神经网络的学习的目的是找到使损失函数的值尽可能小的参数。这是寻找最优参数的问题, 解决这个问题的过程称为最优化 (optimization)而由于参数空间复杂,无法轻易找到最优解
1随机梯度下降法 (stochastic gradient descent),简称SGD :
分步走, 朝着当前所在位置的坡度(梯度)最大的方向前进,就是SGD的策略
缺点是 有些情况SGD低效,原因是梯度的方向并没有指向最小值的方向,按照局部的梯度走,会出现来回往返的多余路线

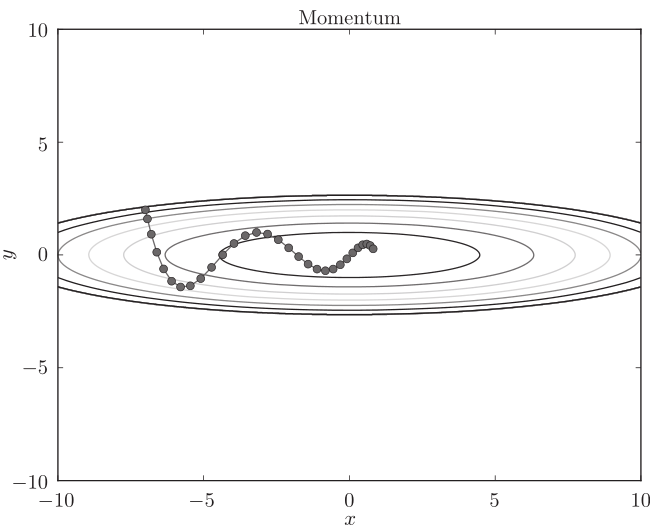
2 Momentum法
Momentum方法给人的感觉就像是小球在地面上滚动, 物体在梯度方向上受力,在这个力的作用下,物体的速度增加这一物理法则, 减弱了SGD的“之” 字形的路线变动程度
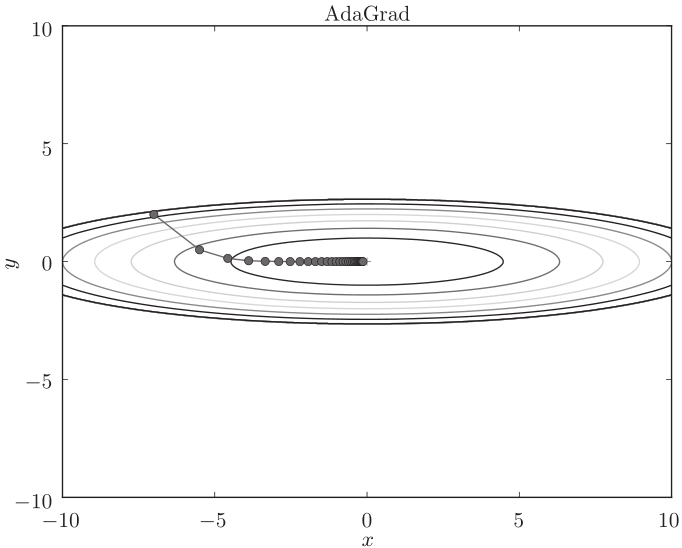
3 AdaGrad法
在关于学习率的有效技巧中,有一种被称为学习率衰减 (learning rate decay) 的方法, 即随着学习的进行, 使学习率逐渐减小。
AdaGrad会为参数的每个元素适当地调整学习率,与此同时进行学习 (AdaGrad的Ada来自英文单词Adaptive,即 “适当的” 的意思)
AdaGrad会记录过去所有梯度的平方和。因此,学习越深入,更新的幅度就越小。实际上,如果无止境地学习,更新量就会变为0,完全不再更新。
