基于 Python 3.6.2 的 Scrapy 爬虫框架使用,Scrapy 的爬虫实现过程请参照本人的另一篇博客:Python3 爬虫之 Scrapy 核心功能实现(二)
一、初识 Scrapy
Scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取(更确切来说, 网络抓取)所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services)或者通用的网络爬虫。
二、Scrapy 环境搭建
所需环境:
1. 安装 Python 3.6,本文使用 Python 3.6,且在 PATH 中设置好环境变量,当然也可以选择2.7的版本,但有一点需要明确,Python 3.x 和 2.x 互不兼容,安装好之后输入如下命令:python --version,下载地址:https://www.python.org/downloads/
2. 安装 pywin32-221,根据上面安装的 Python 的位数,32 位或 64 位来决定 pywin32的版本,本文使用 pywin32-221.win-amd64-py3.6.exe,下载地址:https://sourceforge.net/projects/pywin32/files/pywin32/
3. 安装 pip 9.0.1(pip 是 Python 通用的包管理工具,提供对 Python 包的查找、下载、安装和卸载),首先需要下载 get-pip.py 文件,下载地址:https://bootstrap.pypa.io/get-pip.py,下载到本地之后,根据该文件所在路径,执行下面的命令:python G:myHadoopscrapyget-pip.py,执行成功之后便会安装好 pip,并且同时帮你安装了setuptools,安装完了之后在命令行中执行命令:pip --version

4. 安装 pyOpenSSL-17.5.0,通过 pip 安装 OpenSSL:pip install pyOpenSSL,也可以自行下载对应版本的 pyOpenSSL,下载地址:https://launchpad.net/pyopenssl
5. 安装 lxml-4.1.1(lxml 一种使用 Python 编写的库,可以迅速、灵活地处理 XML,如需详细了解,可参考:http://lxml.de/),通过 pip 安装 lxml:pip install lxml
6. 安装 zope.interface-4.4.3,通过 pip 安装 zope.interface:pip install zope.interface
7. 安装 Twisted-17.9.0,通过 pip 安装 twisted:pip install twisted
直接使用 pip install twisted 时,如果发现如下错误:

可到如下网站中 https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted,找到需要的版本下载到本地:
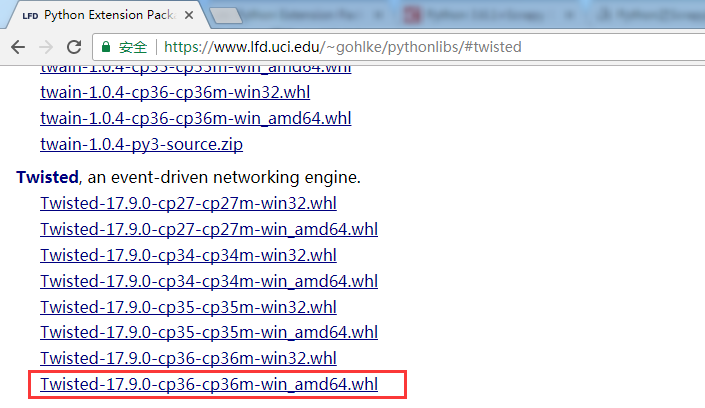
放入执行命令的文件夹中,然后执行命令:pip install Twisted-17.9.0-cp36-cp36m-win_amd64.whl
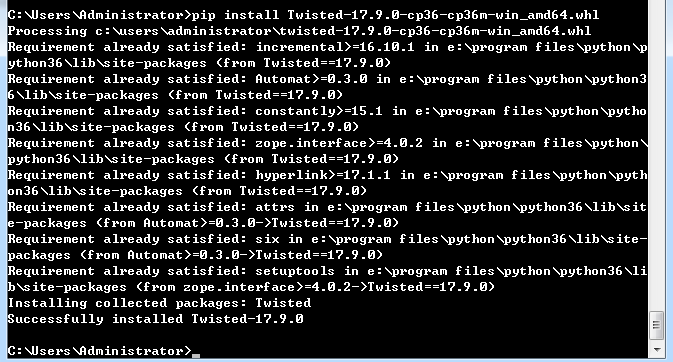
以上依赖的组件安装之后验证scrapy依赖项是否安装成功的方法:
cmd 执行 python 进入 python 控制台
- 执行 import lxml,如果没报错,则说明lxml安装成功;
- 执行 import twisted,如果没报错,则说明twisted安装成功;
- 执行 import OpenSSL,如果没报错,则说明OpenSSL安装成功;
- 执行 import zope.interface,如果没报错,则说明zope.interface安装成功;
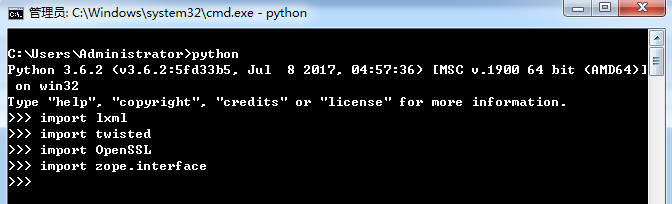
以上依赖项均安装成功,然后安装 Scrapy。
8. 安装 Scrapy-1.4.0,通过 pip 安装 Scrapy:pip install Scrapy
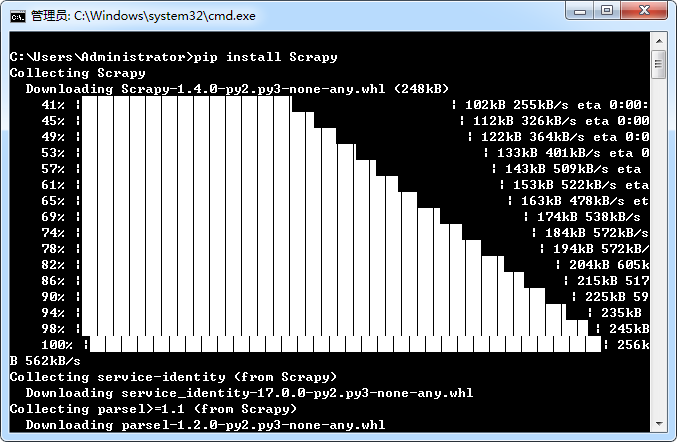
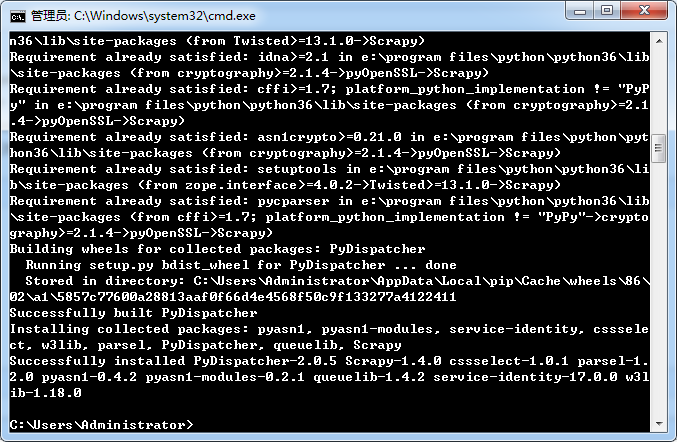
验证下是否安装成功: scrapy version

如果在使用中发现 Scrapy 爬虫版本偏低,可以使用如下命令升级:
pip install --upgrade scrapy
安装成功!!!!