根据 Webpack 术语表,有两种不同的文件分割类型。它们看起来似乎可以互换,但显然不行:
-
捆绑拆分:创建更多、更小的文件(但每个请求都需要加载它们)以获得更好的缓存效果。
-
代码拆分:动态加载代码,用户只下载他们正在查看的内容所需的代码。
第二种方法看起来更有吸引力,不是吗?事实上,有很多文章似乎都假设这是拆分 JavaScript 文件唯一有价值的方案。但我想要告诉你的是,对于很多网站来说,第一种方法更有价值,而且它应该是你首先要考虑的。
捆绑拆分
捆绑拆分背后的想法非常简单。如果你有一个巨大的文件,哪怕只是修改了一行代码,用户也必须再次下载整个文件。但是,如果你将它分成两个文件,那么用户只需要下载被修改的那个文件,浏览器会从缓存中获取另一个文件。
捆绑拆分与缓存有关,因此对于首次访问网站的用户来说,有没有拆分其实并没有什么不同。
对于频繁访问网站的用户来说,要衡量捆绑拆分所带来的性能提升可能也很棘手,但我们必须这样做!
我需要一个表格来记录性能数据。下面是上述提到的场景:
-
Alice 每周访问我们的网站一次,为期 10 周;
-
我们每周更新一次网站;
-
我们每周都会更新“产品列表”页面;
-
我们还有一个“产品详细信息”页面,目前还未开发出来;
-
在第 5 周,我们添加了一个新的 npm 包;
-
在第 8 周,我们更新了一个现有的 npm 包。
基 线
假设我们的 JavaScript 包大小是 400 KB,只包含 main.js 单个文件。
我们的 Webpack 配置如下(我省略了不相关的配置):
const path = require('path');
module.exports = {
entry: path.resolve(__dirname, 'src/index.js'),
output: {
path: path.resolve(__dirname, 'dist'),
filename: '[name].[contenthash].js',
},
};
每个礼拜,当我们做出一些变更时,这个包的 contenthash 就会发生变化。因此,每周 Alice 访问我们的网站时必须下载新的 400 KB 文件。
我们把这些数字记录在表格中,它看起来就像这样。

下载量总共是 4.12 MB,为期 10 周。
但我们可以做得更好。
拆分 vendor 包
现在,我们将包拆分为 main.js 和 vendor.js 文件。
这很简单:
const path = require('path');
module.exports = {
entry: path.resolve(__dirname, 'src/index.js'),
output: {
path: path.resolve(__dirname, 'dist'),
filename: '[name].[contenthash].js',
},
optimization: {
splitChunks: {
chunks: 'all',
},
},
};
Webpack 4 努力为你做最好的事情,甚至都不需要告诉它你想要如何拆分捆绑包。
有人说,“这样看起来很整洁,不错,Webpack!”
也有人说,“你都对我的包做了什么?”