4 Adam法 (结合Momentum与AdaGrad法)
Momentum参照小球在碗中滚动的物理规则进行移动,AdaGrad为参数的每个元素适当地调整更新步伐。这就是Adam法的基本思路
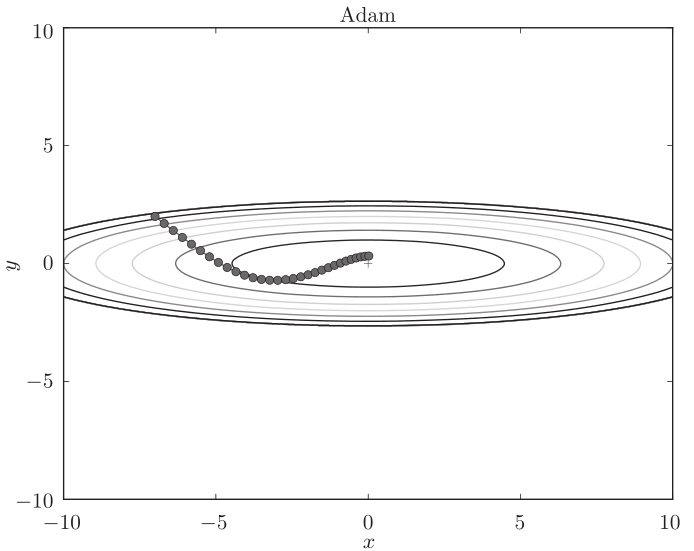
上面我们介绍了SGD、Momentum、AdaGrad、Adam这4种方法,那 么用哪种方法好呢?一般而言,与SGD相比,其他3种方法可以学习得更快,有时最终的识别精度也更高。
超参数 :学习率(数学式中记为η) 的值很重要。学习率过小, 会导致学习花费过多时间;反过来,学习率过大,则会导致学习发散而不能 正确进行
隐藏层的激活值的分布
观察隐藏层的激活值A(激活函数的输出数据) 的分布,可以获得很多启发
用直方图绘制各层激活值的数据分布
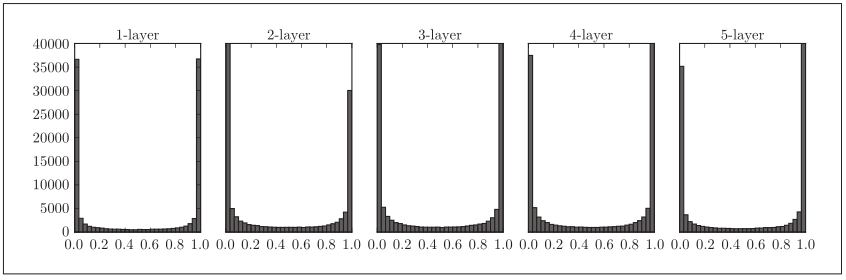
使用标准差为1的高斯分布作为权重初始值时的各层激活值的分布
从图可知,各层的激活值呈偏向0和1的分布,随着输出不断地靠近0 (或者靠近1),它的导数的值逐渐接近0。因此,偏向0和1的数据分布会造成反向传播中梯度的值不断变小,最 后消失。这个问题称为梯度消失 (gradient vanishing) 。层次加深的深度学习 中,梯度消失的问题可能会更加严重。
