内核中将filter模块被组织成了一个独立的模块,每个这样独立的模块中都有个类似的init()初始化函数;首先来看一下filter模块是如何将自己的钩子函数注册到netfilter所管辖的几个hook点。
filter 模块钩子点:
/* 在LOCAL_IN,FORWARD, LOCAL_OUT钩子点工作 */ #define FILTER_VALID_HOOKS ((1 << NF_INET_LOCAL_IN) | \ (1 << NF_INET_FORWARD) | \ (1 << NF_INET_LOCAL_OUT))

static const struct xt_table packet_filter = { .name = "filter", .valid_hooks = FILTER_VALID_HOOKS, .me = THIS_MODULE, .af = NFPROTO_IPV4, .priority = NF_IP_PRI_FILTER, .table_init = iptable_filter_table_init, };
ilist
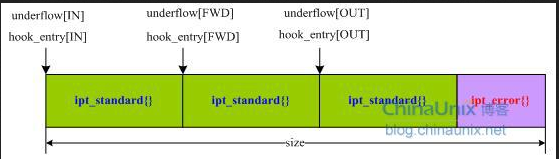
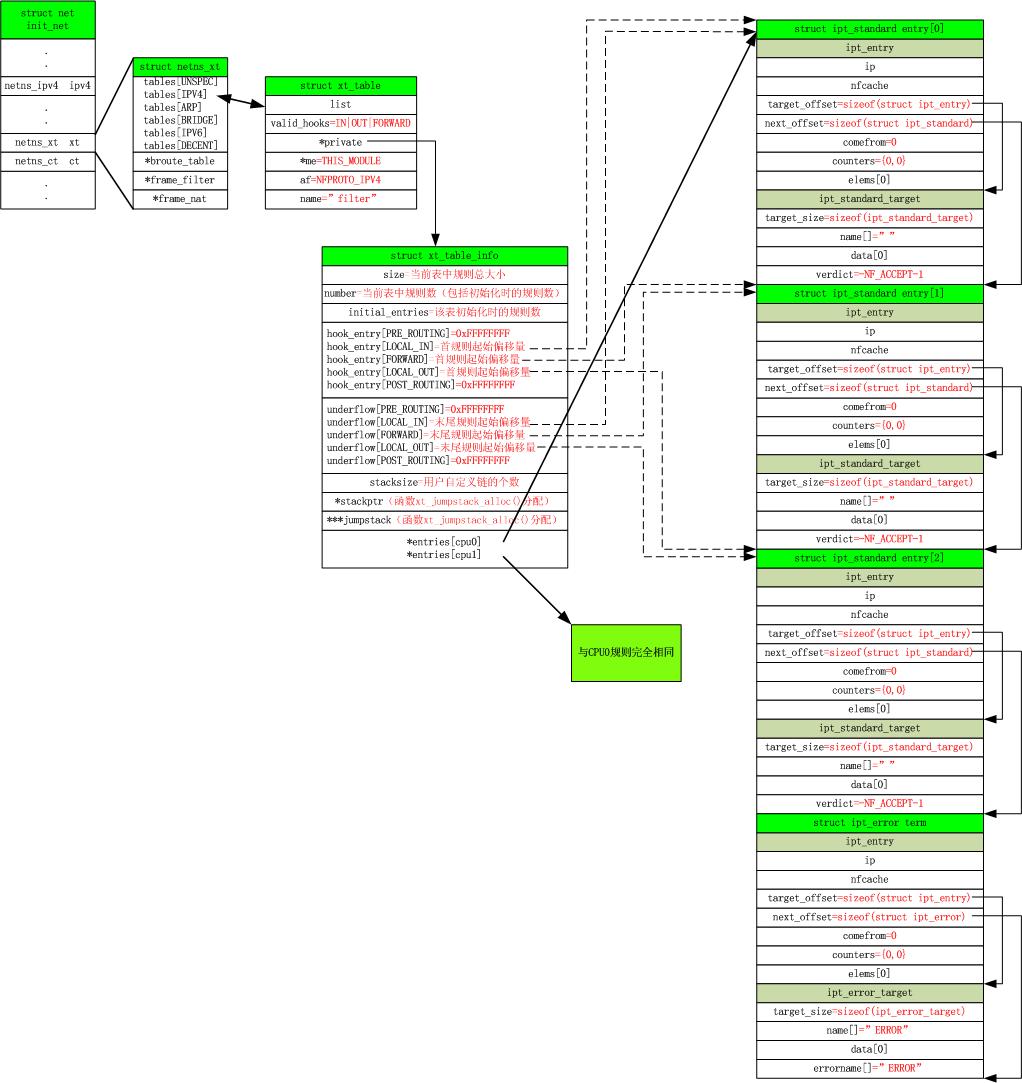
struct ipt_standard { struct ipt_entry entry; struct xt_standard_target target; }; struct ipt_error { struct ipt_entry entry; struct xt_error_target target; }; void *ipt_alloc_initial_table(const struct xt_table *info) { unsigned int hook_mask = info->valid_hooks; //LOCAL_IN、FORWARD、LOCAL_OUT unsigned int nhooks = hweight32(hook_mask); //这里得到3,上面hookmask对应三个hook点。 unsigned int bytes = 0, hooknum = 0, i = 0; //看到函数的最后,知道返回值是tbl,而这里的结构体内嵌的三个结构体是tbl的组成,三个结构体的数据结构拓扑图如图11.1.3。 struct { struct ipt_replace repl; struct ipt_standard entries[nhooks]; struct ipt_error term; } *tbl = kzalloc(sizeof(*tbl), GFP_KERNEL); if (tbl == NULL) return NULL; strncpy(tbl->repl.name, info->name, sizeof(tbl->repl.name)); tbl->term = (struct ipt_error)IPT_ERROR_INIT; tbl->repl.valid_hooks = hook_mask; tbl->repl.num_entries = nhooks + 1; tbl->repl.size = nhooks * sizeof(struct ipt_standard) + sizeof(struct ipt_error); for (; hook_mask != 0; hook_mask >>= 1, ++hooknum) { if (!(hook_mask & 1)) continue; tbl->repl.hook_entry[hooknum] = bytes; tbl->repl.underflow[hooknum] = bytes; tbl->entries[i++] = (struct ipt_standard) IPT_STANDARD_INIT(NF_ACCEPT); bytes += sizeof(struct ipt_standard); } return tbl; } /*filter模块初始化时先调用ipt_register_table向Netfilter完成filter过滤表的注册,然后调用ipt_register_hooks完成自己钩子函数的注册 */
initial_table.repl= { "filter", FILTER_VALID_HOOKS, 4,
sizeof(struct ipt_standard) * 3 + sizeof(struct ipt_error),
{ [NF_IP_LOCAL_IN] = 0,
[NF_IP_FORWARD] = sizeof(struct ipt_standard),
[NF_IP_LOCAL_OUT] = sizeof(struct ipt_standard) * 2
},
{ [NF_IP_LOCAL_IN] = 0,
[NF_IP_FORWARD] = sizeof(struct ipt_standard),
[NF_IP_LOCAL_OUT] = sizeof(struct ipt_standard) * 2
},
0, NULL, { }
};
static int __net_init iptable_filter_table_init(struct net *net)
