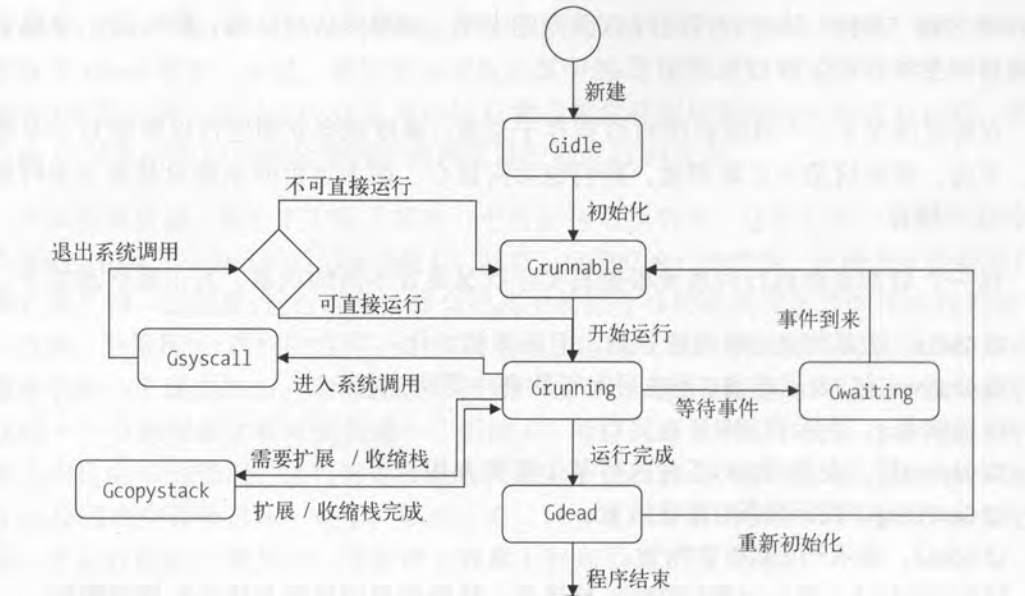
G的状态
Goroutine在生命周期的不断的阶段,会有不同的G状态。而通过分析G的状态,有助于我们了解Goroutine的调度
- idle, runnable, running, syscall, waiting, dead, copystack六种非GC状态,
- 以及scan, scanrunnable, scan running, scansyscall, scanwaiting六种对应的GC状态
- _Gidle for idle,意思是这个goroutine刚被创建出来,还未被进行初始化。因为它的值为0,所以刚被创建出来的g对象都是_Gidle。但在runtime库仅有的两处调用中,创建出来的g都马上被赋值为_Gdead,这是为了g在添加到被GC观察之前,用于躲避trackbacks和stack scan,因为这个g对象在必要的处理前,还不是一个真正的goroutine。
- _Grunnable for runnable,意思是这个goroutine已经在运行队列,在这种情况下,goroutine还未执行用户代码,M的执行栈还不是goroutine自己的。
- _Grunning for running,意思是goroutine可能正在执行用户代码,M的执行栈已经由该goroutine所拥有,此时对象g不在运行队列中。这个状态值要待分配给M和P之后,交由M和P来设定。
- _Gsyscall for system scall,意思是这个goroutine正在执行系统调用,而不是正在执行用户代码。和_Grunning一样,goroutine拥有了执行栈,也不在运行队列中。这个状态值只能由分配给的M来设定。
- _Gwaiting for waiting,意思是goroutine在运行时被阻塞,它既不执 行用户代码,也不在运行队列。它被记录在其它的地方,例如管道等待队列——channel wait queue,因此当需要该goroutine的时候,该goroutine可以马上就绪,这也是goroutine和channel的底层实现方式。这个时候,执行栈不被该g对象所拥有,除非一个管道正在做读或者写执行栈里面数据的操作。除了以上这类型的情况,在一个goroutine进入_Gwaiting之后尝试获取其执行栈,都是不安全的。
- _Gdead for dead,意思是这个goroutine在当前不被使用,这种情况可能是goroutine刚被创建出来,或者已经执行完毕退出并被放到释放列表中。当一个G执行完毕并正在退出时,和G被添加到释放列表时,G和G的执行栈都是M所拥有的。
- _Gcopystack for copy stack,意思是这个goroutine的执行栈已经被移动,这个goroutine即不执行用户代码,也不在运行队列。这种状态是_Grunning的时候,出现了执行栈空间不足或者过大,需要扩容或者GC的情况下发生,是进行执行栈扩容或者收缩时的中间状态。
- _Gscan系列,用于标记正在被GC扫描的状态,这些状态是由_Gscan=0x1000再加上_GRunnable, _Grunning, _Gsyscall和_Gwaiting的枚举值所产生的,这么做的好处是直接通过简单的运算即可知道被Scan之前的状态。当被标记为这系列的状态时,这些goroutine都不会执行用户代码,并且它们的执行栈都是被做该GC的goroutine所拥有。不过_Gscanrunning状态有点特别,这个标记是为了阻止正在运行的goroutine切换成其它状态,并告诉这个G自己扫描自己的堆栈。正是这种巧妙的方式,使得Go语言的GC十分高效
创建 Goroutine
想要启动一个新的 Goroutine 来执行任务时,我们需要使用 Go 语言中的 go 关键字,这个关键字会在编译期间通过以下方法 stmt 和 call 两个方法将该关键字转换成 newproc 函数调用,代码的路径和原理与 defer 关键字几乎完全相同,两者的区别也只是 defer 被转化成 deferproc 而 go 被转换成 newproc 方法:
func (s *state) stmt(n *Node) { switch n.Op { case OGO: s.call(n.Left, callGo) } } func (s *state) call(n *Node, k callKind) *ssa.Value { // ... if k == callDeferStack { // ... } else { switch { case k == callGo: call = s.newValue1A(ssa.OpStaticCall, types.TypeMem, newproc, s.mem()) default: } } // ... return ... }
所有的 go 关键字都会被转换成 newproc 函数调用,我们向 newproc 中传入一个表示函数的指针 funcval,在这个函数中我们还会获取当前调用 newproc 函数的 Goroutine 以及调用方的程序计数器 PC,然后调用 newproc1 函数:
func newproc(siz int32, fn *funcval) { argp := add(unsafe.Pointer(&fn), sys.PtrSize) gp := getg() pc := getcallerpc() newproc1(fn, (*uint8)(argp), siz, gp, pc) }
newproc1 函数的主要作用就是创建一个运行传入参数 fn 的 g 结构体,在这个方法中我们也会拷贝当前方法的全部参数,argp 和 narg 共同表示函数 fn 的入参,我们在该方法中其实也会直接将所有参数对应的内存空间整片的拷贝到新 Goroutine 的栈上。
