13.windows创建新进程 --- createProcess() 参数为需要执行的程序的位置
Google msdn API可以查找Windows的API
Linux下man(manual手册) API可以查找API使用
linux下 kill 进程id 结束进程
进程间的通信:
消息传递 : 进程 ---> 内核 ---> 进程
一方send一方receive,需要先建立链路
阻塞型、非阻塞型的消息传递
消息在操作系统中的缓存:
无缓冲
有界缓冲
无界缓冲
共享内存 : 进程之间协商(系统调用),划出共享内存(同步问题,有些系统不支持)
int main(void){
int i;
for(i=0;i<3;i++){
fork();
sleep(30);
}
}
对于这个程序,main进程生成三个进程。main的第一个子进程生成2个子进程,第二个子进程生成一个子进程,第三个子进程不生成子进程。
而不是每一个子进程都生成三个子进程。(每次主进程fork之后都会i++,3个子进程中的i值不一样)


运行程序:
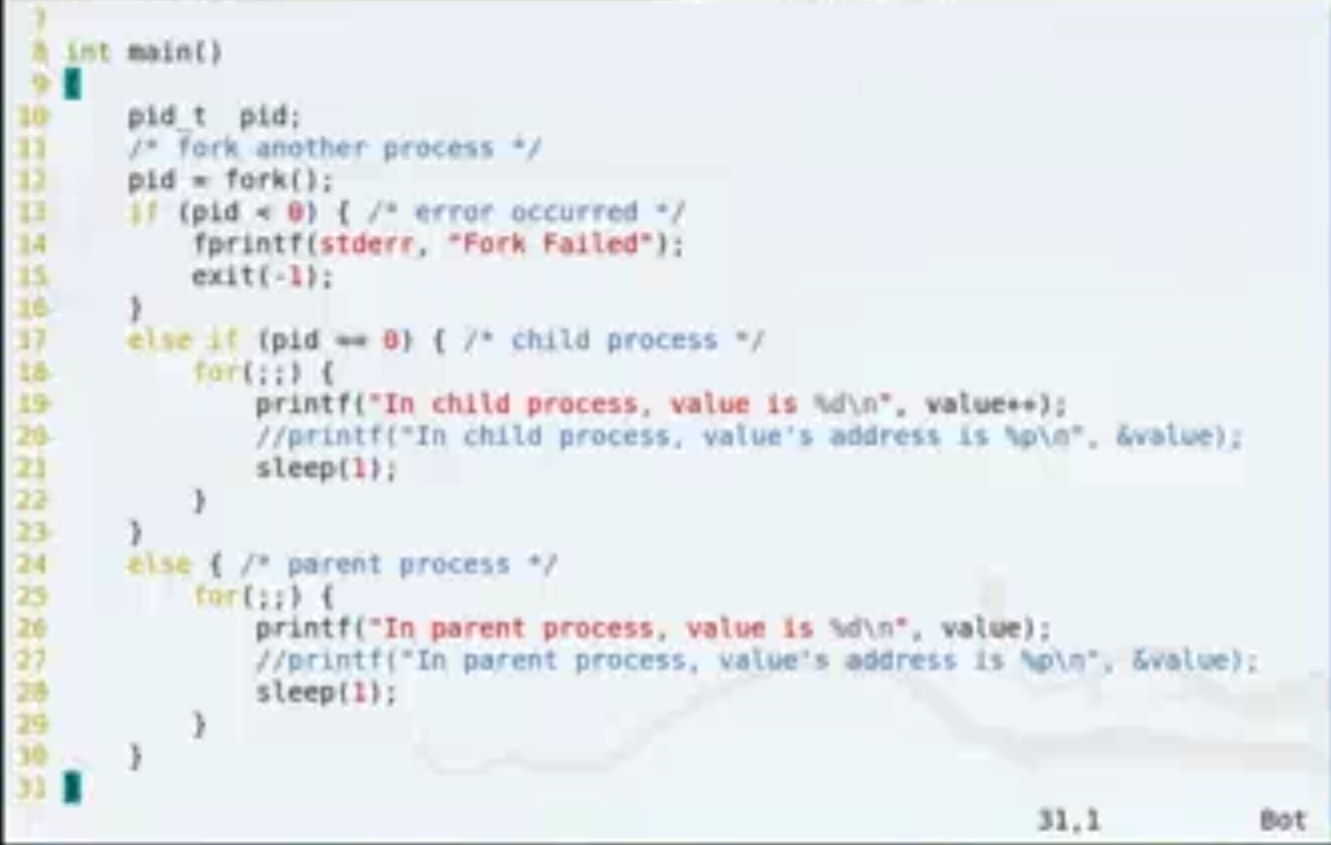
运行结果:子进程和父进程全局变量相互独立
子进程输出递增
父进程一直输出0
父进程和子进程的value的地址是一样的
线程独立拥有:(属于同一进程的线程共享数据文件代码段)
线程ID
PC
寄存器
栈
16.