{
struct ipt_replace *repl;
int err;
/* filter表已经被初始化了,返回 */
if (net->ipv4.iptable_filter)
return 0;
/* 分配初始化表,用于下面的表注册 */
repl = ipt_alloc_initial_table(&packet_filter);
if (repl == NULL)
return -ENOMEM;
/* Entry 1 is the FORWARD hook */
/* 入口1是否为FORWARD钩子点时的verdict值设置 */
((struct ipt_standard *)repl->entries)[1].target.verdict =
forward ? -NF_ACCEPT - 1 : -NF_DROP - 1;
err = ipt_register_table(net, &packet_filter, repl, filter_ops,
&net->ipv4.iptable_filter);
kfree(repl);
return err;
}
---最后一个柔性数组struct ipt_entry entries[0]中保存了默认的那四条规则
test
/* 简而言之ipt_register_table()所做的事情就是从模板initial_table变量的repl成员里取出初始化数据,然后申请一块内存并用repl里的值来初始化它, 之后将这块内存的首地址赋给packet_filter表的private成员,最后将packet_filter挂载到xt[2].tables的双向链表中。 */ ////iptable netfilter表注册添加到该链表中 iptable_filter.ko里面用结构xt_table,该表现源从packet_filter来的 见xt_register_table //table头部:net->xt.tables[table->af],所有table的头部链表 int ipt_register_table(struct net *net, const struct xt_table *table, const struct ipt_replace *repl, const struct nf_hook_ops *ops, struct xt_table **res) { int ret; struct xt_table_info *newinfo; struct xt_table_info bootstrap = {0}; void *loc_cpu_entry; struct xt_table *new_table; newinfo = xt_alloc_table_info(repl->size);//malloc for xt_table filter size为sizeof(struct ipt_standard) * 3 + sizeof(struct ipt_error), if (!newinfo) return -ENOMEM; loc_cpu_entry = newinfo->entries;//将表中的规则入口地址赋值给loc_cpu_entry memcpy(loc_cpu_entry, repl->entries, repl->size);//拷贝repl里面的entries规则到xt_table_info表里面的entries里面 /*translate_table函数将由newinfo所表示的table的各个规则进行边界检查, 然后对于newinfo所指的xt_talbe_info结构中的hook_entries和underflows赋予正确的值, 最后将表项向其他cpu拷贝*/ ret = translate_table(net, newinfo, loc_cpu_entry, repl); if (ret != 0) goto out_free; /* packet_filter中没对其private成员进行初始化,那么这个工作自然而然的就留给了xt_register_table()函数来完成,它也定义在x_tables.c文件中,它主要完成两件事: 1)、将由newinfo参数所存储的表里面关于规则的基本信息结构体xt_table_info{}变量赋给由table参数所表示的packet_filter{}的private成员变量; 2)、根据packet_filter的协议号af,将filter表挂到变量xt中tables成员变量所表示的双向链表里。 */ new_table = xt_register_table(net, table, &bootstrap, newinfo); if (IS_ERR(new_table)) { ret = PTR_ERR(new_table); goto out_free; } /* set res now, will see skbs right after nf_register_net_hooks */ WRITE_ONCE(*res, new_table); ret = nf_register_net_hooks(net, ops, hweight32(table->valid_hooks)); if (ret != 0) { __ipt_unregister_table(net, new_table); *res = NULL; } return ret; out_free: xt_free_table_info(newinfo); return ret; }