// Create a new g in state _Grunnable, starting at fn, with narg bytes // of arguments starting at argp. callerpc is the address of the go // statement that created this. The caller is responsible for adding // the new g to the scheduler. // // This must run on the system stack because it's the continuation of // newproc, which cannot split the stack. // //go:systemstack func newproc1(fn *funcval, argp unsafe.Pointer, narg int32, callergp *g, callerpc uintptr) *g { if goexperiment.RegabiDefer && narg != 0 { // TODO: When we commit to GOEXPERIMENT=regabidefer, // rewrite the comments for newproc and newproc1. // newproc will no longer have a funny stack layout or // need to be nosplit. throw("go with non-empty frame") } _g_ := getg() if fn == nil { _g_.m.throwing = -1 // do not dump full stacks throw("go of nil func value") } acquirem() // disable preemption because it can be holding p in a local var siz := narg siz = (siz + 7) &^ 7 // We could allocate a larger initial stack if necessary. // Not worth it: this is almost always an error. // 4*PtrSize: extra space added below // PtrSize: caller's LR (arm) or return address (x86, in gostartcall). if siz >= _StackMin-4*sys.PtrSize-sys.PtrSize { throw("newproc: function arguments too large for new goroutine") } _p_ := _g_.m.p.ptr() newg := gfget(_p_) if newg == nil { newg = malg(_StackMin) casgstatus(newg, _Gidle, _Gdead) allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack. } if newg.stack.hi == 0 { throw("newproc1: newg missing stack") } if readgstatus(newg) != _Gdead { throw("newproc1: new g is not Gdead") } totalSize := 4*sys.PtrSize + uintptr(siz) + sys.MinFrameSize // extra space in case of reads slightly beyond frame totalSize += -totalSize & (sys.StackAlign - 1) // align to StackAlign sp := newg.stack.hi - totalSize spArg := sp if usesLR { // caller's LR *(*uintptr)(unsafe.Pointer(sp)) = 0 prepGoExitFrame(sp) spArg += sys.MinFrameSize } if narg > 0 { memmove(unsafe.Pointer(spArg), argp, uintptr(narg)) // This is a stack-to-stack copy. If write barriers // are enabled and the source stack is grey (the // destination is always black), then perform a // barrier copy. We do this *after* the memmove // because the destination stack may have garbage on // it. if writeBarrier.needed && !_g_.m.curg.gcscandone { f := findfunc(fn.fn) stkmap := (*stackmap)(funcdata(f, _FUNCDATA_ArgsPointerMaps)) if stkmap.nbit > 0 { // We're in the prologue, so it's always stack map index 0. bv := stackmapdata(stkmap, 0) bulkBarrierBitmap(spArg, spArg, uintptr(bv.n)*sys.PtrSize, 0, bv.bytedata) } } } memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched)) newg.sched.sp = sp newg.stktopsp = sp newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function newg.sched.g = guintptr(unsafe.Pointer(newg)) gostartcallfn(&newg.sched, fn) newg.gopc = callerpc newg.ancestors = saveAncestors(callergp) newg.startpc = fn.fn if _g_.m.curg != nil { newg.labels = _g_.m.curg.labels } if isSystemGoroutine(newg, false) { atomic.Xadd(&sched.ngsys, +1) } // Track initial transition? newg.trackingSeq = uint8(fastrand()) if newg.trackingSeq%gTrackingPeriod == 0 { newg.tracking = true } casgstatus(newg, _Gdead, _Grunnable) if _p_.goidcache == _p_.goidcacheend { // Sched.goidgen is the last allocated id, // this batch must be [sched.goidgen+1, sched.goidgen+GoidCacheBatch]. // At startup sched.goidgen=0, so main goroutine receives goid=1. _p_.goidcache = atomic.Xadd64(&sched.goidgen, _GoidCacheBatch) _p_.goidcache -= _GoidCacheBatch - 1 _p_.goidcacheend = _p_.goidcache + _GoidCacheBatch } newg.goid = int64(_p_.goidcache) _p_.goidcache++ if raceenabled { newg.racectx = racegostart(callerpc) } if trace.enabled { traceGoCreate(newg, newg.startpc) } releasem(_g_.m) return
