网站后台扫描工具都是利用后台目录字典进行爆破扫描,字典越多,扫描到的结果也越多。常用的网站后台扫描工具wwwscan、御剑、dirbuster和cansina,不管哪个工具,要想扫描到更多的东西,都必须要有一个强大的目录字典!
在以下几个工具中,我个人认为 dirbuster扫描的信息会比其他几个工具多很多!
wwwscan
wwwscan是一款网站后台扫描工具,简单好用又强大。它有命令行和图形界面两种。
使用方法也很简单,下面讲一下命令行的用法。
wwwscan.exe options ip/域名
-p :设置端口号
-m :设置最大线程数
-t :设置超时时间
-r :设置扫描的起始目录
-ssl:是否使用SSL
例:
wwwscan.exe www.baidu.com -p 8080 -m 10 -t 16
wwwscan.exe www.baiadu.com -r "/test/" -p 80
wwwscan.exe www.baidu.com –ssl

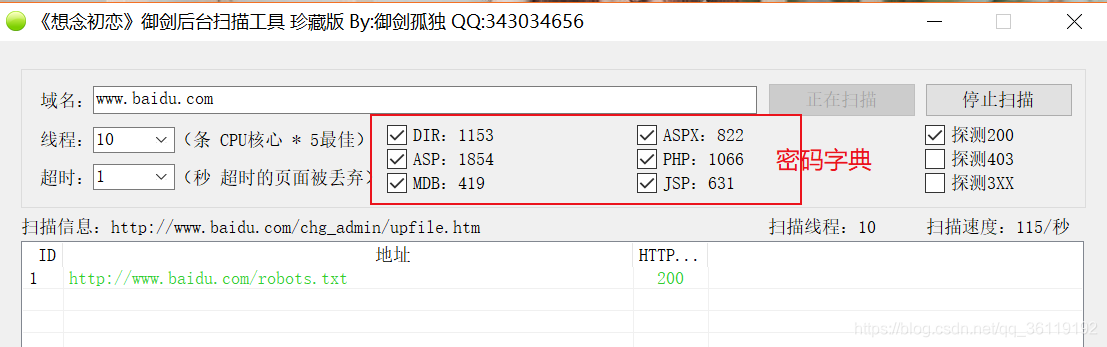
御剑
御剑也是一款好用的网站后台扫描工具,图形化页面,使用起来简单上手。
dirbuster
DirBuster是Owasp(Open Web Application Security Project )开发的一款专门用于探测网站目录和文件(包括隐藏文件)的工具。由于使用Java编写,电脑中要装有JDK才能运行。
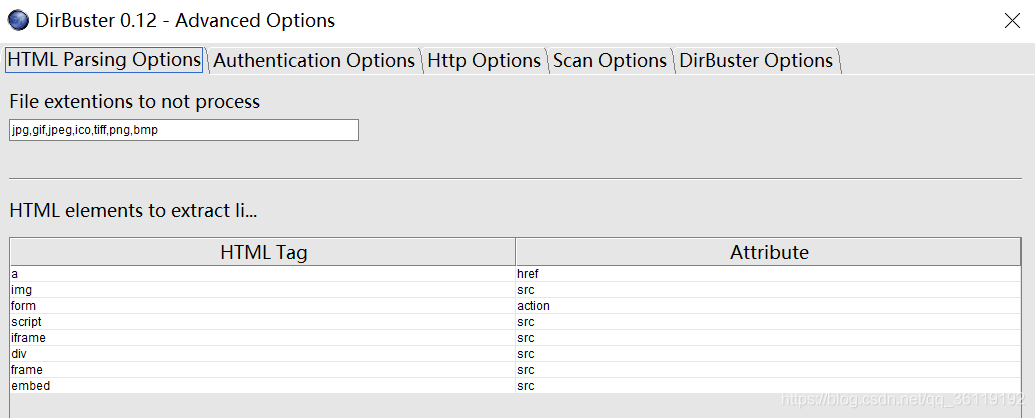
配置
点击Options—Advanced Options打开如下配置界面
在这里可以设置不扫描文件类型,设置遇到表单自动登录,增加HTTP头(Cookie……),
以及代理设置,超时链接设置,默认线程,字典,扩展名设置
开始扫描:
扫描完成之后,查看扫描结果。可以树状显示,也可以直接列出所有存在的页面

cansina
Cansina是用python写的一款探测网站的敏感目录和内容的安全测试工具,其具有如下特点:
多线程
HTTP/S 代理支持
数据持久性 (sqlite3)
多后缀支持 (-e php,asp,aspx,txt…)
网页内容识别 (will watch for a specific string inside web page content)
跳过假404错误
可跳过被过滤的内容
报表功能
基础认证
常见参数及用法
-u:目标url地址
-p:指定字典文件
-b:禁止的响应代码如果 404 400 500
-e:只扫php或asp或aspx扩展。
-c:在网页中查找一些关键字。也可以添加多个关键字。
-d:就是查看文件中是否有要找的字符,如果没有将自动返回404特征码。
-D:自动检查并返回特定的404 200等
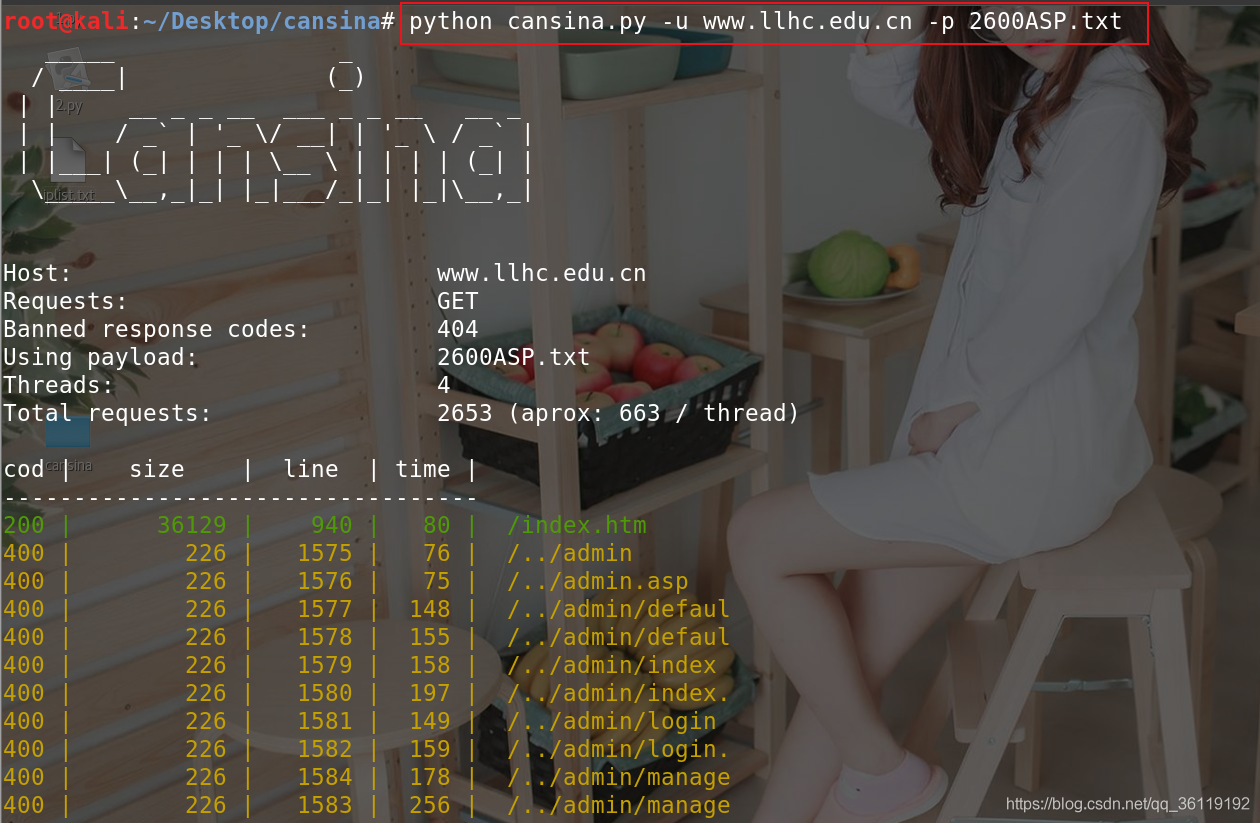
常规扫描:python cansina.py -u www.baidu.com -p key.txt
自定义文件类型扫描:python cansina.py -u www.baidu.com -p key.txt -e php
特定内容扫描:python cansina.py -u www.baidu.com -p key.txt -c admin
本文相关软件:https://pan.baidu.com/s/1fNpTmxW2Wia8g6_-Fo6vTQ 提取码: dyfx
————————————————
版权声明:本文为CSDN博主「谢公子」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_36119192/article/details/84064511