fork、vfork、clone之间的差异
fork/vfork/clone这三者均为系统调用,进程或线程通过这三种系统调用的某一种来创建子进程/线程,
这三种调用的底层实现均为linux内核源码kernel/fork.c中的do_fork()函数来实现,它们间的唯一的差别就是传入的参数值有差异。
* * Ok, this is the main fork-routine. * * It copies the process, and if successful kick-starts * it and waits for it to finish using the VM if required. */ long _do_fork(unsigned long clone_flags, unsigned long stack_start, unsigned long stack_size, int __user *parent_tidptr, int __user *child_tidptr, unsigned long tls)
可看出do_fork有n个参数:(不同版本不一样)
(1)clone_flags:表示创建进程的各种标志位集合;
(2)stack_start:表示用户态栈的起始地址;
(3)stack_size:对应栈大小,通常设置为0;
(4)parent_tidptr和child_tidptr:分别指向用户态空间的两个指针,指向父进程和子进程的PID。
父进程通过系统调用创建子进程后,它们之间主要共享了哪些资源?
从源码的cloning flags中我们可以知道存在同一虚拟地址空间中的父子进程主要共享了4种资源:
(1)共享内存空间;(2)共享文件系统信息如根/当前工作目录等;(3)共享文件描述符;(4)共享相同的信号处理函数
/* * cloning flags: */ #define CSIGNAL 0x000000ff /* signal mask to be sent at exit */ #define CLONE_VM 0x00000100 /* set if VM shared between processes */ #define CLONE_FS 0x00000200 /* set if fs info shared between processes */ #define CLONE_FILES 0x00000400 /* set if open files shared between processes */ #define CLONE_SIGHAND 0x00000800 /* set if signal handlers and blocked signals shared */ #define CLONE_PTRACE 0x00002000 /* set if we want to let tracing continue on the child too */ #define CLONE_VFORK 0x00004000 /* set if the parent wants the child to wake it up on mm_release */ #define CLONE_PARENT 0x00008000 /* set if we want to have the same parent as the cloner */ #define CLONE_THREAD 0x00010000 /* Same thread group? */ #define CLONE_NEWNS 0x00020000 /* New mount namespace group */ #define CLONE_SYSVSEM 0x00040000 /* share system V SEM_UNDO semantics */ #define CLONE_SETTLS 0x00080000 /* create a new TLS for the child */ #define CLONE_PARENT_SETTID 0x00100000 /* set the TID in the parent */ #define CLONE_CHILD_CLEARTID 0x00200000 /* clear the TID in the child */ #define CLONE_DETACHED 0x00400000 /* Unused, ignored */ #define CLONE_UNTRACED 0x00800000 /* set if the tracing process can't force CLONE_PTRACE on this clone */ #define CLONE_CHILD_SETTID 0x01000000 /* set the TID in the child */ #define CLONE_NEWCGROUP 0x02000000 /* New cgroup namespace */ #define CLONE_NEWUTS 0x04000000 /* New utsname namespace */ #define CLONE_NEWIPC 0x08000000 /* New ipc namespace */ #define CLONE_NEWUSER 0x10000000 /* New user namespace */ #define CLONE_NEWPID 0x20000000 /* New pid namespace */ #define CLONE_NEWNET 0x40000000 /* New network namespace */ #define CLONE_IO 0x80000000 /* Clone io context */
fork实现:
- do_fork(SIGCHLD, 0, 0, NULL, NULL);
vfork实现:
- do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, 0, 0, NULL, NULL);
clone实现:
- do_fork(clone_flags, newsp, 0, parent_tidptr, child_tidptr);
参数SIGCHLD是子进程终止后用于通知父进程进行回收资源的,也就是说子进程终止后会发送SIGCHLD信号给父进程,父进程通过调用waitpid()或wait()函数回收子进程资源。
从上面fork和vfork的系统具体实现可以看出,vfork比fork多了2个标志位,分别是CLONE_VFORK和CLONE_VM;其中CLONE_VFORK表明父进程创建子进程后会被挂起,直到子进程结束释放了虚拟内存资源!
