所谓风格迁移,其实就是提供一幅画(Reference style image),将任意一张照片转化成这个风格,并尽量保留原照的内容(Content)。之前比较火的修图软件Prisma就提供了这个功能。我觉得这一说法可以改成风格迁移,将一张图的风格迁移到另一张图片上,也可以理解为生成问题,根据两种图片,生成第三种(风格)图片,具体看怎么理解怎么做吧(不喜勿喷,纯个人观点)。比如下图,把一张图片的风格“迁移”到另一张图片上:

论文地址:https://arxiv.org/pdf/1508.06576v2.pdf 然而,原始的风格迁移的速度是非常慢的。在GPU上,生成一张图片都需要10分钟左右,而如果只使用CPU而不使用GPU运行程序,甚至需要几个小时。这个时间还会随着图片尺寸的增大而迅速增大。这其中的原因在于,在原始的风格迁移过程中,把生成图片的过程当做一个“训练”的过程。每生成一张图片,都相当于要训练一次模型,这中间可能会迭代几百几千次。如果你了解过一点机器学习的知识,就会知道,从头训练一个模型要比执行一个已经训练好的模型要费时太多。而这也正是原始的风格迁移速度缓慢的原因。(出处:https://zhuanlan.zhihu.com/p/24383274)
几种模型汇总一下:
1、可以理解为生成模型:
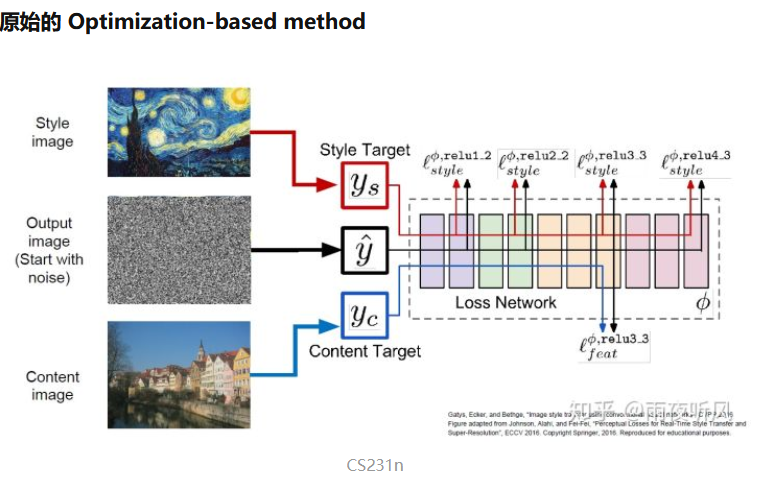
简单来说便是输入一张随机噪音构成的底图,通过计算Style Loss和Content Loss,迭代update底图,使其风格纹理上与Style Image相似,内容上与原照片相似。正常的训练过程是通过loss反向传播更新网络参数,这里则是用一个已经训练好的VGG16作为backbone,锁住参数,更新输入的底图。具体的Style Loss和Content Loss计算过程可以参考:https://zhuanlan.zhihu.com/p/57564626,这种模型的缺点就是慢。
2、一次成型的Feedforward-based method
论文地址:https://link.zhihu.com/?target=https%3A//arxiv.org/pdf/1603.08155.pdf
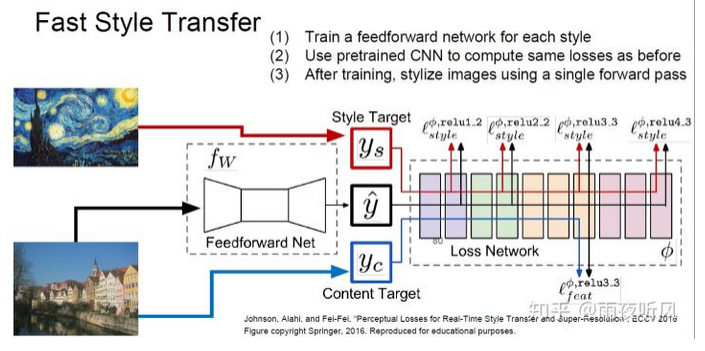
也是比较直接的一个想法,增加了一个Autoencoder形状的Feedforward Net 来拟合风格迁移的过程。仍然是之前的Content Loss+Style loss,用另一个网络来计算并统一在一起称之为 Perceptual Loss。
3、One network, multiple styles
论文地址:https://link.zhihu.com/?target=https%3A//arxiv.org/pdf/1703.09210.pdf
