之前在csdn记录过缺页中断的相关逻辑!貌似现在也找不回了!!所以转载一下网上一些文章方便自己回忆!
实际上深入理解linux 内核这本书里面有讲解这一章
缺页异常在linux内核处理中占有非常重要的位置,很多linux特性,如写时复制,页框延迟分配,内存回收中的磁盘和内存交换,都需要借助缺页异常来进行,缺页异常处理程序主要处理以下四种情形:
1、请求调页:
当进程调用malloc()之类的函数调用时,并未实际上分配物理内存,而是仅仅分配了一段线性地址空间,在实际访问该页框时才实际去分配物理页框,这样可以节省物理内存的开销,还有一种情况是在内存回收时,该物理页面的内容被写到了磁盘上,被系统回收了,这时候需要再分配页框,并且读取其保存的内容。
2、写时复制:当fork()一个进程时,子进程并未完整的复制父进程的地址空间,而是共享相关的资源,父进程的页表被设为只读的,当子进程进行写操作时,会触发缺页异常,从而为子进程分配页框。
3、地址范围外的错误:内核访问无效地址,用户态进程访问无效地址等。
4、内核访问非连续性地址:用于内核的高端内存映射,高端内存映射仅仅修改了主内核页表的内容,当进程访问内核态时需要将该部分的页表内容复制到自己的进程页表里面。
缺页异常处理程序有可能发生在用户态或者内核态的代码中,在这两种形态下,有可能访问的是内核空间或者用户态空间的内存地址,因此,按照排列组合,需要考虑下列的四种情形
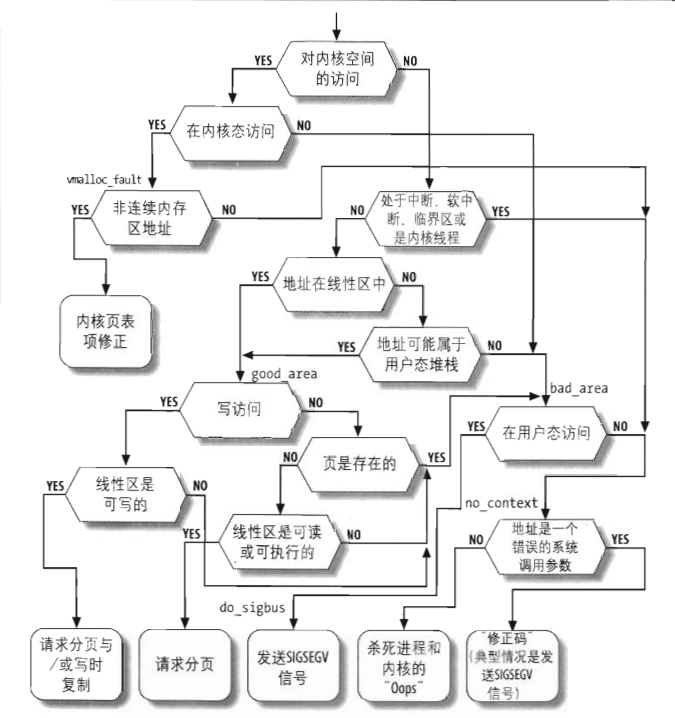
缺页异常发生在内核态
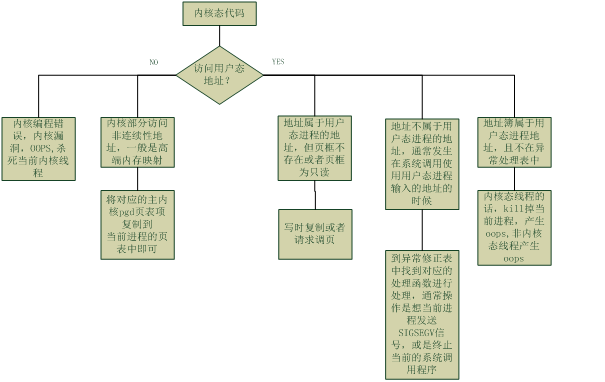
缺页异常发生在用户态
dotraplinkage void notrace do_page_fault(struct pt_regs *regs, unsigned long error_code) { //由于异常发生的时候 cpu会将这个引起缺页异常的地址存在 CR2寄存器中 //将引发缺页异常的线性地址保存在address变量里面 unsigned long address = read_cr2(); /* Get the faulting address */ enum ctx_state prev_state; /* * We must have this function tagged with __kprobes, notrace and call * read_cr2() before calling anything else. To avoid calling any kind * of tracing machinery before we've observed the CR2 value. * * exception_{enter,exit}() contain all sorts of tracepoints. */ prev_state = exception_enter(); __do_page_fault(regs, error_code, address); exception_exit(prev_state); }
1、
error_code是页的错误码, 下面是其中的含义:
/* * Page fault error code bits: * * bit 0 == 0: no page found 1: protection fault * bit 1 == 0: read access 1: write access * bit 2 == 0: kernel-mode access 1: user-mode access * bit 3 == 1: use of reserved bit detected * bit 4 == 1: fault was an instruction fetch * bit 5 == 1: protection keys block access */ enum x86_pf_error_code { PF_PROT = 1 << 0, PF_WRITE = 1 << 1, PF_USER = 1 << 2, PF_RSVD = 1 << 3, PF_INSTR = 1 << 4, PF_PK = 1 << 5, };
对于其访问权限的匹配检查:
写但不存在该页框 该线性区不让写,发生错误 !!读,存在该页框 !! 读但是不存在该页框,缺页,需要进行调页 !! 写,存在该页框,写时复制的情况 !!
access_error(unsigned long error_code, struct vm_area_struct *vma) { /* This is only called for the current mm, so: */ bool foreign = false; /* * Make sure to check the VMA so that we do not perform * faults just to hit a PF_PK as soon as we fill in a * page. */ if (!arch_vma_access_permitted(vma, (error_code & PF_WRITE), (error_code & PF_INSTR), foreign)) return 1; if (error_code & PF_WRITE) { /* write, present and write, not present: */ if (unlikely(!(vma->vm_flags & VM_WRITE))) return 1; return 0; } /* read, present: */ if (unlikely(error_code & PF_PROT)) return 1; /* read, not present: */ if (unlikely(!(vma->vm_flags & (VM_READ | VM_EXEC | VM_WRITE)))) return 1; return 0; }
地址为用户空间:
4,如果使用了保留位,打印信息,杀死当前进程;
5,如果在中断上下文中火临界区中时,直接跳到非法访问;
6,如果出错在内核空间中,查看异常表,进行相应的处理;
7,查找地址对应的vma,如果找不到,直接跳到非法访问处,如果找到正常,跳到good_area;
good_area处,再次检查权限;权限正确后分配新页框,页表等;