vfork创建一个线程,但主要用作创建进程的中间步骤。既然新的进程最终要调用execve执行新的目标程序,并与父进程分道扬镳,那么复制父进程的资源完全是多余的,于是vfork便应运而生,其创建一个线程并通过指针拷贝共享父进程的资源(这些资源会在execve中被替换)。 vfork与fork的另一个不同是,vfork会保证子进程先运行,在子进程执行execve或者exit之后,父进程才可能被调度运行;这也就是标志位CLONE_VM的功劳;具体使用场景就是就是 appinit进程 拉起各个业务进程使用vfork 后执行execv,等待子进程切换到别的路径执行,在执行父进程-------
而fork()系统调用会使得子进程建立一个基于父进程的完整副本,为了简便,子进程和父进程采用写时拷贝(copy-on-write,COW)机制,子进程只是拷贝了父进程的页表,并没有真正复制页表内容。只有当子进程需要写入新数据后才会采用COW为子进程创建一个副本。因此它们之间的完成先后并没有严格规定,就可能出现父进程或许先于子进程完成,或者晚于子进程完成的啦。
clone系统调用的功能:其功能主要是用于进程创建线程。三者区别显而易见,从clone的调用实参可以看出,可以指定子线程的用户空间堆栈的起始位置(newsp参数)-从用户空间传入内核空间,以及线程的入口。同时clone也可以用来创建一个进程,有选择性的复制父进程的资源(由参数flag来指定)---所以pthread的底层实现应该就是通过sys_clone系统调用完成的,具体要看代码哦!!
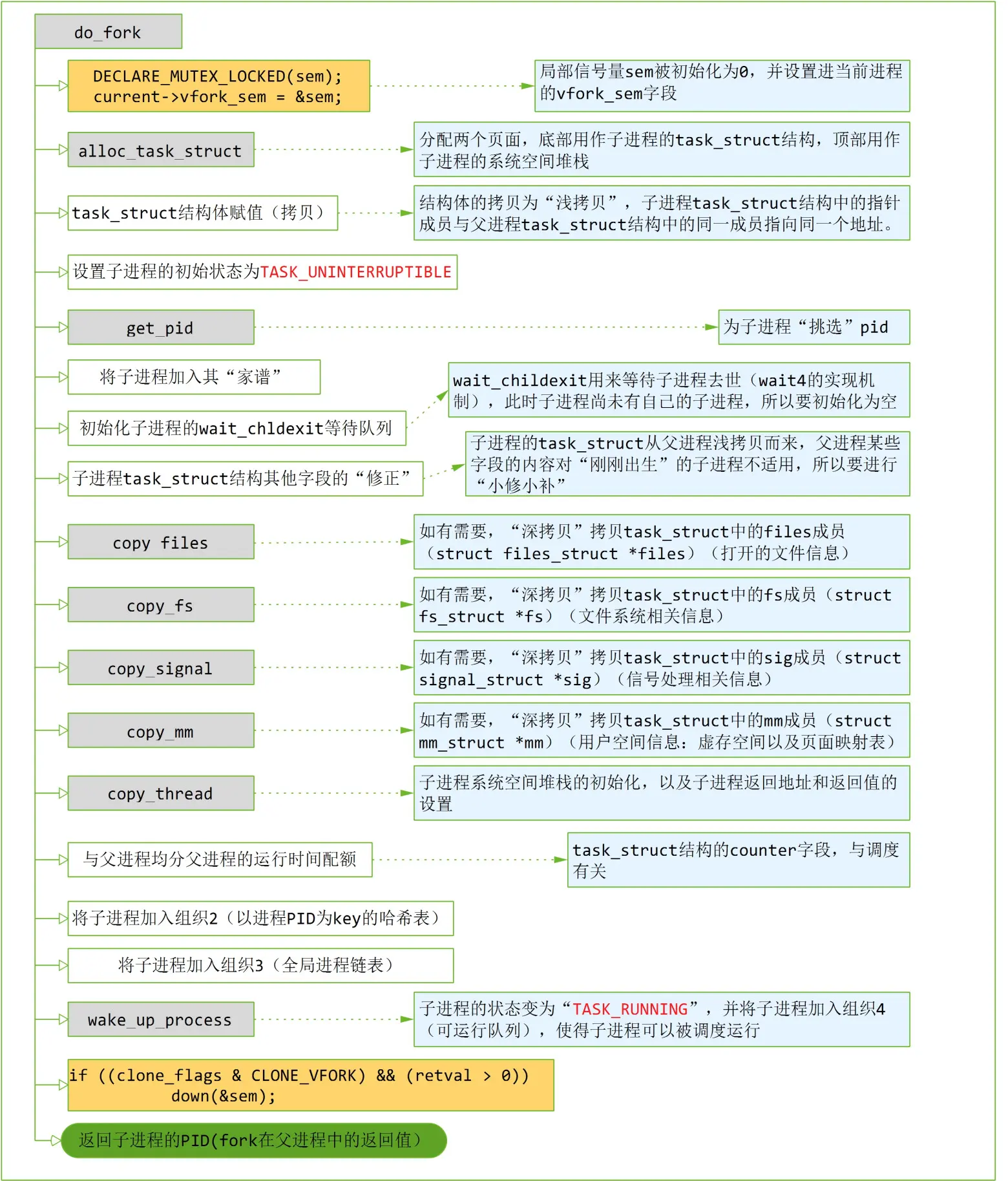
vfork会保证子进程先运行,在子进程执行execve或者exit之后,父进程才可能被调度运行。为了实现这个需求,task_struct结构中有一个struct completion *vfork_done; /* for vfork() */ 条件变量。在do_fork函数开始位置,。do_fork在完成子进程的“复制”以后,调用wake_up_process唤醒子进程,而自己则调用wait_for_vfork_done 进入睡眠。
/* * Do this prior waking up the new thread - the thread pointer * might get invalid after that point, if the thread exits quickly. */ if (!IS_ERR(p)) { struct completion vfork; struct pid *pid; trace_sched_process_fork(current, p); pid = get_task_pid(p, PIDTYPE_PID); nr = pid_vnr(pid); if (clone_flags & CLONE_PARENT_SETTID) put_user(nr, parent_tidptr); if (clone_flags & CLONE_VFORK) { p->vfork_done = &vfork; init_completion(&vfork); get_task_struct(p); } wake_up_new_task(p); /* forking complete and child started to run, tell ptracer */ if (unlikely(trace)) ptrace_event_pid(trace, pid); if (clone_flags & CLONE_VFORK) { if (!wait_for_vfork_done(p, &vfork)) ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid); } put_pid(pid); }
在子进程调用exec或者exit时,都会调用mm_release,在该函数中使用条件变量等待队列唤醒父进程。
void mm_release(struct task_struct *tsk, struct mm_struct *mm) { --------------------------- /* * All done, finally we can wake up parent and return this mm to him. * Also kthread_stop() uses this completion for synchronization. */ if (tsk->vfork_done) complete_vfork_done(tsk); }
仔细想来,vfork保证子进程先运行,不见得是内核“精心”为linux用户实现的特性,倒像是内核的无奈之举。我们知道vfork系统调用,父子进程共享进程用户空间,子进程对用户空间的修改会反过来影响父进程,反之亦然。如果说父子进程各自修改数据区的数据是危险的话,那么修改堆栈那就是致命的了。而恰巧子进程紧接着就会调用exec(或者exit),而函数调用涉及到传参,涉及到设置返回地址这些都会修改堆栈。所以决不能让两个进程都回到用户空间并发的运行,必须扣留其中的一个,而只让一个返回到用户空间去运行,直到两个进程不再共享用户空间(子进程执行exec)或者其中之一消亡(必然是先返回用户空间的子进程)为止。
