1. 应用K-means算法进行图片压缩
读取一张图片
观察图片文件大小,占内存大小,图片数据结构,线性化
用kmeans对图片像素颜色进行聚类
获取每个像素的颜色类别,每个类别的颜色
压缩图片生成:以聚类中收替代原像素颜色,还原为二维
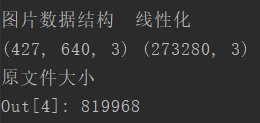
观察压缩图片的文件大小,占内存大小
2. 观察学习与生活中可以用K均值解决的问题。
从数据-模型训练-测试-预测完整地完成一个应用案例。
这个案例会作为课程成果之一,单独进行评分。
1、图片压缩
(1)读取一张图片

显示压缩前的照片

(2)观察图片文件大小,占内存大小,图片数据结构,线性化
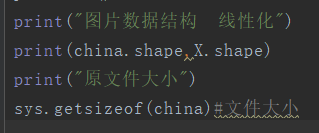
(3)压缩图片生成
观察压缩图片的文件大小,占内存大小

显示压缩后的照片
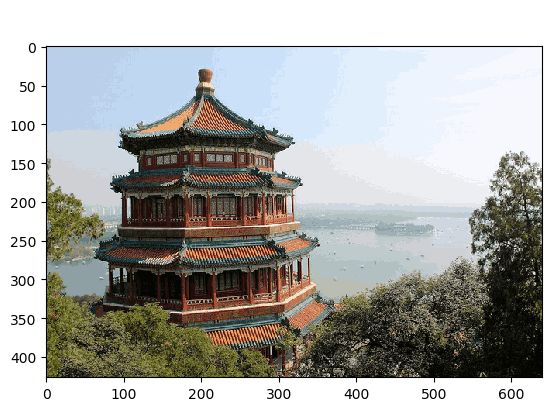
显示第二次压缩后的照片


2、观察学习与生活中可以用K均值解决的问题。
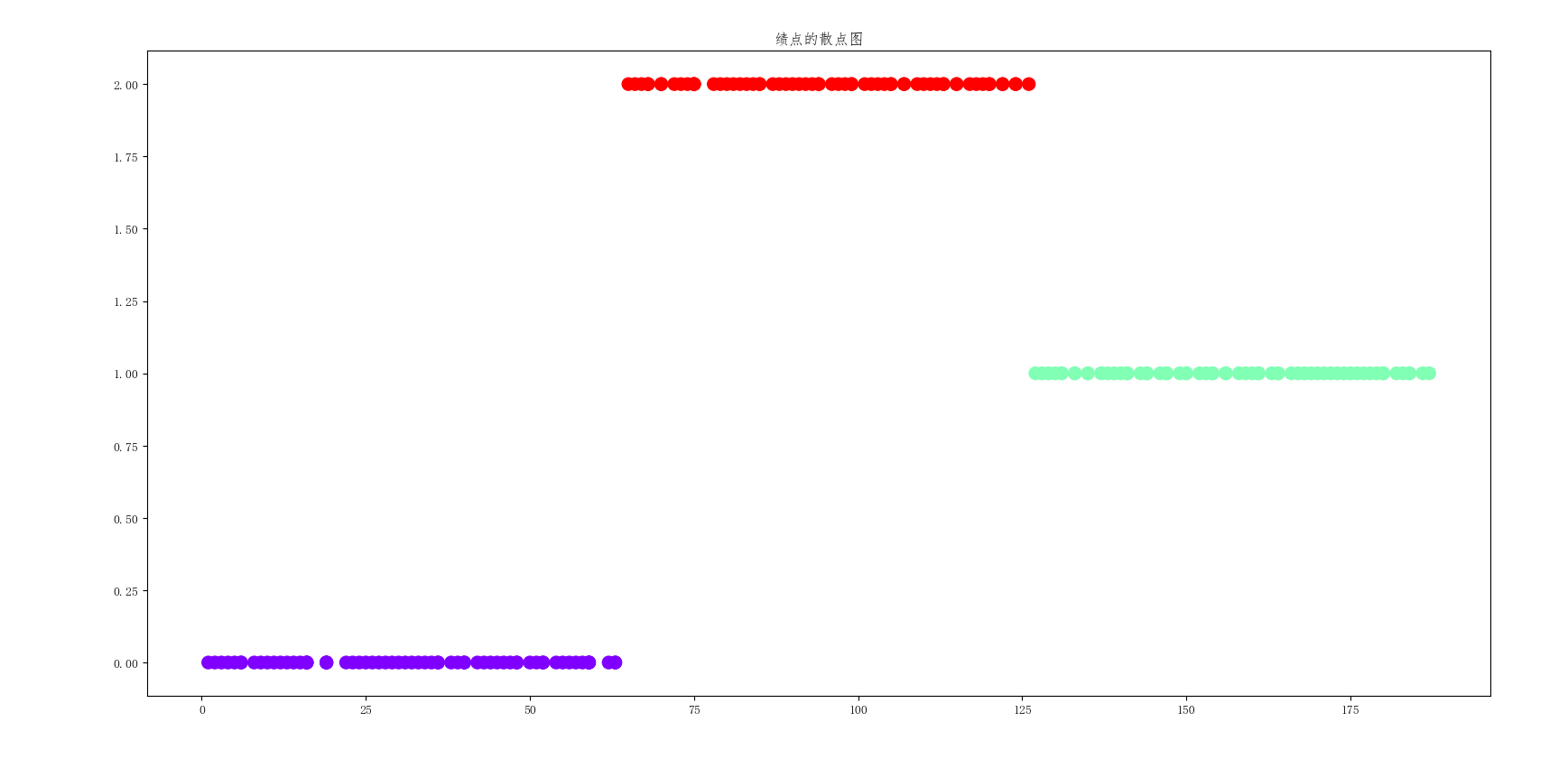
用来分类我们的绩点高低,分五类。使用sklearn库的kmeans函数进行预测。画出散点图,或者把名字显示出来,更好观察学生的学习情况。

散点图
显示分类数据的代码截图,数据在这里就不展示了
代码如下:
#2. 观察学习与生活中可以用K均值解决的问题。
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
path = r'.jidian.xlsx'#导入表
df = pd.read_excel(path)
score = np.array(df.iloc[:,7])#选数据
X =score.reshape(-1,1)
ests = KMeans(n_clusters=5)
ests.fit(X)#训练
y_kmeans = ests.predict(X)#评估分类
y_kmeans
#散点图
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['FangSong'] # 指定默认字体
plt.scatter(score,y_kmeans,c=y_kmeans,s=100,cmap='rainbow')
plt.title("绩点的散点图")
plt.show()
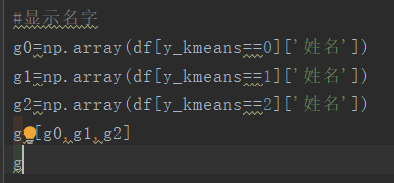
#显示名字
g0=np.array(df[y_kmeans==0]['姓名'])
g1=np.array(df[y_kmeans==1]['姓名'])
g2=np.array(df[y_kmeans==2]['姓名'])
g=[g0,g1,g2]
g