* * This routine handles page faults. It determines the address, * and the problem, and then passes it off to one of the appropriate * routines. * * This function must have noinline because both callers * {,trace_}do_page_fault() have notrace on. Having this an actual function * guarantees there's a function trace entry. */ static noinline void __do_page_fault(struct pt_regs *regs, unsigned long error_code, unsigned long address) { struct vm_area_struct *vma; struct task_struct *tsk; struct mm_struct *mm; int fault, major = 0; unsigned int flags = FAULT_FLAG_ALLOW_RETRY | FAULT_FLAG_KILLABLE; tsk = current; mm = tsk->mm; /* * Detect and handle instructions that would cause a page fault for * both a tracked kernel page and a userspace page. */ if (kmemcheck_active(regs)) kmemcheck_hide(regs); prefetchw(&mm->mmap_sem); if (unlikely(kmmio_fault(regs, address))) return; /* * We fault-in kernel-space virtual memory on-demand. The * 'reference' page table is init_mm.pgd. * * NOTE! We MUST NOT take any locks for this case. We may * be in an interrupt or a critical region, and should * only copy the information from the master page table, * nothing more. * * This verifies that the fault happens in kernel space * (error_code & 4) == 0, and that the fault was not a * protection error (error_code & 9) == 0. static int fault_in_kernel_space(unsigned long address) { return address >= TASK_SIZE_MAX; } *///该分支表明发生缺页时是发生在访问内核空间时 if (unlikely(fault_in_kernel_space(address))) { if (!(error_code & (PF_RSVD | PF_USER | PF_PROT))) { //该分支表示发生缺页异常时,代码是在内核态访问内核态不存在 //的地址,转到vmalloc_fault处理分支,可能是访问了不连续的内核页面 if (vmalloc_fault(address) >= 0)//如果位于vmalloc区域 vmalloc_sync_one同步内核页表进程页表 return;//主要操作就是把主内核页表上对应的表项复制到当前进程的页表中 成功就返回
if (kmemcheck_fault(regs, address, error_code)) return; } /* Can handle a stale RO->RW TLB: */ /*内核空间的地址,检查页表对应项的写、执行权限*/ if (spurious_fault(error_code, address)) return; /* kprobes don't want to hook the spurious faults: */ if (kprobes_fault(regs)) return; /* * Don't take the mm semaphore here. If we fixup a prefetch * fault we could otherwise deadlock: *///做相应出错处理 bad_area_nosemaphore(regs, error_code, address, NULL); return; } /* kprobes don't want to hook the spurious faults: */ if (unlikely(kprobes_fault(regs))) return; if (unlikely(error_code & PF_RSVD)) pgtable_bad(regs, error_code, address); if (unlikely(smap_violation(error_code, regs))) { bad_area_nosemaphore(regs, error_code, address, NULL); return; } /* * If we're in an interrupt, have no user context or are running * in a region with pagefaults disabled then we must not take the fault */ //在中断或者软中断中访问用户态空间,发生问题,是不可以的,因为中断或者 //软中断不代表任何的进程,mm为NULL代表着该进程是内核线程,内核线程 //继承了上一个普通进程页表,不能对其进行修改 //#define faulthandler_disabled() (pagefault_disabled() || in_atomic()) if (unlikely(faulthandler_disabled() || !mm)) { bad_area_nosemaphore(regs, error_code, address, NULL); return; } /* * It's safe to allow irq's after cr2 has been saved and the * vmalloc fault has been handled. * * User-mode registers count