前言
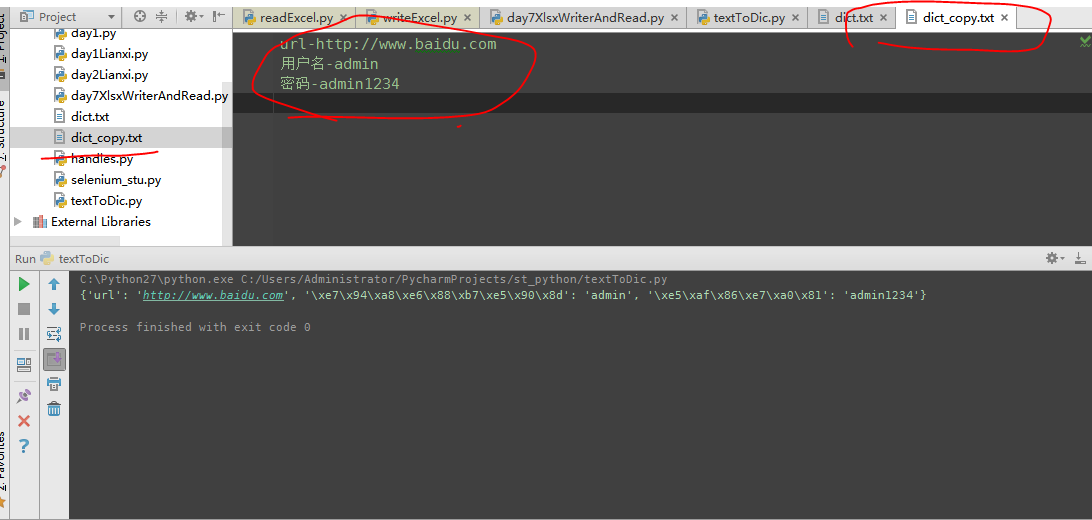
数据量偏小时,用txt文本保存数据比较合适,以-进行区分,为什么不用:呢?原因是,我们在使用数据时,会存在url地址的情况,里面宝行:所以用-进行替代
此处附上代码
1 #encoding=utf-8 2 3 def load_dict_from_file(filepath): 4 _dict = {} 5 try: 6 with open(filepath, 'r') as dict_file: 7 for line in dict_file: 8 (key, value) = line.strip().split('-') 9 _dict[key] = value 10 except IOError as ioerr: 11 print "文件 %s 不存在" % (filepath) 12 13 return _dict 14 15 16 def save_dict_to_file(_dict, filepath): 17 try: 18 with open(filepath, 'w') as dict_file: 19 for (key, value) in _dict.items(): 20 dict_file.write('%s-%s ' % (key, value)) 21 except IOError as ioerr: 22 print "文件 %s 无法创建" % (filepath) 23 24 25 if __name__ == '__main__': 26 _dict = load_dict_from_file('dict.txt') 27 print _dict 28 save_dict_to_file(_dict, 'dict_copy.txt')
文本的存储格式截图为:
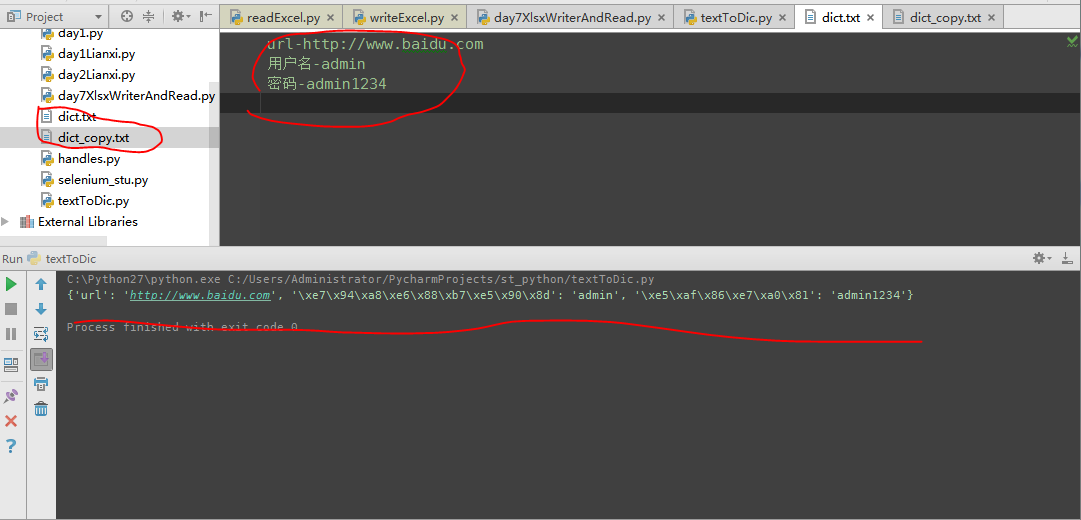
文件的写入后的截图为: