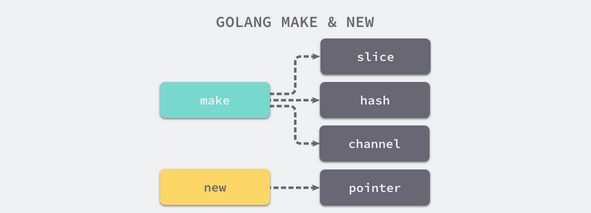
在代码中往往都会使用如下所示的语句初始化这三类基本类型,这三个语句分别返回了不同类型的数据结构:
slice := make([]int, 0, 100) hash := make(map[int]bool, 10) ch := make(chan int, 5)
slice是一个包含data、cap和len的结构体reflect.SliceHeader;hash是一个指向runtime.hmap结构体的指针;ch是一个指向runtime.hchan结构体的指针;
相比与复杂的 make 关键字,new 的功能就简单多了,它只能接收类型作为参数然后返回一个指向该类型的指针:
i := new(int) var v int i := &v
分析使用 for i, elem := range a {} 遍历数组和切片,关心索引和数据的情况??
其编译器解析后代码如下:
ha := a hv1 := 0 hn := len(ha) v1 := hv1 v2 := nil for ; hv1 < hn; hv1++ { tmp := ha[hv1] v1, v2 = hv1, tmp ... }
对于所有的 range 循环,Go 语言都会在编译期将原切片或者数组赋值给一个新变量 ha,在赋值的过程中就发生了拷贝,
而我们又通过 len 关键字预先获取了切片的长度,所以在循环中追加新的元素也不会改变循环执行的次数;遇到这种同时遍历索引和元素的 range 循环时,Go 语言会额外创建一个新的 v2 变量存储切片中的元素,循环中使用的这个变量 v2 会在每一次迭代被重新赋值而覆盖,赋值时也会触发拷贝。
package main import "fmt" type student struct { Name string Age int } func main() { arr := []int{1, 2, 3} newArr := []*int{} for _, v := range arr { fmt.Println("") fmt.Printf("origin addr: %p value: %v", &v, v) newArr = append(newArr, &v) } for _, s := range newArr { fmt.Println("") fmt.Printf("addr: %p value: %v", s, *s) } fmt.Printf(" ") students := pase_student() for k, v := range students { fmt.Printf("key=%s,value=%v ", k, v) } } func pase_student() map[string]*student { m := make(map[string]*student) stus := []student{ {Name: "zhou", Age: 24}, {Name: "li", Age: 23}, {Name: "wang", Age: 22}, } for _, stu := range stus { m[stu.Name] = &stu } return m }
结果为:
origin addr: 0xc000016060 value: 1 origin addr: 0xc000016060 value: 2 origin addr: 0xc000016060 value: 3 addr: 0xc000016060 value: 3 addr: 0xc000016060 value: 3 addr: 0xc000016060 value: 3 key=zhou,value=&{wang 22} key=li,value=&{wang 22} key=wang,value=&{wang 22}
因为在循环中获取返回变量的地址都完全相同,所以会发生神奇的指针一节中的现象。---->循环中使用的这个变量 v2 会在每一次迭代被重新赋值而覆盖,赋值时也会触发拷贝
因此当我们想要访问数组中元素所在的地址时,不应该直接获取 range 返回的变量地址 &v2,而应该使用 &a[index] 这种形式。
defer
使用 defer 的最常见场景是在函数调用结束后完成一些收尾工作,例如在 defer 中回滚数据库的事务, close 回收资源
Go 语言中使用 defer 时会遇到两个常见问题
defer关键字的调用时机以及多次调用defer时执行顺序是如何确定的;defer关键字使用传值的方式传递参数时会进行预计算,导致不符合预期的结果
作用域
向 defer 关键字传入的函数会在函数返回之前运行
func main() { { defer fmt.Println("defer runs") fmt.Println("block ends") } fmt.Println("main ends") } $ go run main.go block ends main ends defer runs
从上述代码的输出我们会发现,defer 传入的函数不是在退出代码块的作用域时执行的,它只会在当前函数和方法返回之前被调用。
func main() { startedAt := time.Now() defer fmt.Println(time.Since(startedAt)) time.Sleep(time.Second) } $ go run main.go 0s
调用 defer 关键字会立刻拷贝函数中引用的外部参数,所以 time.Since(startedAt) 的结果不是在 main 函数退出之前计算的,而是在 defer 关键字调用时计算的,最终导致上述代码输出 0s
defer 关键字在 Go 语言源代码中对应的数据结构:
type _defer struct { siz int32 started bool openDefer bool sp uintptr pc uintptr fn *funcval _panic *_panic link *_defer }
runtime._defer 结构体是延迟调用链表上的一个元素,所有的结构体都会通过 link 字段串联成链表。runtime._defer 结构体中还包含一些垃圾回收机制使用的字段
siz是参数和结果的内存大小;sp和pc分别代表栈指针和调用方的程序计数器;fn是defer关键字中传入的函数;_panic是触发延迟调用的结构体,可能为空;openDefer表示当前defer是否经过开放编码的优化;
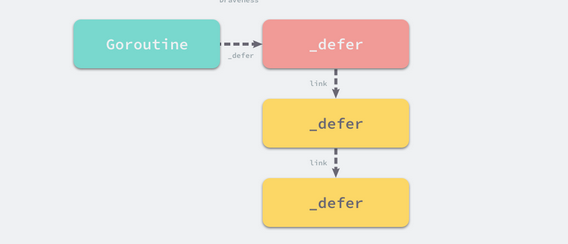
list
- 后调用的
defer函数会先执行:- 后调用的
defer函数会被追加到 Goroutine_defer链表的最前面; - 运行
runtime._defer时是从前到后依次执行;
- 后调用的
- 函数的参数会被预先计算;
- 调用
runtime.deferproc函数创建新的延迟调用时就会立刻拷贝函数的参数,函数的参数不会等到真正执行时计算;
- 调用
panic 和 recover
panic能够改变程序的控制流,调用panic后会立刻停止执行当前函数的剩余代码,并在当前 Goroutine 中递归执行调用方的defer;recover可以中止panic造成的程序崩溃。它是一个只能在defer中发挥作用的函数,在其他作用域中调用不会发挥作用;
panic只会触发当前 Goroutine 的defer;recover只有在defer中调用才会生效;panic允许在defer中嵌套多次调用;