as a user access even for any * potential system fault or CPU buglet: */ if (user_mode(regs)) { local_irq_enable(); error_code |= PF_USER; flags |= FAULT_FLAG_USER; } else { if (regs->flags & X86_EFLAGS_IF) local_irq_enable(); } perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS, 1, regs, address); if (error_code & PF_WRITE) flags |= FAULT_FLAG_WRITE; if (error_code & PF_INSTR) flags |= FAULT_FLAG_INSTRUCTION; /* * When running in the kernel we expect faults to occur only to * addresses in user space. All other faults represent errors in * the kernel and should generate an OOPS. Unfortunately, in the * case of an erroneous fault occurring in a code path which already * holds mmap_sem we will deadlock attempting to validate the fault * against the address space. Luckily the kernel only validly * references user space from well defined areas of code, which are * listed in the exceptions table. * * As the vast majority of faults will be valid we will only perform * the source reference check when there is a possibility of a * deadlock. Attempt to lock the address space, if we cannot we then * validate the source. If this is invalid we can skip the address * space check, thus avoiding the deadlock: */ //尝试获取到读锁,若获得读锁失败时 if (unlikely(!down_read_trylock(&mm->mmap_sem))) { //在内核态访问用户态的地址,这种情况发生在在 //进程的系统调用中去访问用户态的地址,在访问 //地址前,内核是不会去写对应的读锁的,所以可能是 //别的进程写了,相应的锁,所以需要等待,其它情况 //属于错误情况 if ((error_code & PF_USER) == 0 && !search_exception_tables(regs->ip)) { bad_area_nosemaphore(regs, error_code, address, NULL); return; } retry: down_read(&mm->mmap_sem); } else { /* * The above down_read_trylock() might have succeeded in * which case we'll have missed the might_sleep() from * down_read(): */ might_sleep(); } //下面这几句话是来判断出错地址是否在进程的线性区内 vma = find_vma(mm, address); if (unlikely(!vma)) { //不在线性区内,地址错误 进入错误处理 bad_area(regs, error_code, address); return; } //在线性区内,跳到正常处理部分 if (likely(vma->vm_start <= address)) goto good_area;//-----> 走正常逻辑处理 //下面这些代码属于扩展进程栈的相关处理,该地址可能由push或者pusha指令引起 //向低地址扩展的栈其线性区的标志位会置上VM_GROWSDOWN if (unlikely(!(vma->vm_flags & VM_GROWSDOWN))) { bad_area(regs, error_code, address); return; } if (error_code & PF_USER) {{//异常发生在用户态 /* * Accessing the stack below %sp is always a bug. * The large cushion allows instructions like enter * and pusha to work. ("enter $65535, $31" pushes * 32 pointers and then decrements %sp by 65535.) *///对于栈操作,发生错误的内存地址不应该比esp小太多,不该小32个byte以上 if (unlikely(address + 65536 + 32 * sizeof(unsigned long) < regs->sp)) { bad_area(regs, error_code, address); /* 访问了越界的栈空间 */ return; } } //扩展进程的用户态堆栈 if (unlikely(expand_stack(vma, address))) { bad_area(regs, error_code, address); return; } /* * Ok, we have a good vm_area for this memory access, so * we can handle it.. */ good_area: //权限匹配处理 写动作出错但是不允许写的情况 if (unlikely(access_error(error_code, vma))) {// 根据页的错误类型与vma的访问权限是否匹配 bad_area_access_error(regs, error_code, address, vma);//不匹配 