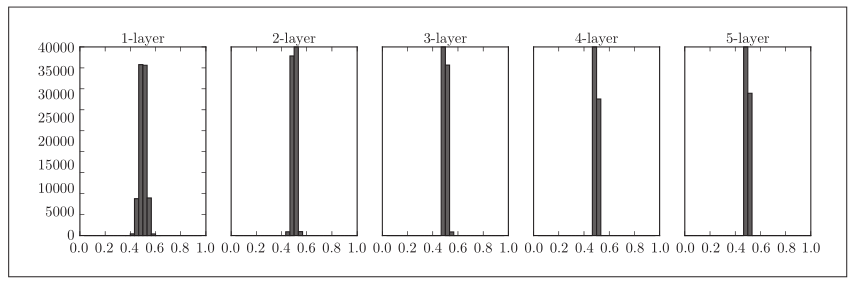
使用标准差为0.01的高斯分布时,各层的激活值的分布
这次呈集中在0.5附近的分布, 因为如果有多个神经元都输出几乎相同 的值,那它们就没有存在的意义了。比如,如果100个神经元都输出几乎相 同的值,那么也可以由1个神经元来表达基本相同的事情。因此,激活值在 分布上有所偏向会出现 “表现力受限” 的问题
需求 : 各层的激活值的分布都要求有适当的广度
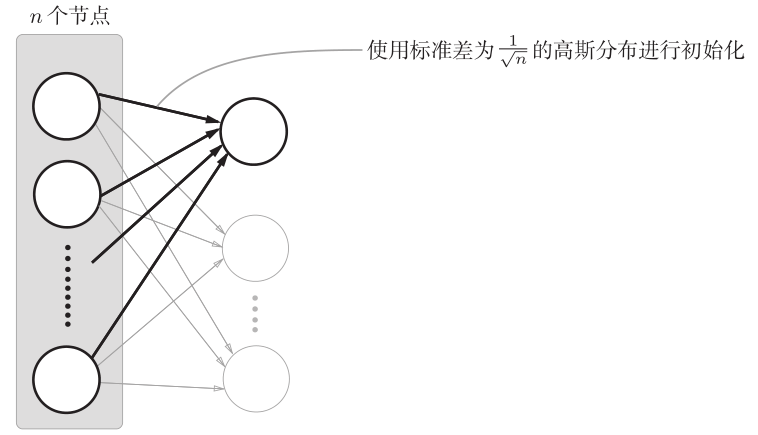
推荐办法: 如果前一层的节点数为n,则权重初始值使用标准差为 1/根号n 的分布 (参考Xavier初始值)

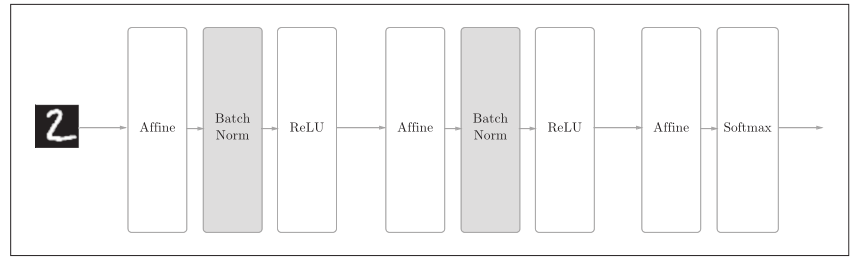
设定了合适的权重初始值,则各层的激活值分布会有适当的广度,从而可以顺利地进行学习。那么,为了使各层拥有适当的广度, “强制性” 地调整激活值的分布会怎样呢?实际上,Batch Normalization方法就是基于这个想法产生的:
Batch Normalization 虽然是一个问世不久的新方法,但已经被很多研究人员和技术人员广泛使用, 优点如下:
1 可以使学习快速进行 (可以增大学习率)
2 不那么依赖初始值 (对于初始值不用那么神经质)
3 抑制过拟合 (降低Dropout等的必要性)
