什么是过拟合
过拟合,指的是模型在训练集上表现的很好,但是在交叉验证集合测试集上表现一般,也就是说模型对未知样本的预测表现一般,泛化(generalization)能力较差。通俗一点地来说过拟合就是模型把数据学习的太彻底,以至于把噪声数据的特征也学习到了。
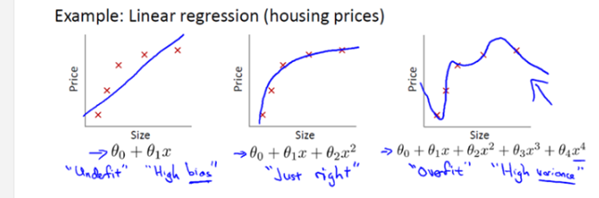
(图片来源:coursera 吴恩达机器学习公开课)
从图中可以看出,图一是欠拟合,模型不能很好地拟合数据;图二是最佳的情况;图三就是过拟合,采用了很复杂的模型。最后导致曲线波动很大,最后最可能出现的结果就是模型对于未知样本的预测效果很差。
产生的原因
- 训练数据不够
- 对模型进行过度训练(overtraining)
解决方法
Early stopping
在机器学习算法中,我们常常将原始数据集分为三部分:training data、validation data,testing data。其中validation data就是用来避免过拟合的,在训练过程中,我们通常用它来确定一些超参数(比如根据validation data上的accuracy来确定early stopping的epoch大小、根据validation data确定learning rate等等)。那为啥不直接在testing data上做这些呢?因为如果在testing data做这些,那么随着训练的进行,我们的网络实际上就是在一点一点地overfitting我们的testing data,导致最后得到的testing accuracy没有任何参考意义。
Early stopping便是一种迭代次数截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。对模型进行训练的过程即是对模型的参数进行学习更新的过程,这个参数学习的过程往往会用到一些迭代方法,如梯度下降(Gradient descent)学习算法。这样可以有效阻止过拟合的发生,因为过拟合本质上就是对自身特点过度地学习。
正则化
指的是在目标函数后面添加一个正则化项,一般有L1正则化与L2正则化。L1正则是基于L1范数,即在目标函数后面加上参数的L1范数和项,即参数绝对值和与参数的积项
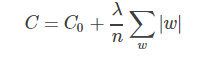
L2正则是基于L2范数,即在目标函数后面加上参数的L2范数和项,即参数的平方和与参数的积项:

个人感觉这是一种对过度学习的惩罚,增加了一些噪声就减小了过度学习。
数据增强
在神经网络中,数据增强只意味着增加数据规模
是一种通过让有限的数据产生更多的等价数据来人工扩展训练数据集的技术。它是克服训练数据不足的有效手段,目前在深度学习的各个领域中应用广泛。但是由于生成的数据与真实数据之间的差异,也不可避免地带来了噪声问题。
下面列举了一些NLP中数据增强的方法
同义词词典(Thesaurus):Zhang Xiang等人提出了Character-level Convolutional Networks for Text Classification,通过实验,他们发现可以将单词替换为它的同义词进行数据增强,这种同义词替换的方法可以在很短的时间内生成大量的数据。
随机插入(Randomly Insert):随机选择一个单词,选择它的一个同义词,插入原句子中的随机位置,举一个例子:“我爱中国” —> “喜欢我爱中国”。
随机交换(Randomly Swap):随机选择一对单词,交换位置。
随机删除(Randomly Delete):随机删除句子中的单词。
语法树结构替换:通过语法树结构,精准地替换单词。
加噪(NoiseMix) (https://github.com/noisemix/noisemix):类似于图像领域的加噪,NoiseMix提供9种单词级别和2种句子级别的扰动来生成更多的句子,例如:这是一本很棒的书,但是他们的运送太慢了。->这是本很棒的书,但是运送太慢了。
情境增强(Contextual Augmentation):这种数据增强算法是用于文本分类任务的独立于域的数据扩充。通过用标签条件的双向语言模型预测的其他单词替换单词,可以增强监督数据集中的文本。
生成对抗网络:利用生成对抗网络的方法来生成和原数据同分布的数据,来制造更多的数据。在自然语言处理领域,有很多关于生成对抗网络的工作:
Generating Text via Adversarial Training
GANS for Sequences of Discrete Elements with the Gumbel-softmax Distribution
SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient
回译技术(Back Translation):回译技术是NLP在机器翻译中经常使用的一个数据增强的方法。其本质就是快速产生一些翻译结果达到增加数据的目的。回译的方法可以增加文本数据的多样性,相比替换词来说,有时可以改变句法结构等,并保留语义信息。但是,回译的方法产生的数据严重依赖于翻译的质量。
扩句-缩句-句法:先将句子压缩,得到句子的缩写,然后再扩写,通过这种方法生成的句子和原句子具有相似的结构,但是可能会带来语义信息的损失。
无监督数据扩增(Unsupervised Data Augmentation):通常的数据增强算法都是为有监督任务服务,这个方法是针对无监督学习任务进行数据增强的算法,UDA方法生成无监督数据与原始无监督数据具备分布的一致性,而以前的方法通常只是应用高斯噪声和Dropout噪声(无法保证一致性)。(https://arxiv.org/abs/1904.12848)
此外,这个仓库(https://github.com/quincyliang/nlp-data-augmentation)中介绍了一些自然语言处理中的数据增强技术。
总结
数据增强是增大数据规模,减轻模型过拟合的有效方法,但是,数据增强不能保证总是有利的。在数据非常有限的域中,这可能导致进一步过度拟合。因此,重要的是要考虑搜索算法来推导增强数据的最佳子集,以便训练深度学习模型。
DropOut
在神经网络中,有一种方法是通过修改神经网络本身结构来实现的,其名为Dropout。该方法是在对网络进行训练时用一种技巧(trick),对于如下所示的三层人工神经网络:

对于上图所示的网络,在训练开始时,随机得删除一些(可以设定为一半,也可以为1/3,1/4等)隐藏层神经元,即认为这些神经元不存在,同时保持输入层与输出层神经元的个数不变,这样便得到如下的ANN:
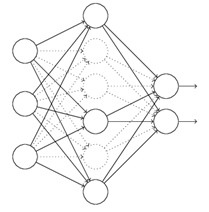
然后按照BP学习算法对ANN中的参数进行学习更新(虚线连接的单元不更新,因为认为这些神经元被临时删除了)。这样一次迭代更新便完成了。下一次迭代中,同样随机删除一些神经元,与上次不一样,做随机选择。这样一直进行下去,直至训练结束。
个人感觉这是对模型的简化,过拟合可能因为模型太过复杂,通过这种方式化简模型的复杂度。
参考
https://blog.csdn.net/lqz790192593/article/details/83045114
https://blog.csdn.net/weixin_39913518/article/details/106907510