return; } /* * If for any reason at all we couldn't handle the fault, * make sure we exit gracefully rather than endlessly redo * the fault. Since we never set FAULT_FLAG_RETRY_NOWAIT, if * we get VM_FAULT_RETRY back, the mmap_sem has been unlocked. */ //在handle_mm_fault()函数里面处理缺页的情况 fault = handle_mm_fault(mm, vma, address, flags); major |= fault & VM_FAULT_MAJOR; /* * If we need to retry the mmap_sem has already been released, * and if there is a fatal signal pending there is no guarantee * that we made any progress. Handle this case first. */ if (unlikely(fault & VM_FAULT_RETRY)) { /* Retry at most once */ if (flags & FAULT_FLAG_ALLOW_RETRY) { flags &= ~FAULT_FLAG_ALLOW_RETRY; flags |= FAULT_FLAG_TRIED; if (!fatal_signal_pending(tsk)) goto retry; } /* User mode? Just return to handle the fatal exception */ if (flags & FAULT_FLAG_USER) return; /* Not returning to user mode? Handle exceptions or die: */ no_context(regs, error_code, address, SIGBUS, BUS_ADRERR); return; } up_read(&mm->mmap_sem); /* #define VM_FAULT_ERROR (VM_FAULT_OOM | VM_FAULT_SIGBUS | VM_FAULT_SIGSEGV | \ VM_FAULT_HWPOISON | VM_FAULT_HWPOISON_LARGE | \ VM_FAULT_FALLBACK) */ if (unlikely(fault & VM_FAULT_ERROR)) {//调页发生错误 mm_fault_error(regs, error_code, address, vma, fault); return; } /* * Major/minor page fault accounting. If any of the events * returned VM_FAULT_MAJOR, we account it as a major fault. */ if (major) {//在阻塞的情况下,完成了调页操作 tsk->maj_flt++; perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS_MAJ, 1, regs, address); } else { tsk->min_flt++;//在没有阻塞的情况下,完成了调页 perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS_MIN, 1, regs, address); } check_v8086_mode(regs, address, tsk); }
bad_area的处理逻辑:
如果在用户空间访问,直接发送SEGSEGV信号;
2,如果在内核空间访问分为两种情况:
1)地址是一个错误的系统调用参数,修正码(典型是发送SIGSEGV信号);
2)反之,杀死进程并显示内核的OOPS信息;
static noinline void no_context(struct pt_regs *regs, unsigned long error_code, unsigned long address, int signal, int si_code) { struct task_struct *tsk = current; unsigned long flags; int sig; /* No context means no VMA to pass down */ struct vm_area_struct *vma = NULL; //是否有动态修正代码,该异常通常发生在将用户态线性地址 //作为参数传递给了系统调用,该错误发生在内核态访问一个 //用户态地址,但用户态地址不属于进程的地址空间 /* Are we prepared to handle this kernel fault? */ if (fixup_exception(regs, X86_TRAP_PF)) { /* * Any interrupt that takes a fault gets the fixup. This makes * the below recursive fault logic only apply to a faults from * task context. */ if (in_interrupt()) return; /* * Per the above we're !in_interrupt(), aka. task context. * * In this case we need to make sure we're not recursively * faulting through the emulate_vsyscall() logic. */ if (current_thread_info()->sig_on_uaccess_error && signal) { tsk->thread.trap_nr = X86_TRAP_PF; tsk->thread.error_code = error_code | PF_USER; tsk->thread.cr2 = address; /* XXX: hwpoison faults will set the wrong code. */ force_sig_info_fault(signal, si_code, address, tsk, vma, 