今天在开发小程序时,后台传过来一串字符串,当时看我一脸懵逼,后来才知道是富文本编辑器的内容当时也是很头疼,后台问了度娘,
知道怎么办。就一篇随笔分享一下;
首先我们得去gitHub下载一个文件夹(wxParse文件)
路径:https://github.com/icindy/wxParse
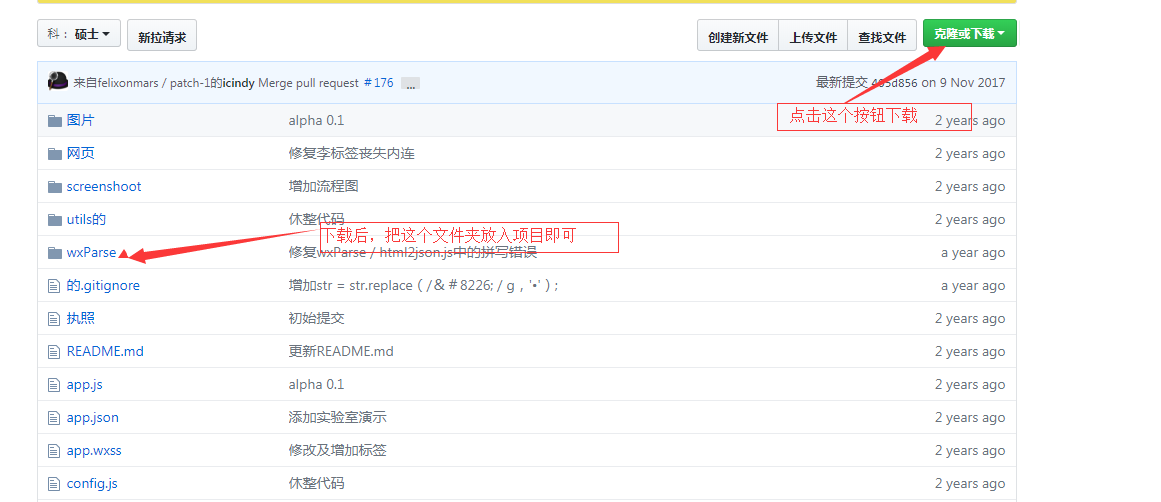
放入项目里面即可:
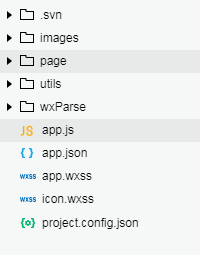
然后在需要使用的wxml文件引入wxParse.wxml模板
<import src='../../../../wxParse/wxParse.wxml' />
<!--展示富文本内容地方--->
<view class='main-introduce' wx:if="{{toggles=='true'}}">
<template is='wxParse' data='{{wxParseData:article.nodes}}' />
</view>

然后在需要使用的js文件引入wxParse.js模板
const WxParse = require('../../../../wxParse/wxParse.js')
//把后台给的富文本字符串给进模板
.then((res) => {
var ceshi = res.data.works[0].introduce;
// 转换富文本编辑器
WxParse.wxParse('article', 'html', ceshi, that, 5);
/*
*article:模板名称(不用改照写)
*html:转换的格式一般为html
*ceshi;要转换的富文本的数据(字符串)
*that:当前对象(一般为this)
*5:设置的padding值默认为0
*/

注意有些富文本的图文混排的图片是没有前缀的
这个时候就需要自己在wxParse.js去配置一下
在这个文件夹

里面的
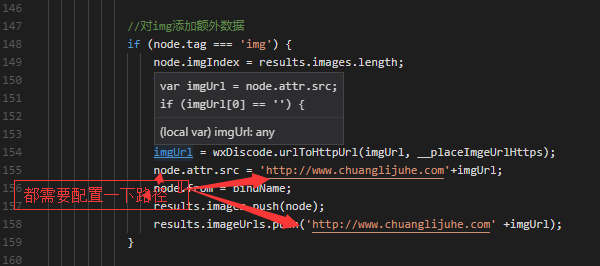
这样就可以解析富文本编辑器的内容了