设置 optimization.splitChunks.chunks ='all'意味着“将 node_modules 所有内容都放入名为 vendors~main.js 的文件中”。
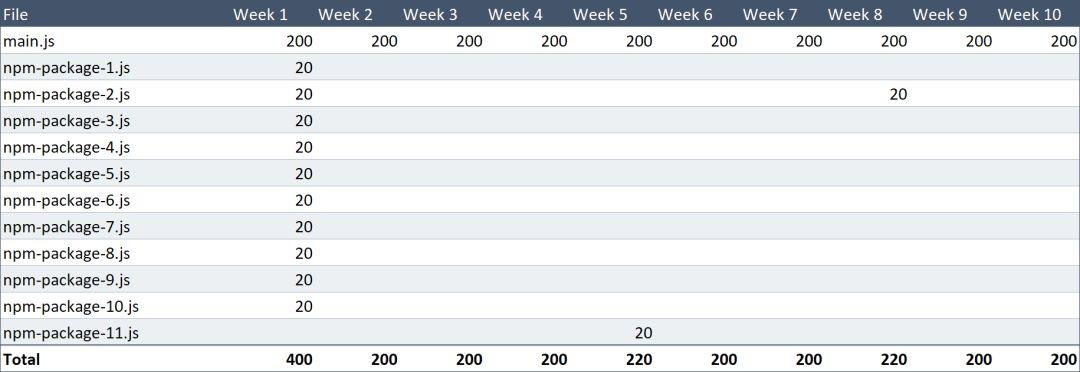
经过这个基本的捆绑拆分,Alice 每次访问网站时仍然需要下载 200 KB 的 main.js 新文件,然后分别在第 1 周,第 8 周和第 5 周下载 200 KB 的 vendor.js 文件。

现在的下载量总共是 2.64 MB。
减少了 36%。在配置中加了五行代码,效果还不错。
这样的性能提升似乎有点微不足道,因为它是 10 周加起来的总和,但不管怎样,向用户发送的字节数确确实实减少了 36%,我们应该为自己感到自豪。
但我们可以做得更好。
拆分每个 npm 包
vendors.js 遇到了与原来 main.js 文件相同的问题——对文件的一部分做出变更就必须重新下载整个文件。
那么为什么不为每个 npm 包提供单独的文件呢?这很容易做到。
所以让我们将 react、lodash、redux 和 moment 等拆分成不同的文件:
const path = require('path');
const webpack = require('webpack');
module.exports = {
entry: path.resolve(__dirname, 'src/index.js'),
plugins: [
new webpack.HashedModuleIdsPlugin(), // so that file hashes don't change unexpectedly
],
output: {
path: path.resolve(__dirname, 'dist'),
filename: '[name].[contenthash].js',
},
optimization: {
runtimeChunk: 'single',
splitChunks: {
chunks: 'all',
maxInitialRequests: Infinity,
minSize: 0,
cacheGroups: {
vendor: {
test: /[\/]node_modules[\/]/,
name(module) {
// get the name. E.g. node_modules/packageName/not/this/part.js
// or node_modules/packageName
const packageName = module.context.match(/[\/]node_modules[\/](.*?)([\/]|$)/)[1];
// npm package names are URL-safe, but some servers don't like @ symbols
return `npm.${packageName.replace('@', '')}`;
},
},
},
},
},
};
Webpack 的文档(https://webpack.js.org/guides/caching/)对此做出了很好的解释,我会大致解释一下 groovy 的部分,因为我在这个上面花了很多时间:
-
Webpack 提供了一些不是那么聪明的默认设置,比如分割输出文件最多为 3 个,最小文件的大小为 30 KB(更小的文件将被连接在一起),所以我覆盖了这些设置。
-
我们通过 cacheGroups 来定义 Webpack 应该如何将代码块分组到输出文件中。在这里我使用了“vendor”,用于处理从 node_modules 加载的模块。通常,你只需将输出文件的 name 定义为字符串,但我将 name 定义为一个函数(在解析每个文件时调用这个函数)。然后我基于模块的路径返回包的名称。因此,对于每个包,我们都会得到一个文件,例如 npm.react-dom.899sadfhj4.js。
-
出于发布的目的,NPM 包名称必须是 URL 安全的(https://docs.npmjs.com/files/package.json#name), 因此我们不需要对 packageName 进行 encodeURI。但是,我遇到一个问题,即.NET 服务器不支持带有 @的文件名,所以我在这个代码片段中将它替换掉。
-
整个设置很棒,不需要额外的维护——我不需要引用任何包。
Alice 每周仍然会重新下载 200 KB 的 main.js 文件,并且在她第一次访问网站时仍然会下载 200 KB 的 npm 软件包,但她绝不会下载相同的软件包两次。
现在的下载总量是 2.24 MB,与基线相比减少了 44%。
我在想是否有可能减少 50%?