0); } /* * Barring that, we can do the fixup and be happy. */ return; } /* * 32-bit: * * Valid to do another page fault here, because if this fault * had been triggered by is_prefetch fixup_exception would have * handled it. * * 64-bit: * * Hall of shame of CPU/BIOS bugs. */ if (is_prefetch(regs, error_code, address)) return; if (is_errata93(regs, address)) return; /* * Oops. The kernel tried to access some bad page. We'll have to * terminate things with extreme prejudice: */ //发生了真正的内核错误,往输出上打印相关错误信息 flags = oops_begin(); show_fault_oops(regs, error_code, address); if (task_stack_end_corrupted(tsk)) printk(KERN_EMERG "Thread overran stack, or stack corrupted\n"); tsk->thread.cr2 = address; tsk->thread.trap_nr = X86_TRAP_PF; tsk->thread.error_code = error_code; sig = SIGKILL;//产生Oops的消息 if (__die("Oops", regs, error_code)) sig = 0; /* Executive summary in case the body of the oops scrolled away */ printk(KERN_DEFAULT "CR2: %016lx\n", address); oops_end(flags, regs, sig); //退出相关进程 主要逻辑:输出panic信息 然后 do_exit(sig) 退出 } /* * Print out info about fatal segfaults, if the show_unhandled_signals * sysctl is set: */ static inline void show_signal_msg(struct pt_regs *regs, unsigned long error_code, unsigned long address, struct task_struct *tsk) { if (!unhandled_signal(tsk, SIGSEGV)) return; if (!printk_ratelimit()) return; printk("%s%s[%d]: segfault at %lx ip %p sp %p error %lx", task_pid_nr(tsk) > 1 ? KERN_INFO : KERN_EMERG, tsk->comm, task_pid_nr(tsk), address, (void *)regs->ip, (void *)regs->sp, error_code); print_vma_addr(KERN_CONT " in ", regs->ip); printk(KERN_CONT "\n"); } static void __bad_area_nosemaphore(struct pt_regs *regs, unsigned long error_code, unsigned long address, struct vm_area_struct *vma, int si_code) { struct task_struct *tsk = current; /* User mode accesses just cause a SIGSEGV */ if (error_code & PF_USER) {//该错误发生在用户态代码访问时 /* * It's possible to have interrupts off here: */ local_irq_enable(); /* * Valid to do another page fault here because this one came * from user space: */ if (is_prefetch(regs, error_code, address)) return; if (is_errata100(regs, address)) return; #ifdef CONFIG_X86_64 /* * Instruction fetch faults in the vsyscall page might need * emulation. */ if (unlikely((error_code & PF_INSTR) && ((address & ~0xfff) == VSYSCALL_ADDR))) { if (emulate_vsyscall(regs, address)) return; } #endif /* * To avoid leaking information about the kernel page table * layout, pretend that user-mode accesses to kernel addresses * are always protection faults. */ if (address >= TASK_SIZE_MAX) error_code |= PF_PROT; if (likely(show_unhandled_signals)) show_signal_msg(regs, error_code, address, tsk); tsk->thread.cr2 = address; tsk->thread.error_code = error_code; tsk->thread.trap_nr = X86_TRAP_PF; //发送sigsegv信号给当前的进程 force_sig_info_fault(SIGSEGV, si_code, address, tsk, vma, 0); return; } if (is_f00f_bug(regs, address)) return; //剩下的错误,发生在内核态 no_context(regs, error_code, address, SIGSEGV, si_code); }