Filter回调函数
在上述ipt_register_table 实现中会调用nf_register_net_hooks 注册钩子回调函数
Netfilter中默认表filter在建立时则在NF_IP_LOCAL_IN,NF_IP_FORWARD,NF_IP_LOCAL_OUT钩子点注册了钩子函数iptable_filter_hook,其核心ipt_do_table()对相对应的表和钩子点的规则进行遍历
static unsigned int iptable_filter_hook(void *priv, struct sk_buff *skb, const struct nf_hook_state *state) {/* LOCAL_OUT && (数据长度不足ip头 || 实际ip头部长度不足最小ip头),在使用raw socket */ if (state->hook == NF_INET_LOCAL_OUT && (skb->len < sizeof(struct iphdr) || ip_hdrlen(skb) < sizeof(struct iphdr))) /* root is playing with raw sockets. */ return NF_ACCEPT; /* 核心规则匹配流程 */ return ipt_do_table(skb, state, state->net->ipv4.iptable_filter); }
可知其回调函数核心函数为:
/* Returns one of the generic firewall policies, like NF_ACCEPT. 包过滤子功能:包过滤一共定义了四个hook函数,这四个hook函数本质最后都调用了ipt_do_table()函数。 实际上是直接调用ipt_do_table(ip_tables.c)函数 接下来就是根据table里面的entry来处理数据包了 一个table就是一组防火墙规则的集合 而一个entry就是一条规则,每个entry由一系列的matches和一个target组成 一旦数据包匹配了该某个entry的所有matches,就用target来处理它 Match又分为两部份,一部份为一些基本的元素,如来源/目的地址,进/出网口,协议等,对应了struct ipt_ip, 我们常常将其称为标准的match,另一部份match则以插件的形式存在,是动态可选择,也允许第三方开发的, 常常称为扩展的match,如字符串匹配,p2p匹配等。同样,规则的target也是可扩展的。这样,一条规则占用的空间, 可以分为:struct ipt_ip+n*match+n*target,(n表示了其个数,这里的match指的是可扩展的match部份)。 */ unsigned int ipt_do_table(struct sk_buff *skb, const struct nf_hook_state *state, struct xt_table *table) { unsigned int hook = state->hook; static const char nulldevname[IFNAMSIZ] __attribute__((aligned(sizeof(long)))); const struct iphdr *ip; /* Initializing verdict to NF_DROP keeps gcc happy. */ unsigned int verdict = NF_DROP; const char *indev, *outdev; const void *table_base; struct ipt_entry *e, **jumpstack; unsigned int stackidx, cpu; const struct xt_table_info *private; struct xt_action_param acpar; unsigned int addend; /* Initialization */ stackidx = 0; ip = ip_hdr(skb); indev = state->in ? state->in->name : nulldevname; outdev = state->out ? state->out->name : nulldevname; /* We handle fragments by dealing with the first fragment as * if it was a normal packet. All other fragments are treated * normally, except that they will NEVER match rules that ask * things we don't know, ie. tcp syn flag or ports). If the * rule is also a fragment-specific