拆分应用程序代码
现在让我们回到可怜的 Alice 一次又一次下载的 main.js 文件。
我之前提到过,我们的网站上有两个截然不同的部分:产品列表页面和产品详细信息页面。每个部分不一样的代码为 25 KB(共享代码为 150 KB)。
“产品详细信息”页面现在并没有发生太大变化,因此,如果我们将其变为单独的文件,大多数时候可以从缓存中获取它。
另外,我们有一个巨大的内联 SVG 文件用于渲染图标,大小为 25 KB,而且很少会发生改动。
我们应该对此做些什么。
我们手动添加了一些条目,告诉 Webpack 为每一项创建一个文件。
module.exports = { entry: { main: path.resolve(__dirname, 'src/index.js'), ProductList: path.resolve(__dirname, 'src/ProductList/ProductList.js'), ProductPage: path.resolve(__dirname, 'src/ProductPage/ProductPage.js'), Icon: path.resolve(__dirname, 'src/Icon/Icon.js'), }, output: { path: path.resolve(__dirname, 'dist'), filename: '[name].[contenthash:8].js', }, plugins: [ new webpack.HashedModuleIdsPlugin(), // so that file hashes don't change unexpectedly ], optimization: { runtimeChunk: 'single', splitChunks: { chunks: 'all', maxInitialRequests: Infinity, minSize: 0, cacheGroups: { vendor: { test: /[\/]node_modules[\/]/, name(module) { // get the name. E.g. node_modules/packageName/not/this/part.js // or node_modules/packageName const packageName = module.context.match(/[\/]node_modules[\/](.*?)([\/]|$)/)[1]; // npm package names are URL-safe, but some servers don't like @ symbols return `npm.${packageName.replace('@', '')}`; }, }, }, }, }, };
Webpack 还会为 ProductList 和 ProductPage 之间共享的内容创建文件,这样我们就不会得到重复的代码。
这样就可以为亲爱的 Alice 节省 50 KB 的下载量。
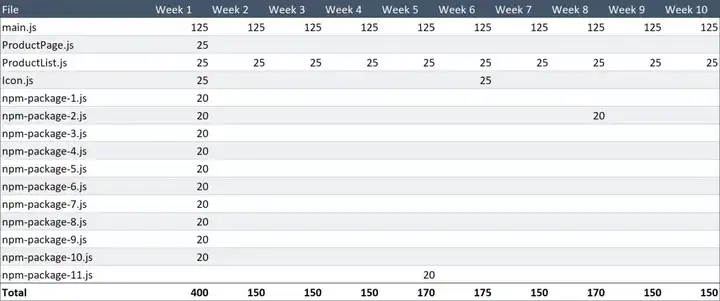
现在的总下载量只有 1.815 MB!
我们已经为 Alice 节省了高达 56%的下载量,在我们的理论场景中,这种情况可以一直持续下去。
截止到目前,我们只是通过修改 Webpack 配置来实现这一切——我们没有对应用程序代码进行任何更改。
我们的目标是将应用程序拆分为合理的小文件,让用户下载更少的代码。
因此,接下来我们要进入代码拆分,但首先我想要解决你现在想到的三个问题。问题 1:大量的网络请求不是更慢吗?
对于这个问题,答案是一个非常响亮的“不”。
在 HTTP/1.1 时代或许是这种情况,但对于 HTTP/2 来说并非如此。
尽管一些著名的文章得出“即使使用 HTTP/2,下载太多文件仍然较慢”的结论,但在这些文章中,他们所谓的“太多”文件是指“数百个”文件。所以请记住,如果你有数百个文件,可能会达到并发上限。
问题 2:每个 Webpack 捆绑包中不是有样板代码?
是的。
问题 3:如果有多个小文件,不就失去了压缩的优势了吗?