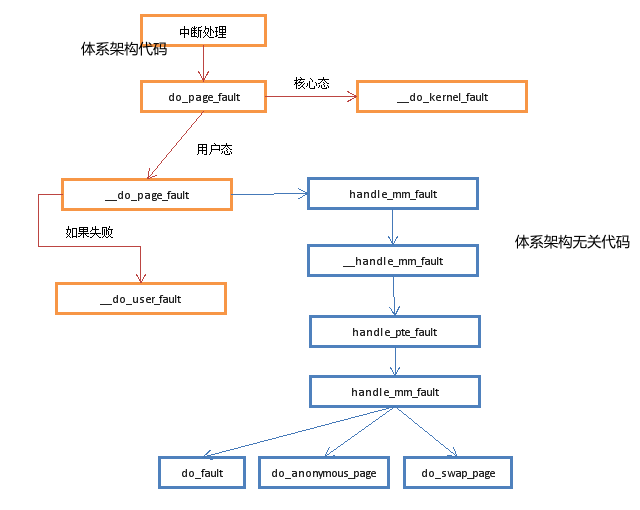
看下handle_mm_fault
* * By the time we get here, we already hold the mm semaphore * * The mmap_sem may have been released depending on flags and our * return value. See filemap_fault() and __lock_page_or_retry(). */ static int __handle_mm_fault(struct mm_struct *mm, struct vm_area_struct *vma, unsigned long address, unsigned int flags) { pgd_t *pgd; pud_t *pud; pmd_t *pmd; pte_t *pte; if (!arch_vma_access_permitted(vma, flags & FAULT_FLAG_WRITE, flags & FAULT_FLAG_INSTRUCTION, flags & FAULT_FLAG_REMOTE)) return VM_FAULT_SIGSEGV; if (unlikely(is_vm_hugetlb_page(vma))) return hugetlb_fault(mm, vma, address, flags); pgd = pgd_offset(mm, address);///返回指定的mm的全局目录项的指针 pud = pud_alloc(mm, pgd, address);//在X86的4级页面机制中,不做任何操作,直接返回pgd if (!pud) return VM_FAULT_OOM; //找到相应的pmd表的地址,没有的话,分配一个 pmd = pmd_alloc(mm, pud, address); if (!pmd) return VM_FAULT_OOM; -------------------------------/* * Use pte_alloc() instead of pte_alloc_map, because we can't * run pte_offset_map on the pmd, if an huge pmd could * materialize from under us from a different thread. */ if (unlikely(pte_alloc(mm, pmd, address))) return VM_FAULT_OOM; /* * If a huge pmd materialized under us just retry later. Use * pmd_trans_unstable() instead of pmd_trans_huge() to ensure the pmd * didn't become pmd_trans_huge under us and then back to pmd_none, as * a result of MADV_DONTNEED running immediately after a huge pmd fault * in a different thread of this mm, in turn leading to a misleading * pmd_trans_huge() retval. All we have to ensure is that it is a * regular pmd that we can walk with pte_offset_map() and we can do that * through an atomic read in C, which is what pmd_trans_unstable() * provides. */ if (unlikely(pmd_trans_unstable(pmd) || pmd_devmap(*pmd))) return 0; /* * A regular pmd is established and it can't morph into a huge pmd * from under us anymore at this point because we hold the mmap_sem * read mode and khugepaged takes it in write mode. So now it's * safe to run pte_offset_map(). */ //找到对应的pte表的地址,即页表的地址,找不到 //的话,分配一个 pte = pte_offset_map(pmd, address); //进行相应的缺页处理: //分为 请求调页 or 写时复制 return handle_pte_fault(mm, vma, address, pte, pmd, flags); }
缺页处理的具体流程:
-
访问的页表Page Table尚未分配:
当页表从未被访问时,有两种方法装入所缺失的页,这取决于这个页是否被映射到磁盘文件:
vma->vm_ops不为NULL即
vma对应磁盘上某一个文件,调用vma->vm_ops->fault(vmf).vma->vm_ops为NULL即
vma没有对应磁盘的文件为匿名映射,调用do_anonymous_page(vmf)分配页面.-
处理只读的缺页:
do_read_fault()即根据文件系统设置的
vma的缺页处理函数,在EXT4文件系统中,对应的是ext4_filemap_fault(),其逻辑就是读文件: 先从Page Cache中查找,假如不存在,从文件上读取至Page Cache. -
处理写时复制的缺页:
do_cow_fault() -
处理共享页的缺页:
do_shared_fault()
-
-
访问的页表已经分配,但保存在swap交换区:
do_swap_page() -
访问的页表已经分配,且存在于物理内存中,即触发写时复制(COW)的缺页中断:
do_wp_page()写时复制的概念不多做介绍,仅仅来看Linux内核是如何处理写时复制:
- 为
vma申请一个Page. - 调用
vma->vm_ops->fault(vmf)读取数据. - 将函数把旧页面的内容复制到新分配的页面.