rule, non-fragments won't * match it. */ acpar.fragoff = ntohs(ip->frag_off) & IP_OFFSET; acpar.thoff = ip_hdrlen(skb); acpar.hotdrop = false; acpar.net = state->net; acpar.in = state->in; acpar.out = state->out; acpar.family = NFPROTO_IPV4; acpar.hooknum = hook; IP_NF_ASSERT(table->valid_hooks & (1 << hook)); local_bh_disable(); addend = xt_write_recseq_begin(); private = table->private; cpu = smp_processor_id(); /* * Ensure we load private-> members after we've fetched the base * pointer. */ smp_read_barrier_depends(); table_base = private->entries; jumpstack = (struct ipt_entry **)private->jumpstack[cpu]; /* Switch to alternate jumpstack if we're being invoked via TEE. * TEE issues XT_CONTINUE verdict on original skb so we must not * clobber the jumpstack. * * For recursion via REJECT or SYNPROXY the stack will be clobbered * but it is no problem since absolute verdict is issued by these. */ if (static_key_false(&xt_tee_enabled)) jumpstack += private->stacksize * __this_cpu_read(nf_skb_duplicated); e = get_entry(table_base, private->hook_entry[hook]); do { const struct xt_entry_target *t; const struct xt_entry_match *ematch; struct xt_counters *counter; IP_NF_ASSERT(e); /* 匹配IP包,成功则继续匹配下去,否则跳到下一个规则 ip_packet_match匹配标准match, 也就是ip报文中的一些基本的元素,如来源/目的地址,进/出网口,协议等,因为要匹配的内容是固定的,所以具体的函数实现也是固定的。 而IPT_MATCH_ITERATE (应该猜到实际是调用第二个参数do_match函数)匹配扩展的match,如字符串匹配,p2p匹配等,因为要匹配的内容不确定,所以函数的实现也是不一样的,所以do_match的实现就和具体的match模块有关了。 这里的&e->ip就是上面的ipt_ip结构 */ if (!ip_packet_match(ip, indev, outdev, &e->ip, acpar.fragoff)) {//遍历匹配match no_match: e = ipt_next_entry(e); continue; } xt_ematch_foreach(ematch, e) { acpar.match = ematch->u.kernel.match; acpar.matchinfo = ematch->data; if (!acpar.match->match(skb, &acpar)) goto no_match; } counter = xt_get_this_cpu_counter(&e->counters); ADD_COUNTER(*counter, skb->len, 1); /* ipt_get_target获取当前target,t是一个ipt_entry_target结构,这个函数就是简单的返回e+e->target_offset 每个entry只有一个target,所以不需要像match一样遍历,直接指针指过去了*/ t = ipt_get_target(e); IP_NF_ASSERT(t->u.kernel.target); #if IS_ENABLED(CONFIG_NETFILTER_XT_TARGET_TRACE) /* The packet is traced: log it */ if (unlikely(skb->nf_trace)) trace_packet(state->net, skb, hook, state->in, state->out, table->name, private, e); #endif /* 这里都还是和扩展的match的匹配很像,但是下面一句 有句注释:Standard target? 