线程特点:
响应性:
一个进程发起IO操作进入等待状态,此时用户点击窗口,操作系统发起消息但是进程无法响应。对于多线程进程,将IO操作交给新建立的线程。
资源共享,经济实惠,创建进程开销很大:
用户级线程:使用技术模拟出多套寄存器多个PC多个栈(保存现场恢复现场)。
效率高:不涉及内核
可定制性好
缺点:
1.如果任何一个线程调用了阻塞型的系统调用,那么所有线程全部被阻塞
2.不能在多个处理器上运行,在操作系统眼中只是一个线程
内核级线程:内核支持的线程
17
Linux线程实现:
clone()系统调用可以实现fork()和线程
clone参数(标志位):
CLONE_FS子任务和父任务文件系统共享
CLONE_FILES 打开的文件是共享的
CLONE_VM 内存共享
Linux创建线程和进程的区别:
调用fork的时候调用clone没有加CLONE_VM
创建线程的时候加了CLONE_VM参数
这导致在系统看来进程和线程没有区别,线程没有优化(所以把线程叫做轻量级进程)
18.线程模型不稳定,一个线程出问题导致进程崩溃。
19 进程可以分为:
CPU绑定进程
IO绑定进程
CPU调度发生:决定下一个需要运行的进程
调度算法优劣:
CPU利用率
吞吐率:单位时间运行了多少进程
周转时间:进程创建到结束一共多少时间
等待时间:在就绪队列一共过了多少时间
响应时间:事件发生后进程过多少时间才能响应时间
最短作业调度:
抢占式
非抢占式(最短剩余时间优先)
时间片轮转法:分配时间片(固定长度),到时间就等待。从就绪队列中选优先级高的,分配时间片。
如何实现时间片轮转+选择优先级高的 ---- 多级队列
每个进程放到不同优先级的队列中,每次从最高优先级的队列中取进程运行
优先级:
系统进程如中断处理需要及时处理,放在最高优先级
交互式进程(和用户输入输出相关,IO时间较多,使用CPU时间很短,要求快速给用户响应),次优先级
CPU使用较多的进程
现在操作系统常用策略:多级反馈队列(MultiLevel FeedBack Queue)
根据进程之前的行为决定CPU调度
实现:
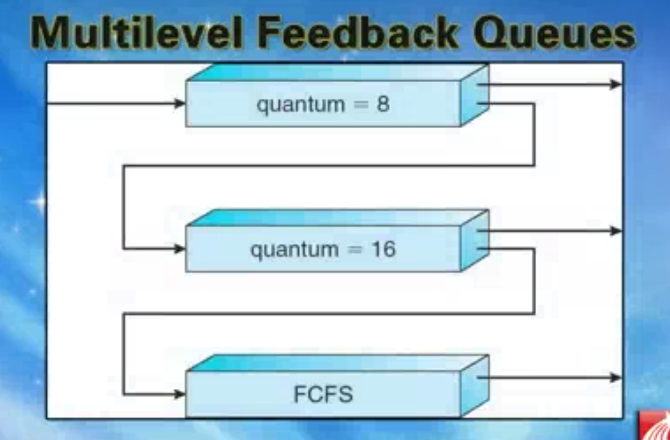
上面两个队列使用时间片轮转法
第三个队列使用先进先出
对于第一个队列的进程CPU分配的时间片为8
所有进程进来(不知道是CPU绑定还是IO绑定的)先放到优先级最高的队列
如果进程一进来就把8个时间片用完了(没有进入IO,CPU绑定型),就把进程放入下一优先级的队列。
如果又用完了16个时间片,那么再往低优先级的放(先进先出队列)
这样可以使CPU绑定型的进程在低优先级,CPU可以快速响应用户输入输出(IO绑定型)
问题:如果一个进程一开始CPU绑定型(IO绑定型)或者相反,会出问题
解决:
不是一次判断而是运行时多次判断,如果进程有任何一次将CPU时间片用完,那么就放入低一级的优先队列