main 函数中的 defer 语句并没有执行,执行的只有当前 Goroutine 中的 defer。defer 关键字对应的 runtime.deferproc 会将延迟调用函数与调用方所在 Goroutine 进行关联。所以当程序发生崩溃时只会调用当前 Goroutine 的延迟调用函数也是非常合理的。

嵌套崩溃
Go 语言中的 panic 是可以多次嵌套调用的

panic 关键字在 Go 语言的源代码是由数据结构 runtime._panic 表示的。每当我们调用 panic 都会创建一个如下所示的数据结构存储相关信息:
argp是指向defer调用时参数的指针;arg是调用panic时传入的参数;link指向了更早调用的runtime._panic结构;recovered表示当前runtime._panic是否被recover恢复;aborted表示当前的panic是否被强行终止;
从数据结构中的 link 字段我们就可以推测出以下的结论:panic 函数可以被连续多次调用,它们之间通过 link 可以组成链表。
panic 函数是终止程序的实现原理
编译器会将关键字 panic 转换成 runtime.gopanic,该函数的执行过程包含以下几个步骤:
- 创建新的
runtime._panic并添加到所在 Goroutine 的_panic链表的最前面; - 在循环中不断从当前 Goroutine 的
_defer中链表获取runtime._defer并调用runtime.reflectcall运行延迟调用函数; - 调用
runtime.fatalpanic中止整个程序;
关于recover 后续再看
LIST:
- 编译器会负责做转换关键字的工作;
- 将
panic和recover分别转换成runtime.gopanic和runtime.gorecover; - 将
defer转换成runtime.deferproc函数; - 在调用
defer的函数末尾调用runtime.deferreturn函数;
- 将
- 在运行过程中遇到
runtime.gopanic方法时,会从 Goroutine 的链表依次取出runtime._defer结构体并执行; - 如果调用延迟执行函数时遇到了
runtime.gorecover就会将_panic.recovered标记成 true 并返回panic的参数;- 在这次调用结束之后,
runtime.gopanic会从runtime._defer结构体中取出程序计数器pc和栈指针sp并调用runtime.recovery函数进行恢复程序; runtime.recovery会根据传入的pc和sp跳转回runtime.deferproc;- 编译器自动生成的代码会发现
runtime.deferproc的返回值不为 0,这时会跳回runtime.deferreturn并恢复到正常的执行流程;
- 在这次调用结束之后,
- 如果没有遇到
runtime.gorecover就会依次遍历所有的runtime._defer,并在最后调用runtime.fatalpanic中止程序、打印panic的参数并返回错误码 2;