判断当前target是否标准的target? 而判断的条件是u.kernel.target->target,就是ipt_target结构里的target函数是否为空, 而下面还出现了ipt_standard_target结构和verdict变量,好吧,先停下,看看ipt_standard_target结构再说 ipt_standard_target的定义: struct ipt_standard_target { struct ipt_entry_target target; int verdict; }; 也就比ipt_entry_target多了一个verdict(判断),请看前面的nf_hook_slow()函数,里面也有verdict变量, 用来保存hook函数的返回值,常见的有这些 #define NF_DROP 0 #define NF_ACCEPT 1 #define NF_STOLEN 2 #define NF_QUEUE 3 #define NF_REPEAT 4 #define RETURN IPT_RETURN #define IPT_RETURN (-NF_MAX_VERDICT - 1) #define NF_MAX_VERDICT NF_REPEAT 我们知道chain(链)是某个检查点上检查的规则的集合。除了默认的chain外,用户还可以创建新的chain。在iptables中, 同一个chain里的规则是连续存放的。默认的chain的最后一条规则的target是chain的policy。用户创建的chain的最后一条 规则的target的调用返回值是NF_RETURN,遍历过程将返回原来的chain。规则中的target也可以指定跳转到某个用户创建的chain上, 这时它的target是ipt_stardard_target,并且这个target的verdict值大于0。如果在用户创建的chain上没有找到匹配的规则, 遍历过程将返回到原来chain的下一条规则上。事实上,target也是分标准的和扩展的,但前面说了,毕竟一个是条件,一个是动作, target的标准和扩展的关系和match还是不太一样的,不能一概而论,而且在标准的target里还可以根据verdict的值再 划分为内建的动作或者跳转到自定义链简单的说,标准target就是内核内建的一些处理动作或其延伸 扩展的当然就是完全由用户定义的处理动作 */ if (!t->u.kernel.target->target) { int v; v = ((struct xt_standard_target *)t)->verdict; /*v小于0,动作是默认内建的动作,也可能是自定义链已经结束而返回return标志*/ if (v < 0) { /*如果v大于0,记录是跳转偏移量,小于0,是标准target*/ /* Pop from stack? */ if (v != XT_RETURN) { verdict = (unsigned int)(-v) - 1; break; }/* e和back分别是当前表的当前Hook的规则的起始偏移量和上限偏移量,即entry的头和尾,e=back */ if (stackidx == 0) { e = get_entry(table_base, private->underflow[hook]); } else { e = jumpstack[--stackidx]; e = ipt_next_entry(e); } continue; } /* v大于等于0,处理用户自定义链,如果当前链后还有规则,而要跳到自定义链去执行,那么需要保存一个back点, 以指示程序在匹配完自定义链后,应当继续匹配的规则位置,自然地, back点应该为当前规则的下一条规则(如果存在的话) 至于为什么下一条规则的地址是table_base+v, 就要去看具体的规则是如何添加的了 */ if (table_base + v != ipt_next_entry(e) && !(e->ip.flags & IPT_F_GOTO)) jumpstack[stackidx++] = e; e = get_entry(table_base, v); /*根据verdict的偏移量找到跳转的rule*/ continue; } acpar.target = t->u.kernel.target; acpar.targinfo = t->data; /*如果是扩展target,就执行扩展targe的target处理函数*/ verdict = t->u.kernel.target->target(skb, &acpar); /* Target might have changed stuff. */ ip = ip_hdr(skb); if (verdict == XT_CONTINUE) e = ipt_next_entry(e); else /* Verdict */ break; } while (!acpar.hotdrop); xt_write_recseq_end(addend); local_bh_enable(); if (acpar.hotdrop) return NF_DROP; else return verdict; }
filter回调函数 和 match、target之间的关系: