一、背景
好记性不如烂笔头。记录 一下项目上用到的算法与思路
二、问题描述
近期收到一个项目,为A公司做数据整合,并开发出一套人物画像系统与俩个算法模型,其中的一个模型就是做图纸的分类。甲方(A公司)在最终会议前,给了点样例数据,让我们先做出个demo,给甲方的大老板们看一下
三、数据样例
甲方给的数据,包括:项目数据,人员数据,图纸数据。以下的内容只用了图纸数据,毕竟只是做图纸的分类,用不到其他的样本数据
下面是图纸的名称示例:

四、思路
1.将图纸名称进行分词,去除停用词,添加自定义词典,作为分析的特征
2.计算每个特征的 Tf-Idf(词频-逆文档频率),作为特征的值
3.选择聚类算法,开始的时候我是首选Dbscan的,毕竟相比于Kmeans 来说,不需要事先知道要分几类,调整领域和最小点数就可以完成分类,但是理论败给现实,图纸的名称分词的效果实在太接近,而且
样例数据本来就少,不足以区分开来,导致最后领域和最小点数的值无论怎么调效果都不尽人意,毕竟要给人家做demo,最后只好选了Kmeans。
五、代码实现
1.模型代码
1 # -*- coding:UTF-8 -*- 2 import jieba 3 import matplotlib.pyplot as plt 4 import pandas as pd 5 from sklearn.cluster import KMeans 6 from sklearn.feature_extraction.text import TfidfVectorizer 7 from sklearn.manifold import TSNE 8 9 data = open(r'xxx[文件路径].csv', encoding="utf8") 10 data = pd.read_csv(data) 11 file_userdict = 'userdict.txt' 12 # 导入自定义词典(不让jieba把他们分开) 13 jieba.load_userdict(file_userdict) 14 # 停用词列表 15 stop_words = ["-", "(", ")", ".", "pdf", "-"] 16 # tf-idf 词频-逆文档频率 tokenizer 意为分词器 stop_words 停用词 17 tf = TfidfVectorizer(tokenizer=jieba.lcut, stop_words=stop_words) 18 # tf-idf 计算 19 X = tf.fit_transform(data["图纸名"]) 20 # 将结果转为numpy的数组 21 res_matrix = X.toarray() 22 # kmeans,目标定位2类 23 kmeans = KMeans(n_clusters=2) 24 kmeans.fit(X)
2.结果可视化代码
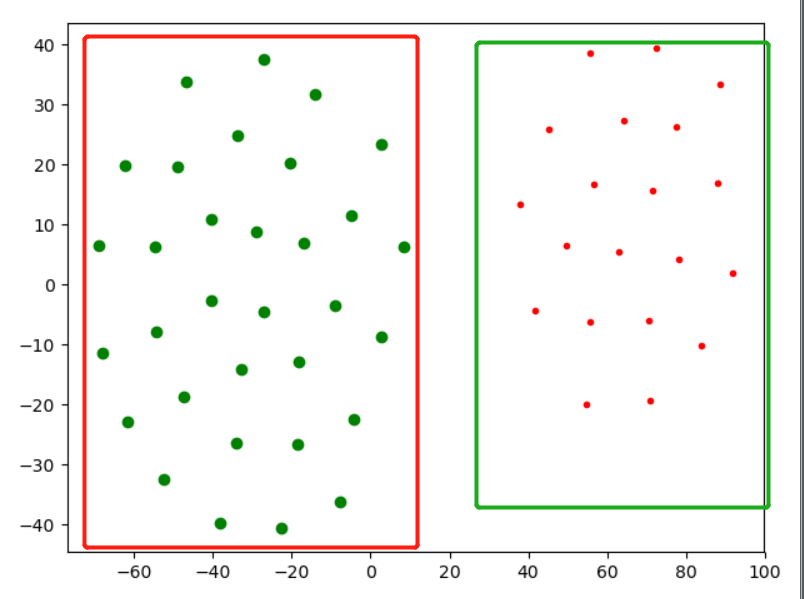
1 # 预测结果的标签列表 2 labels = kmeans.labels_ 3 labels = pd.DataFrame(labels, columns=['labels']) 4 res_matrix = pd.DataFrame(res_matrix) 5 res_matrix.insert(res_matrix.shape[1], 'labels', labels) 6 # tsne()将关系数据降为二维数据 7 tsne = TSNE() 8 a = tsne.fit_transform(res_matrix) 9 liris = pd.DataFrame(a, index=res_matrix.index) 10 d1 = liris[res_matrix['labels'] == 0] 11 d2 = liris[res_matrix['labels'] == 1] 12 print(d1) 13 print(d2) 14 plt.plot(d1[0], d1[1], 'r.', d2[0], d2[1], 'go') 15 plt.show()
3.分类效果展示