是的。
好吧,这就是说:
-
更多文件 = 更多的 Webpack 样板代码;
-
更多文件 = 更少的压缩。
接下来让我们做一下量化,这样就可以确切地知道性能被磨损了多少。
我做了一个测试,将 190KB 的文件拆分成 19 个小文件,这样发送给浏览器的总字节数大约增加了 2%。
在第一次访问时增加 2%,但在以后访问可以减少 60%,所以可以说完全没有磨损。
我针对 1 个文件和 19 个文件分别进行了测试,并基于不同的网络,包括 HTTP/1.1。
这是结果表格,我想这足以说明“更多文件会更好”:
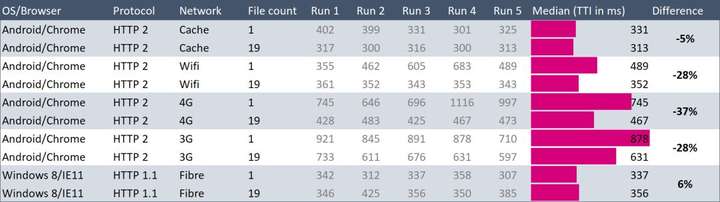
在 3G 和 4G 网络上,当有 19 个文件时,总的加载时间缩短了 30%。
当然,这些数据带有一定的噪音。例如,第二次在 4G 网络上的加载时间为 646 毫秒,过了两次之后需要 1116 毫秒——多了 73%。因此,声称 HTTP/2“快 30%”似乎有点心虚的感觉。
我制作这张表来是想要量化 HTTP/2 的差异,但看来我唯一能说的是“它可能没有显著差异”。
真正的惊喜是最后两行,我原本认为旧的 Windows 和 HTTP/1.1 会很慢。
这就是我要说的有关捆绑拆分的一切。我认为这种方法的唯一缺点是要不断地说服人们,加载大量小文件是没有问题的。
现在,让我们谈谈另一种类型的文件拆分。
代码拆分(不加载不需要的代码)
这种方法可能只对某些网站有用。
我发明了 20/20 规则:如果你的网站的某些部分只有 20%的用户访问,而这部分超过了整个网站 20%的 JavaScript,那么你应该按需加载这些代码。
显然,因为存在更复杂的场景,所以这个数字显然需要做出调整。但关键在于,肯定存在一个平衡点,到了这个平衡点,代码拆分对于你的网站来说可能就没有意义了。
如何找到这个平衡点?
假设你有一个购物网站,你想知道是否应该对“结帐”代码进行拆分,因为只有 30%的用户会进行这个操作。
你需要弄清楚有多少代码是只与结账这个功能有关的。因为在进行“代码拆分”之前已经进行了“捆绑拆分”,因此你可能已经知道这部分究竟有多少代码。
只与结帐有关的代码是 7 KB,其余部分是 300 KB。看到这个我会说,我不会想去拆分这个代码,原因如下:
-
预先加载它并不慢,因为你是并行加载这些文件的。而且你可以试试是否有可能记录 300 KB 和 307 KB 加载时间的差异。
-
如果你稍后加载这段代码,用户在点击“Take My Money”后将不得不等待加载这个文件——这是你最不想遇到摩擦阻力的时候。
-
进行代码拆分需要更改应用程序代码。它会在以前只有同步逻辑的地方引入异步逻辑。这不是火箭科学,但它的复杂性,我认为应该通过对用户体验可感知的改进来证明。。
现在让我们来看看两个需要代码拆分的例子。
更多前端学习内容文章干货请关注我的知乎专栏(不断更新),以后有新文章会提醒您,下面的链接是我知乎文章的集合,我把所有重要的文章放在这个目录里面,供大家阅读,希望能对大家有用
阿里名厂标准web前端高级工程师教程目录大全,从基础到进阶,看完保证您的薪资上升一个台阶
我之所以从这里开始讲起,是因为它适用于大多数网站,而且介绍起来相对简单。
我在网站上使用了很多花哨的功能,有一个文件导入了所有需要的 polyfill。其中包括以下八行:
require('whatwg-fetch');
require('intl');
require('url-polyfill');
require('core-js/web/dom-collections');
require('core-js/es6/map');
require('core-js/es6/string');
require('core-js/es6/array');
require('core-js/es6/object');
我在 index.js 的顶部导入了这个文件。
import './polyfills'; import React from 'react'; import ReactDOM from 'react-dom'; import App from './App/App'; import './index.css'; const render = () => { ReactDOM.render(<App />, document.getElementById('root')); } render(); // yes I am pointless, for now
根据之前的捆绑拆分的 Webpack 配置,polyfill 将自动被拆分为四个不同的文件,因为这里有四个 npm 包。它们总共约 25 KB,但 90%的浏览器都不需要它们,所以有必要进行动态加载。