如果低优先级队列中的进程进行了一次IO(从等待状态到就绪状态),就会放入高一级的优先队列。这样的好处是用户IO完后需要CPU尽快处理
多核CPU的调度:更复杂的调度,需要做负载均衡(CPU都忙)
多核CPU有同构和异构(CPU指令、运算速度)
和单核相同:下一个进程选择都是选择优先级高的
不同:有
对称式多处理器管理 (大部分)--- 每一个内核都可能运行进程或者操作系统
每一个CPU都有自己的就绪队列
所有处理器共享就绪队列 --- 如果一个进程从一个CPU切换到另一个CPU,会导致Cache刷新(CPU的缓存不共享)
非对称式多处理器管理:只有一个CPU运行操作系统 --- 对操作系统设计简单很多
亲和性(Affnity ):程序员可以设置进程进入哪个CPU运行
负载均衡:
忙CPUpush到闲CPU中或者闲CPU 从忙CPU pull
两者冲突? -- 》 soft Affnity(一般设置)或者hard Affinity
Solaris举例:(不需要重新编译内核可以修改这个表)
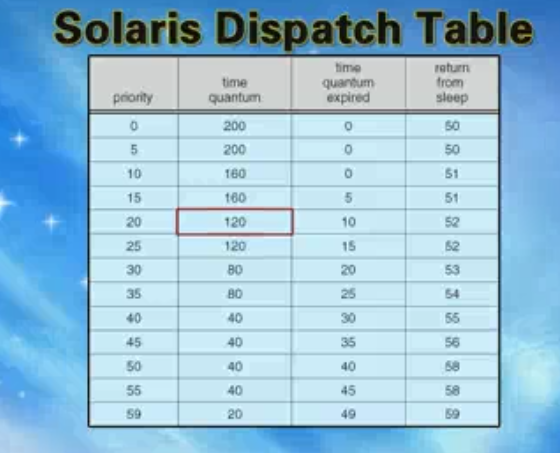
数字越大优先级越大,给的时间片越少
一行解释:20优先级的队列分配120的时间片。时间片用尽进行优先级调整成10(用完了说明是CPU密集型,往更低级的队列里放)
return from sleep : 对应优先级如果进行了IO,从等待态到就绪态的时候优先级变为return from sleep(从IO中被唤醒触发这个操作)
Windows XP调度:
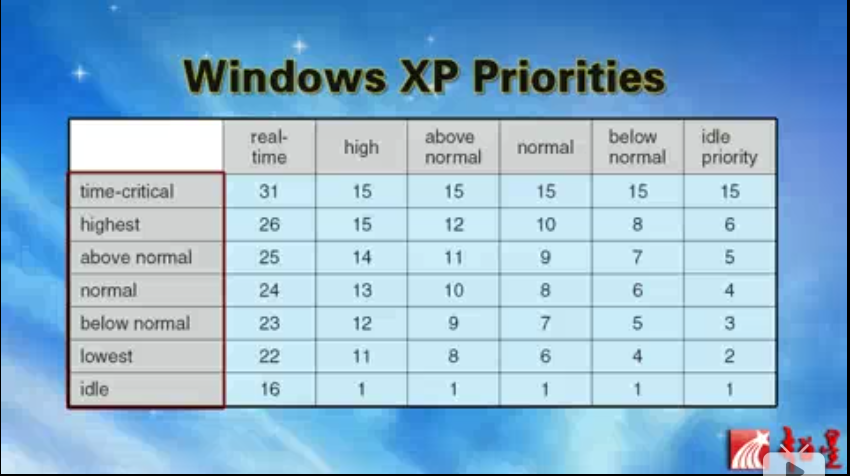
设置优先级的时候需要两个值:
哪一类(时间紧要的,最高的,正常之上的,正常的 等等)
每个类别里还有对时间片渴求程度的区分
比如:
常用进程优先级是8(normal,normal)
在below normal中的time-critical(时间紧迫的)的优先级是15,很高
激活窗口的线程的优先级是原来的
Linux的优先级:(数字越小优先级越高)
Real-time : 0-99
Nice : 100-140

每个优先级有一个队列,每个优先级分配对应的时间片。
一个线程用完时间片就扔到另一个数组的优先级队列中。这样active array数组中的优先级队列中就是时间片没有用完的。通过active和expired切换保证所有线程都有执行的机会
24.进程的同步
rewind(File * f):使文件指针执行文件头部
fopen:打开文件,返回文件指针
25.
临界区:访问共享资源(临界资源)的代码段
进程进入临界区的调度原则是:
1、如果有若干进程要求进入空闲的临界区,一次仅允许一个进程进入。
2、任何时候,处于临界区内的进程不可多于一个。如已有进程进入自己的临界区,则其它所有试图进入临界区的
进程必须等待。
3、进入临界区的进程要在有限时间内退出,以便其它进程能及时进入自己的临界区。
4、如果进程不能进入自己的临界区,则应让出CPU,避免进程出现“忙等待