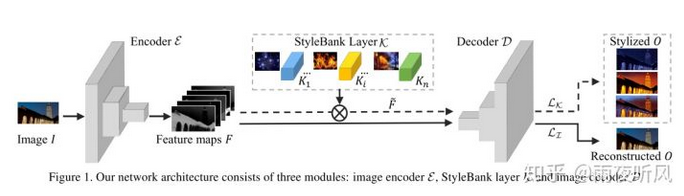
微软亚研这篇的模型由三部分组成,Encoder E, StyleBank Layer K, Decoder D. 作者希望将content和style的生成分离,即 E+D负责重建Content,不同的K则控制不同style的风格,每个模型可以有多达50个不同的K。
(个人觉得这种方法可能需要很大的网络结构才能实现,并且如果同时存储所有风格,模型切换实现起来可能有问题),这种方法已经做到了做到Multi-style single model。
4、接着,设计一种丢进去什么新的style都可以实时进行transfer,而无需重新训练
论文:Exploring the Structure of a Real-time, Arbitrary Neural Artistic Stylization Network

Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization
一文中利用Normalization component来实现不同的style transfer,这篇文章提出了Adaptive Instance Normalization,也就是适应性的IN。
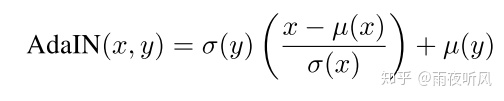
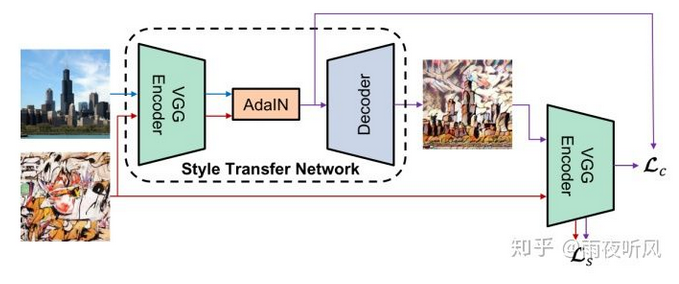
上图两个Encoder均为pre-trained VGG19,训练过程中参数不再更新。
Training和Inference过程中,Content和Style image同时传入Encoder,得到两组feature map, 然后通过AdaIN,对content image进行变换,转换所用的参数由计算得到,然后再传给decoder生成最终图片。需要注意的是 Content loss和之前paper定义的有所不同,如图所示,用的是经过AdaIN变换过的feature map计算L2 loss,而非encoder的输出。
自己的想法:
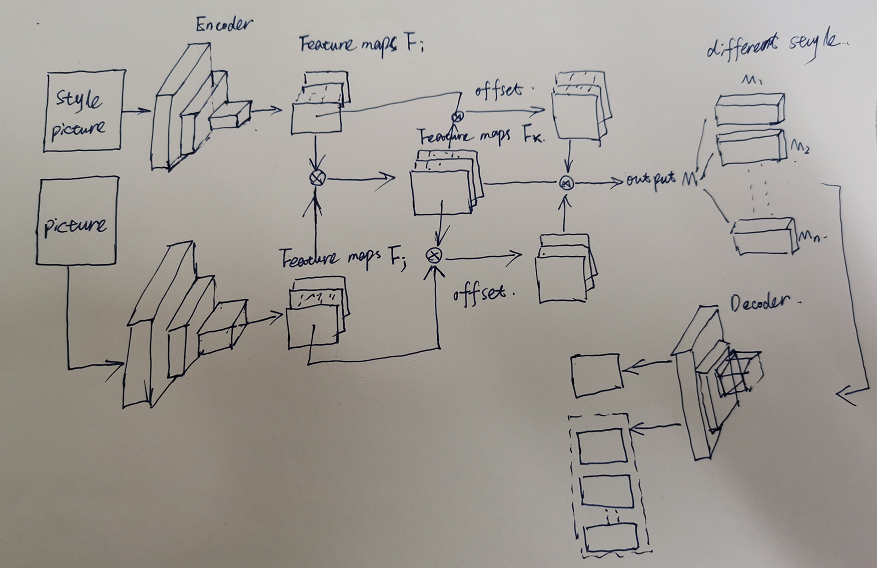
目标还是对之前的Content Loss+Style loss进行优化,但是增加一个offset来对Fx进行二次优化,并且将output styleM输出单独存储在一个张量M中,每次需要什么风格就单独选取Mi,实现Multi-style single model而且参数也不会随着其他风格进行更新。具体实现代码正在进行编写,正在准备中期,找工作,可能比较慢,有效果再更新。
再次感谢:https://zhuanlan.zhihu.com/p/57564626,https://zhuanlan.zhihu.com/p/24383274