使用 Webpack 4 和 import() 语法(不要与 import 语法混淆)可以很方便地实现 polyfill 的条件加载。
import React from 'react'; import ReactDOM from 'react-dom'; import App from './App/App'; import './index.css'; const render = () => { ReactDOM.render(<App />, document.getElementById('root')); } if ( 'fetch' in window && 'Intl' in window && 'URL' in window && 'Map' in window && 'forEach' in NodeList.prototype && 'startsWith' in String.prototype && 'endsWith' in String.prototype && 'includes' in String.prototype && 'includes' in Array.prototype && 'assign' in Object && 'entries' in Object && 'keys' in Object ) { render(); } else { import('./polyfills').then(render); }
如果浏览器支持所有功能,那么就渲染页面,否则的话就导入 polyfill,然后渲染页面。在浏览器中运行这些代码时,Webpack 的运行时将负责加载这四个 npm 包,在下载和解析它们之后,将调用 render()……
顺便说一句,要使用 import(),需要 Babel 的 dynamic-import 插件 (https://babeljs.io/docs/en/babel-plugin-syntax-dynamic-import/)。 另外,正如 Webpack 文档解释的那样,import() 使用了 promise,所以你需要单独对其进行 polyfill。
这个很简单,对吗?下面来点稍微有难度的。
基于路由的动态加载(特定于 React)
回到 Alice 的例子,我们假设网站有一个“管理”功能,卖家可以登录并管理他们的商品。
这部分有很多精彩的功能,大量的图表,需要很多 npm 大图表库。因为已经在进行了捆绑拆分,所以它们都是 100 KB 左右的文件。
目前,我的路由设置是当用户访问 /admin 时,将会渲染<AdminPage>。当 Webpack 将所有内容捆绑在一起时,它会找到 import AdminPage from ./AdminPage.js,然后说,“我需要将它包含在初始化代码中”。
但我们不希望它这样。我们需要使用动态导入,例如 import(‘/AdminPage.js’),这样 Webpack 就知道要进行动态加载了。
这很酷,不需要做任何配置。
因此,我可以创建另一个组件,当用户访问 /admin 时就会渲染这个组件,而不是直接引用 AdminPage。它看起来可能像这样:
import React from 'react'; class AdminPageLoader extends React.PureComponent { constructor(props) { super(props); this.state = { AdminPage: null, } } componentDidMount() { import('./AdminPage').then(module => { this.setState({ AdminPage: module.default }); }); } render() { const { AdminPage } = this.state; return AdminPage ? <AdminPage {...this.props} /> : <div>Loading...</div>; } } export default AdminPageLoader;
这个概念很简单。在加载这个组件时(意味着用户在访问 /admin),我们将动态加载./AdminPage.js,然后在 state 中保存对该组件的引用。
在等待<AdminPage>加载时,我们只是在 render() 方法中渲染<div> Loading... </div>,或者在加载完成时渲染<AdminPage>,并保存在 state 中。
我自己这样做是为了好玩,但在现实世界中,你可以使用 react-loadable,正如 React 文档(https://reactjs.org/docs/code-splitting.html) 中关于代码拆分的描述那样。
以上就是所有我想说的话,简单地说就是: