在某些情况下,从一个或多个关系数据库管理系统 (RDBMS) 迁移到 DynamoDB 可能无益。在这些情况下,创建混合系统可能更可取。
如果不想将所有内容迁移到 DynamoDB
例如,一些组织大笔投资于生成会计和运营所需众多报告的代码。生成报告所花时间对这些组织并不重要。关系系统的灵活性非常适合此类任务,在 NoSQL 上下文中重新创建这些报告可能过于困难。
某些组织将收购或继承的大量过时关系系统保留了几十年。为了证明此工作是合理的而迁移这些系统的数据,可能太过冒险和昂贵。
但是,相同的组织现在可能发现,其操作依赖面向客户的高流量网站 (其中毫秒响应必不可少)。关系系统无法不计 (通常无法接受) 巨大的支出进行扩展来满足此要求。
在这些情况下,答案可能是创建混合系统,DynamoDB 在混合系统中为存储在一个或多个关系系统中的数据创建具体化视图并针对此视图处理高流量请求。通过消除之前处理面向客户的流量所需的服务器硬件、维护和 RDBMS 许可证,此类系统具备降低成本的潜力。
如何实现混合系统
DynamoDB 可利用 DynamoDB 流和 AWS Lambda 与一个或多个现有关系数据库系统无缝集成:
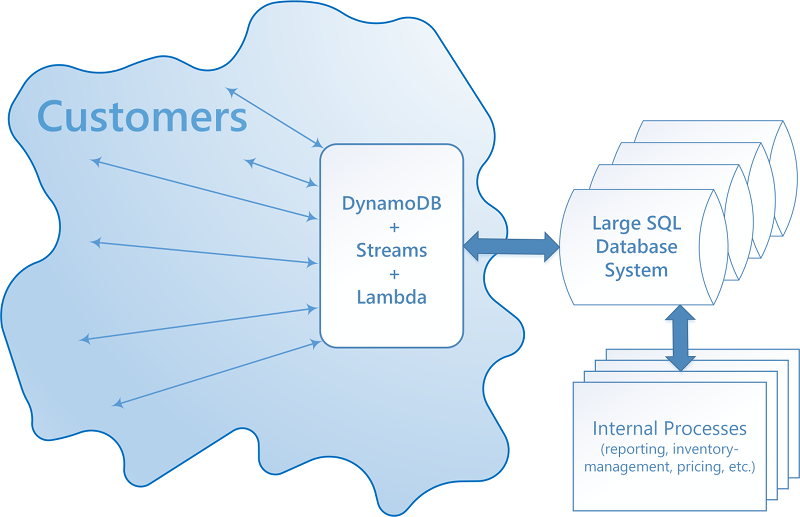
集成 DynamoDB 流和 AWS Lambda 的系统可提供若干好处:
-
它可作为具体化视图的持久化缓存运行。
-
它可设置为在查询数据时以及在 SQL 系统中修改数据时逐渐填充所查询和所修改数据。这意味着整个视图无需预先填充,这反过来意味着高效利用预置的吞吐容量的可能性更高。
-
它的管理成本低并且高度可用和可靠。
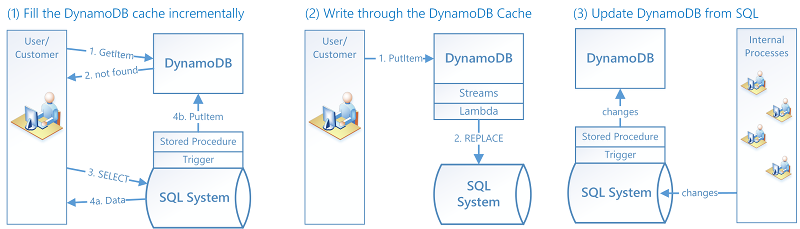
要实现此类集成,必须提供三种互操作性:
-
增量填充 DynamoDB 缓存。 需要某个项目时,首先在 DynamoDB 中查找它。如果它不在此处,则在 SQL 系统中查找它,然后将它加载到 DynamoDB 中。
-
通过 DynamoDB 缓存写入。 当客户更改 DynamoDB 中的值时,将触发 Lambda 函数以将新数据写回 SQL 系统。
-
通过 SQL 系统更新 DynamoDB。 当内部流程(如库存管理或定价)更改 SQL 系统中的值时,将触发存储过程以将更改传播至 DynamoDB 具体化视图。
这些操作很简单,但并不是每种方案都需要它们。
当希望主要依赖 DynamoDB,而且还希望保留一个小关系系统以执行一次性查询,或执行需要特殊安全性的操作或非时间关键型操作时,混合解决方案也很有用。