// Create a new g running fn with siz bytes of arguments. // Put it on the queue of g's waiting to run. // The compiler turns a go statement into a call to this. // // The stack layout of this call is unusual: it assumes that the // arguments to pass to fn are on the stack sequentially immediately // after &fn. Hence, they are logically part of newproc's argument // frame, even though they don't appear in its signature (and can't // because their types differ between call sites). // // This must be nosplit because this stack layout means there are // untyped arguments in newproc's argument frame. Stack copies won't // be able to adjust them and stack splits won't be able to copy them. // //go:nosplit func newproc(siz int32, fn *funcval) { argp := add(unsafe.Pointer(&fn), sys.PtrSize) gp := getg() pc := getcallerpc() systemstack(func() { newg := newproc1(fn, argp, siz, gp, pc) _p_ := getg().m.p.ptr() runqput(_p_, newg, true) if mainStarted { wakep() } }) } // Create a new g in state _Grunnable, starting at fn, with narg bytes // of arguments starting at argp. callerpc is the address of the go // statement that created this. The caller is responsible for adding // the new g to the scheduler. // // This must run on the system stack because it's the continuation of // newproc, which cannot split the stack. // //go:systemstack func newproc1(fn *funcval, argp unsafe.Pointer, narg int32, callergp *g, callerpc uintptr) *g { if goexperiment.RegabiDefer && narg != 0 { // TODO: When we commit to GOEXPERIMENT=regabidefer, // rewrite the comments for newproc and newproc1. // newproc will no longer have a funny stack layout or // need to be nosplit. throw("go with non-empty frame") } _g_ := getg() if fn == nil { _g_.m.throwing = -1 // do not dump full stacks throw("go of nil func value") } acquirem() // disable preemption because it can be holding p in a local var siz := narg siz = (siz + 7) &^ 7 // We could allocate a larger initial stack if necessary. // Not worth it: this is almost always an error. // 4*PtrSize: extra space added below // PtrSize: caller's LR (arm) or return address (x86, in gostartcall). if siz >= _StackMin-4*sys.PtrSize-sys.PtrSize { throw("newproc: function arguments too large for new goroutine") } _p_ := _g_.m.p.ptr() newg := gfget(_p_) if newg == nil { newg = malg(_StackMin) casgstatus(newg, _Gidle, _Gdead) allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack. } if newg.stack.hi == 0 { throw("newproc1: newg missing stack") } if readgstatus(newg) != _Gdead { throw("newproc1: new g is not Gdead") } totalSize := 4*sys.PtrSize + uintptr(siz) + sys.MinFrameSize // extra space in case of reads slightly beyond frame totalSize += -totalSize & (sys.StackAlign - 1) // align to StackAlign sp := newg.stack.hi - totalSize spArg := sp if usesLR { // caller's LR *(*uintptr)(unsafe.Pointer(sp)) = 0 prepGoExitFrame(sp) spArg += sys.MinFrameSize } if narg > 0 { memmove(unsafe.Pointer(spArg), argp, uintptr(narg)) // This is a stack-to-stack copy. If write barriers // are enabled and the source stack is grey (the // destination is always black), then perform a // barrier copy. We do this *after* the memmove // because the destination stack may have garbage on // it. if writeBarrier.needed && !_g_.m.curg.gcscandone { f := findfunc(fn.fn) stkmap := (*stackmap)(funcdata(f, _FUNCDATA_ArgsPointerMaps)) if stkmap.nbit > 0 { // We're in the prologue, so it's always stack map index 0. bv := stackmapdata(stkmap, 0) bulkBarrierBitmap(spArg, spArg, uintptr(bv.n)*sys.PtrSize, 0, bv.bytedata) } } } memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched)) newg.sched.sp = sp newg.stktopsp = sp newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function newg.sched.g = guintptr(unsafe.Pointer(newg)) gostartcallfn(&newg.sched, fn) newg.gopc = callerpc newg.ancestors = saveAncestors(callergp) newg.startpc = fn.fn if _g_.m.curg != nil { newg.labels = _g_.m.curg.labels } if isSystemGoroutine(newg, false) { atomic.Xadd(&sched.ngsys, +1) } // Track initial transition? newg.trackingSeq = uint8(fastrand()) if newg.trackingSeq%gTrackingPeriod == 0 { newg.tracking = true } casgstatus(newg, _Gdead, _Grunnable) if _p_.goidcache == _p_.goidcacheend { // Sched.goidgen is the last allocated id, // this batch must be [sched.goidgen+1, sched.goidgen+GoidCacheBatch]. // At startup sched.goidgen=0, so main goroutine receives goid=1. _p_.goidcache = atomic.Xadd64(&sched.goidgen, _GoidCacheBatch) _p_.goidcache -= _GoidCacheBatch - 1 _p_.goidcacheend = _p_.goidcache + _GoidCacheBatch } newg.goid = int64(_p_.goidcache) _p_.goidcache++ if raceenabled { newg.racectx = racegostart(callerpc) } if trace.enabled { traceGoCreate(newg, newg.startpc) } releasem(_g_.m) return newg }
newproc1 函数的执行过程其实可以分成以下的几个步骤:
-
获取当前 Goroutine 对应的处理器 P 并从它的列表中取出一个空闲的 Goroutine,如果当前不存在空闲的 Goroutine,就会通过
malg方法重新分配一个g结构体并将它的状态从_Gidle转换成_Gdead; -
获取新创建 Goroutine 的堆栈并直接通过
memmove将函数fn需要的参数全部拷贝到栈中; -
初始化新 Goroutine 的栈指针、程序计数器、调用方程序计数器等属性;
-
将新 Goroutine 的状态从
_Gdead切换成_Grunnable并设置 Goroutine 的标识符(goid); -
runqput函数会将新的 Goroutine 添加到处理器 P 的结构体中; -
如果符合条件,当前函数会通过
wakep来添加一个新的p结构体来执行 Goroutine;
在这个过程中我们会有两种不同的方法获取一个新的 g 结构体,一种情况是直接从当前 Goroutine 所在处理器的 _p_.gFree 列表或者调度器的 sched.gFree 列表中获取 g 结构体,另一种方式就是通过 malg 方法生成一个新的 g 结构体并将当前结构体追加到全局的 Goroutine 列表 allgs 中;
调用 malg 方法初始化一个新的 g 结构体,如果申请的堆栈大小大于 0,在这里我们就会通过 stackalloc 初始化一片栈空间:
// Allocate a new g, with a stack big enough for stacksize bytes. func malg(stacksize int32) *g { newg := new(g) if stacksize >= 0 { stacksize = round2(_StackSystem + stacksize) systemstack(func() { newg.stack = stackalloc(uint32(stacksize)) }) newg.stackguard0 = newg.stack.lo + _StackGuard newg.stackguard1 = ^uintptr(0) // Clear the bottom word of the stack. We record g // there on gsignal stack during VDSO on ARM and ARM64. *(*uintptr)(unsafe.Pointer(newg.stack.lo)) = 0 } return newg }
新创建的 Goroutine 在大多数情况下都可以通过调用 runqput 函数将当前 Goroutine 添加到处理器 P 的运行队列上,该运行队列是一个使用数组构成的环形链表,其中最多能够存储 256 个指向 Goroutine 的指针,除了 runq 中能够存储待执行的 Goroutine 之外,runnext 指针中也可以存储 Goroutine,runnext 指向的 Goroutine 会成为下一个被运行的 Goroutine
/ runqput tries to put g on the local runnable queue. // If next is false, runqput adds g to the tail of the runnable queue. // If next is true, runqput puts g in the _p_.runnext slot. // If the run queue is full, runnext puts g on the global queue. // Executed only by the owner P. func runqput(_p_ *p, gp *g, next bool) { if randomizeScheduler && next && fastrand()%2 == 0 { next = false } if next { retryNext: oldnext := _p_.runnext if !_p_.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) { goto retryNext } if oldnext == 0 { return } // Kick the old runnext out to the regular run queue. gp = oldnext.ptr() } retry: h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with consumers t := _p_.runqtail if t-h < uint32(len(_p_.runq)) { _p_.runq[t%uint32(len(_p_.runq))].set(gp) atomic.StoreRel(&_p_.runqtail, t+1) // store-release, makes the item available for consumption return } if runqputslow(_p_, gp, h, t) { return } // the queue is not full, now the put above must succeed goto retry }
-
当
next=true时将 Goroutine 设置到处理器的runnext上作为下一个被当前处理器执行的 Goroutine; -
当
next=false并且运行队列还有剩余空间时,将 Goroutine 加入处理器持有的本地运行队列; -
当处理器的本地运行队列已经没有剩余空间时就会把本地队列中的一部分 Goroutine 和待加入的 Goroutine 通过
runqputslow添加到调度器持有的全局运行队列上;
Go 语言中有两个运行队列,其中一个是处理器本地的运行队列,另一个是调度器持有的全局运行队列,只有在本地运行队列没有剩余空间时才会使用全局队列存储 Goroutine
Goroutine 调度
在 Go 语言程序的运行期间,所有触发 Goroutine 调度的方式最终都会调用 gopark 函数让出当前处理器 P 的控制权,gopark 函数中会更新当前处理器的状态并在处理器上设置该 Goroutine 的等待原因:
// Puts the current goroutine into a waiting state and calls unlockf on the // system stack. // // If unlockf returns false, the goroutine is resumed. // // unlockf must not access this G's stack, as it may be moved between // the call to gopark and the call to unlockf. // // Note that because unlockf is called after putting the G into a waiting // state, the G may have already been readied by the time unlockf is called // unless there is external synchronization preventing the G from being // readied. If unlockf returns false, it must guarantee that the G cannot be // externally readied. // // Reason explains why the goroutine has been parked. It is displayed in stack // traces and heap dumps. Reasons should be unique and descriptive. Do not // re-use reasons, add new ones. func gopark(unlockf func(*g, unsafe.Pointer) bool, lock unsafe.Pointer, reason waitReason, traceEv byte, traceskip int) { if reason != waitReasonSleep { checkTimeouts() // timeouts may expire while two goroutines keep the scheduler busy } mp := acquirem() gp := mp.curg status := readgstatus(gp) if status != _Grunning && status != _Gscanrunning { throw("gopark: bad g status") } mp.waitlock = lock mp.waitunlockf = unlockf gp.waitreason = reason mp.waittraceev = traceEv mp.waittraceskip = traceskip releasem(mp) // can't do anything that might move the G between Ms here. mcall(park_m) }
// park continuation on g0. func park_m(gp *g) { _g_ := getg() if trace.enabled { traceGoPark(_g_.m.waittraceev, _g_.m.waittraceskip) } casgstatus(gp, _Grunning, _Gwaiting) dropg() if fn := _g_.m.waitunlockf; fn != nil { ok := fn(gp, _g_.m.waitlock) _g_.m.waitunlockf = nil _g_.m.waitlock = nil if !ok { if trace.enabled { traceGoUnpark(gp, 2) } casgstatus(gp, _Gwaiting, _Grunnable) execute(gp, true) // Schedule it back, never returns. } } schedule() }
调用的 park_m 函数会将当前 Goroutine 的状态从 _Grunning 切换至 _Gwaiting 并调用 waitunlockf 函数进行解锁,如果解锁失败就会将该 Goroutine 的状态切换回 _Grunning 并重新执行:
在大多数情况下都会调用 schedule 触发一次 Goroutine 调度,这个函数的主要作用就是从不同的地方查找待执行的 Goroutine:
// One round of scheduler: find a runnable goroutine and execute it. // Never returns. func schedule() { _g_ := getg() if _g_.m.locks != 0 { throw("schedule: holding locks") } if _g_.m.lockedg != 0 { stoplockedm() execute(_g_.m.lockedg.ptr(), false) // Never returns. } // We should not schedule away from a g that is executing a cgo call, // since the cgo call is using the m's g0 stack. if _g_.m.incgo { throw("schedule: in cgo") } top: pp := _g_.m.p.ptr() pp.preempt = false if sched.gcwaiting != 0 { gcstopm() goto top } if pp.runSafePointFn != 0 { runSafePointFn() } // Sanity check: if we are spinning, the run queue should be empty. // Check this before calling checkTimers, as that might call // goready to put a ready goroutine on the local run queue. if _g_.m.spinning && (pp.runnext != 0 || pp.runqhead != pp.runqtail) { throw("schedule: spinning with local work") } checkTimers(pp, 0) var gp *g var inheritTime bool // Normal goroutines will check for need to wakeP in ready, // but GCworkers and tracereaders will not, so the check must // be done here instead. tryWakeP := false if trace.enabled || trace.shutdown { gp = traceReader() if gp != nil { casgstatus(gp, _Gwaiting, _Grunnable) traceGoUnpark(gp, 0) tryWakeP = true } } if gp == nil && gcBlackenEnabled != 0 { gp = gcController.findRunnableGCWorker(_g_.m.p.ptr()) if gp != nil { tryWakeP = true } } if gp == nil { // Check the global runnable queue once in a while to ensure fairness. // Otherwise two goroutines can completely occupy the local runqueue // by constantly respawning each other. if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 { lock(&sched.lock) gp = globrunqget(_g_.m.p.ptr(), 1) unlock(&sched.lock) } } if gp == nil { gp, inheritTime = runqget(_g_.m.p.ptr()) // We can see gp != nil here even if the M is spinning, // if checkTimers added a local goroutine via goready. } if gp == nil { gp, inheritTime = findrunnable() // blocks until work is available } // This thread is going to run a goroutine and is not spinning anymore, // so if it was marked as spinning we need to reset it now and potentially // start a new spinning M. if _g_.m.spinning { resetspinning() } if sched.disable.user && !schedEnabled(gp) { // Scheduling of this goroutine is disabled. Put it on // the list of pending runnable goroutines for when we // re-enable user scheduling and look again. lock(&sched.lock) if schedEnabled(gp) { // Something re-enabled scheduling while we // were acquiring the lock. unlock(&sched.lock) } else { sched.disable.runnable.pushBack(gp) sched.disable.n++ unlock(&sched.lock) goto top } } // If about to schedule a not-normal goroutine (a GCworker or tracereader), // wake a P if there is one. if tryWakeP { wakep() } if gp.lockedm != 0 { // Hands off own p to the locked m, // then blocks waiting for a new p. startlockedm(gp) goto top } execute(gp, inheritTime) }
-
为了保证公平,当全局运行队列中有待执行的 Goroutine 时,有一定几率会从全局的运行队列中查找对应的 Goroutine;
-
从当前处理器本地的运行队列中查找待执行的 Goroutine;
-
如果前两种方法都没有找到 Goroutine,就会通过
findrunnable进行查找,这个函数的实现相对比较复杂,它会尝试从其他处理器上取出一部分 Goroutine,如果没有可执行的任务就会阻塞直到条件满足; findrunnable函数会再次从本地运行队列、全局运行队列、网络轮训器和其他的处理器中获取待执行的任务,该方法一定会返回待执行的 Goroutine,否则就会一直阻塞
获取可以执行的任务之后就会调用 execute 函数执行该 Goroutine,执行的过程中会先将其状态修改成 _Grunning、与线程 M 建立起双向的关系并调用 gogo 触发调度。
// Schedules gp to run on the current M. // If inheritTime is true, gp inherits the remaining time in the // current time slice. Otherwise, it starts a new time slice. // Never returns. // // Write barriers are allowed because this is called immediately after // acquiring a P in several places. // //go:yeswritebarrierrec func execute(gp *g, inheritTime bool) { _g_ := getg() // Assign gp.m before entering _Grunning so running Gs have an // M. _g_.m.curg = gp gp.m = _g_.m casgstatus(gp, _Grunnable, _Grunning) gp.waitsince = 0 gp.preempt = false gp.stackguard0 = gp.stack.lo + _StackGuard if !inheritTime { _g_.m.p.ptr().schedtick++ } // Check whether the profiler needs to be turned on or off. hz := sched.profilehz if _g_.m.profilehz != hz { setThreadCPUProfiler(hz) } if trace.enabled { // GoSysExit has to happen when we have a P, but before GoStart. // So we emit it here. if gp.syscallsp != 0 && gp.sysblocktraced { traceGoSysExit(gp.sysexitticks) } traceGoStart() } gogo(&gp.sched) }
gogo 在不同处理器架构上的实现都不相同 参考386
/*
* go-routine
*/
// void gogo(Gobuf*)
// restore state from Gobuf; longjmp
TEXT runtime·gogo(SB), NOSPLIT, $0-4
MOVL buf+0(FP), BX // gobuf
MOVL gobuf_g(BX), DX
MOVL 0(DX), CX // make sure g != nil
JMP gogo<>(SB)
TEXT gogo<>(SB), NOSPLIT, $0
get_tls(CX)
MOVL DX, g(CX)
MOVL gobuf_sp(BX), SP // restore SP
MOVL gobuf_ret(BX), AX
MOVL gobuf_ctxt(BX), DX
MOVL $0, gobuf_sp(BX) // clear to help garbage collector
MOVL $0, gobuf_ret(BX)
MOVL $0, gobuf_ctxt(BX)
MOVL gobuf_pc(BX), BX
JMP BX
这个函数会从 gobuf 中取出 Goroutine 指针、栈指针、返回值、上下文以及程序计数器并将通过 JMP 指令跳转至 Goroutine 应该继续执行代码的位置。