即使如此,也还是有危险,子进程绝对不能从调用vfork的那个函数(caller)中返回(比如vfork之后子进程调用return),因为函数返回时,栈会被恢复平衡,之前用来存放caller的函数参数和函数返回地址的内存单元被回收,之后,这些内存单元可能被用来存放其他的内容。等到子进程去世父进程开始运行时,虽然父进程虽然有自己的esp(保存在pt_regs中),但栈中保存的caller的返回地址被破坏了(esp之上的内容都被破坏),这是很危险的。
所以vfork实际上是建立在子进程在创建后立即就会调用execve的前提之上的。
创建内核线程
内核启动过程中会调用start_kernel -->rest_init 调用函数 kernel_thread 创建 kernel_init 进程,也就是大名鼎鼎的 init 内核进程。 init 进程的 PID 为 1。
调用函数 kernel_thread 创建 kthreadd 内核进程,此内核进程的 PID 为 2。kthreadd 进程负责所有内核进程的调度和管理。
最后调用函数 cpu_startup_entry 来进入 idle 进程。当 CPU 没有事情做的时候就在 idle 空闲进程里面“瞎逛游”, idle 进程并没有使用 kernel_thread 或者 fork 函数来创建,因为它是有主进程演 变而来的。
void rest_init(void) { int pid; ……………… kernel_thread(kernel_init, NULL, CLONE_FS); numa_default_policy(); pid = kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES); rcu_read_lock(); kthreadd_task = find_task_by_pid_ns(pid, &init_pid_ns); rcu_read_unlock(); complete(&kthreadd_done);//说明kthreadd已经创建成功了,并通过一个complete变量kthreadd_done来通知kernel_init线程 init_idle_bootup_task(current);初始化一个idle(闲置)进程,这个进程不做任何其他事情,只负责消耗时间片 schedule_preempt_disabled();设置这个进程是不会被调度。因为CPU显然利用率越高越好,不可能让调度程序调度一个只消耗时间片的进程 cpu_startup_entry(CPUHP_ONLINE);使得CPU在idle这样一个循环内进行工作,不断往复,从不返回 }
/* * Create a kernel thread. */ pid_t kernel_thread(int (*fn)(void *), void *arg, unsigned long flags) { return _do_fork(flags|CLONE_VM|CLONE_UNTRACED, (unsigned long)fn, (unsigned long)arg, NULL, NULL, 0); }
kernel_thread实际实现也是通过 fo_fork 完成
看看kernel_init。 kernel_init既然是将要执行,我们就来看看kernel_init又会执行什么:
static int __ref kernel_init(void *unused) { int ret; kernel_init_freeable(); /* need to finish all async __init code before freeing the memory */ async_synchronize_full(); free_initmem(); mark_rodata_ro(); system_state = SYSTEM_RUNNING; numa_default_policy(); flush_delayed_fput(); if (ramdisk_execute_command) { ret = run_init_process(ramdisk_execute_command); if (!ret) return 0; pr_err("Failed to execute %s (error %d)\n", ramdisk_execute_command, ret); } /* * We try each of these until one succeeds. * * The Bourne shell can be used instead of init if we are * trying to recover a really broken machine. */ if (execute_command) { ret = run_init_process(execute_command); if (!ret) return 0; panic("Requested init %s failed (error %d).", execute_command, ret); } if (!try_to_run_init_process("/sbin/init") || !try_to_run_init_process("/etc/init") || !try_to_run_init_process("/bin/init") || !try_to_run_init_process("/bin/sh")) return 0; panic("No working init found. Try passing init= option to kernel. " "See Linux Documentation/init.txt for guidance."); }
kernel_init主要完成如下工作:
1、linux系统中每个进程都有自己的一个文件描述符表,表中存储的是本进程打开的文件。
2、linux系统中有一个设计理念:一切届是文件。所以设备也是以文件的方式来访问的。我们要访问一个设备,就要去打开这个设备对应的文件描述符。譬如/dev/fb0这个设备文件就代表LCD显示器设备,/dev/buzzer代表蜂鸣器设备,/dev/console代表控制台设备。打开一个设备的文件就会得到这个设备的文件描述符(或者是文件描述符的编号),这个编号就代表这个设备,以后操作这个设备就用这个文件描述符来操作它
3、这里我们打开了/dev/console文件,并且复制了2次文件描述符,一共得到了3个文件描述符。这三个文件描述符分别是0、1、2.这三个文件描述符就是所谓的:标准输入、标准输出、标准错误。
4、进程1打开了三个标准输出输出错误文件,因此后续的进程1衍生出来的所有的进程默认都具有这3个三件描述符
5、挂载根文件系统
6、执行用户态下的进程1程序;上面一旦挂载rootfs成功,则进入rootfs中寻找应用程序的init程序,找到后用run_init_process(里面的kernel_execve函数)去执行他!!
我们如何确定init程序是谁?
方法是:先从uboot传参cmdline中看有没有指定,如果有指定先执行cmdline中指定的程序。cmdline中的init=/linuxrc这个就是指定rootfs中哪个程序是init程序。这里的指定方式就表示我们rootfs的根目录下面有个名字叫linuxrc的程序,这个程序就是init程序。如果uboot传参cmdline中没有init=xx或者 cmdline中指定的这个xx执行失败,还有备用方案。
第一备用:/sbin/init,第二备用:/etc/init,第三备用:/bin/init,第四备用:/bin/sh
再不行就跪了!!!
int kthreadd(void *unused) { struct task_struct *tsk = current; /* Setup a clean context for our children to inherit. */ set_task_comm(tsk, "kthreadd"); ignore_signals(tsk); set_cpus_allowed_ptr(tsk, cpu_all_mask); set_mems_allowed(node_states[N_MEMORY]); current->flags |= PF_NOFREEZE; for (;;) { set_current_state(TASK_INTERRUPTIBLE); if (list_empty(&kthread_create_list)) schedule(); __set_current_state(TASK_RUNNING); spin_lock(&kthread_create_lock); while (!list_empty(&kthread_create_list)) { struct kthread_create_info *create; create = list_entry(kthread_create_list.next, struct kthread_create_info, list); list_del_init(&create->list); spin_unlock(&kthread_create_lock); create_kthread(create); spin_lock(&kthread_create_lock); } spin_unlock(&kthread_create_lock); } return 0; }
- 第2号进程
kthreadd进程由第0号进程通过kernel_thread()创建,并始终运行在内核空间, 负责所有内核线程的调度和管理 - 第2号进程会循环检测
kthread_create_list全局链表, 当我们调用kernel_thread创建内核线程时,新线程会被加入到此链表中,因此所有的内核线程都是直接或者间接的以kthreadd为父进程 - 检测到新线程创建,则调用
kernel_thread()创建线程,其回调为kthread
SO:
-
任何一个内核线程入口都是 kthread()
-
通过
kthread_create()创建的内核线程不会立刻运行,需要手工wake up. -
通过
kthread_create()创建的内核线程有可能不会执行相应线程函数threadfn而直接退出