- 为
/* * These routines also need to handle stuff like marking pages dirty * and/or accessed for architectures that don't do it in hardware (most * RISC architectures). The early dirtying is also good on the i386. * * There is also a hook called "update_mmu_cache()" that architectures * with external mmu caches can use to update those (ie the Sparc or * PowerPC hashed page tables that act as extended TLBs). * * We enter with non-exclusive mmap_sem (to exclude vma changes, * but allow concurrent faults), and pte mapped but not yet locked. * We return with pte unmapped and unlocked. * * The mmap_sem may have been released depending on flags and our * return value. See filemap_fault() and __lock_page_or_retry(). */ static int handle_pte_fault(struct mm_struct *mm, struct vm_area_struct *vma, unsigned long address, pte_t *pte, pmd_t *pmd, unsigned int flags) { pte_t entry; spinlock_t *ptl; /* * some architectures can have larger ptes than wordsize, * e.g.ppc44x-defconfig has CONFIG_PTE_64BIT=y and CONFIG_32BIT=y, * so READ_ONCE or ACCESS_ONCE cannot guarantee atomic accesses. * The code below just needs a consistent view for the ifs and * we later double check anyway with the ptl lock held. So here * a barrier will do. static inline bool vma_is_anonymous(struct vm_area_struct *vma) { return !vma->vm_ops; } */ entry = *pte; barrier(); /* 页表已经建立,但不存在于物理内存之中 */ if (!pte_present(entry)) { if (pte_none(entry)) {//如果对应的页表项存在(pte_none == true), 但是对应的页面不在物理内存, 则意味着该页已经换出 if (vma_is_anonymous(vma)) return do_anonymous_page(mm, vma, address, pte, pmd, flags); else//如果vma->ops->fault不为空, 则调用do_fault处理 return do_fault(mm, vma, address, pte, pmd, flags, entry); } /* 从磁盘交换区换入物理内存 */ return do_swap_page(mm, vma, address, pte, pmd, flags, entry); } if (pte_protnone(entry)) return do_numa_page(mm, vma, address, entry, pte, pmd); ptl = pte_lockptr(mm, pmd); spin_lock(ptl); if (unlikely(!pte_same(*pte, entry))) goto unlock; /* 页表已经建立,且也贮存在物理内存中,因为写操作触发了缺页中断,即为COW的缺页中断 */ if (flags & FAULT_FLAG_WRITE) { if (!pte_write(entry)) /* 处理Copy On Write的Write部分的缺页中断 */ return do_wp_page(mm, vma, address, pte, pmd, ptl, entry); entry = pte_mkdirty(entry); } entry = pte_mkyoung(entry); if (ptep_set_access_flags(vma, address, pte, entry, flags & FAULT_FLAG_WRITE)) { update_mmu_cache(vma, address, pte); } else { /* * This is needed only for protection faults but the arch code * is not yet telling us if this is a protection fault or not. * This still avoids useless tlb flushes for .text page faults * with threads. */ if (flags & FAULT_FLAG_WRITE) flush_tlb_fix_spurious_fault(vma, address); } unlock: pte_unmap_unlock(pte, ptl); return 0; }
mmap仅仅创建了虚拟地址空间vma, 当读写数据页时通过缺页中断后的处理建立页表或更新页表, 才真正将分配物理内存. 物理内存的分配涉及Linux内核中的伙伴算法和slab分配器,即缺页中断后Linux内核会为vma分配一个物理页帧,然后通过不同的缺页处理逻辑来完成页面的请求过程. 但其实vma结构体中并没有数据成员物理页帧Page,因为可以通过vma的虚拟地址来转换到物理页面的实际地址,所以并不需要一个直接的关联