Batch Norm的思路是调整各层的激活值分布使其拥有适当的广度。为此,要向神经网络中插入对数据分布进行正规化的层
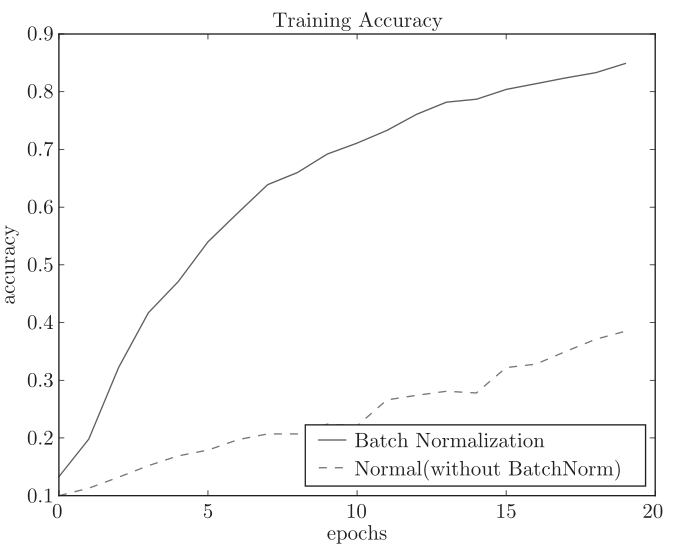
基于Batch Norm的效果:使用Batch Norm后,学习进行得更快了, 通过使用Batch Norm,可以推动学习的进行。并且,对权重初 始值变得健壮 ( “对初始值健壮” 表示不那么依赖初始值) 。Batch Norm具备 了如此优良的性质,一定能应用在更多场合中
解决过拟合:
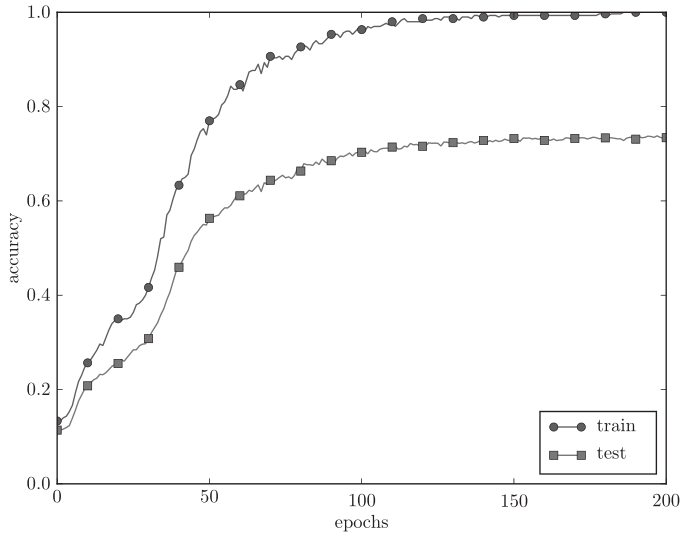
1 权值衰减是一直以来经常被使用的一种抑制过拟合的方法。该方法通过在学习的过程中对大的权重进行惩罚,来抑制过拟合。(很多过拟合原本就是因为权重参数取值过大才发生的)
方法是: 损失函数加上权重的平方范数 (L2范数) 。这样一来,就可以抑制权重变大。
数据集分成了训练数据, 测试数据和 验证数据
训练数据用于学习
测试数据用于评估泛化能力
验证数据用于调整超参数的数据
为什么不能用测试数据评估超参数的性能呢?这是因为如果使用测试数 据调整超参数,超参数的值会对测试数据发生过拟合
池化层
在图像识别领域,主要使用Max池化
使用im2col展开输入数据
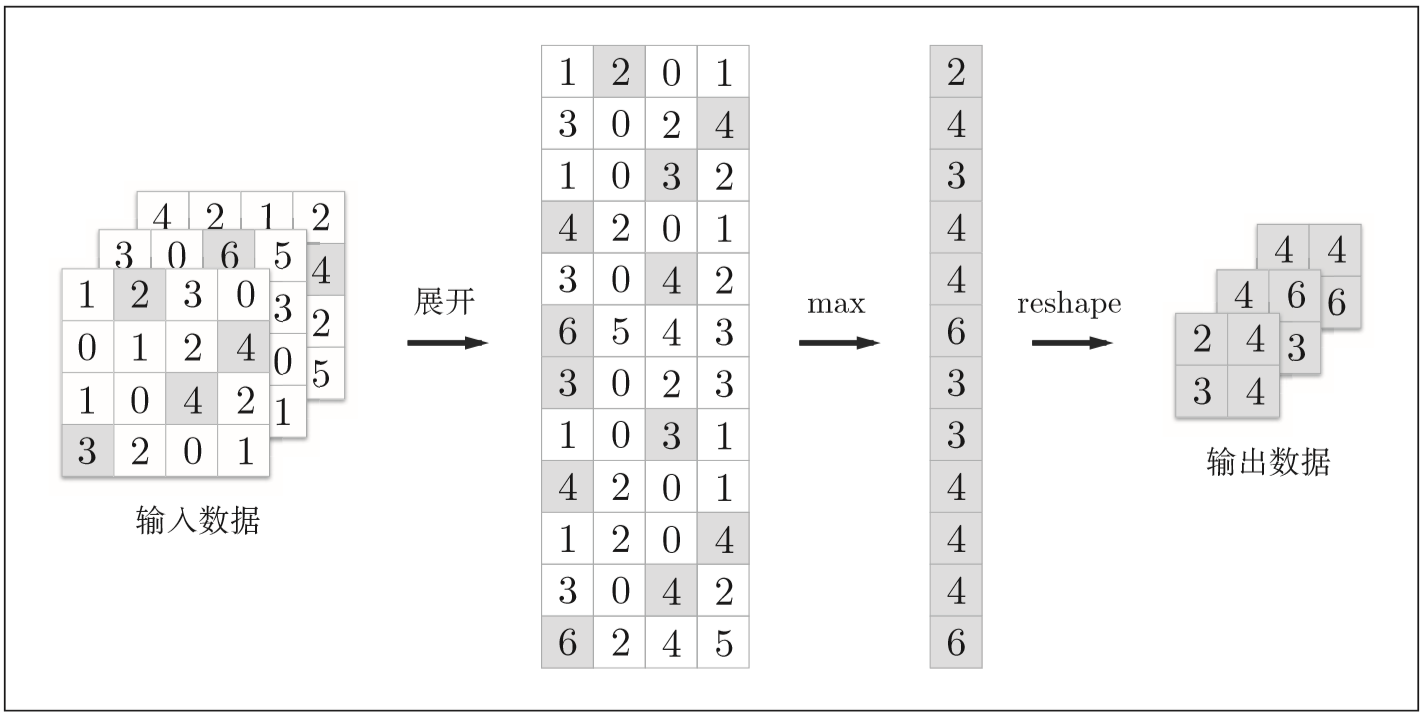
池化层的实现流程:池化的应用区域内的最大值元素用灰色表示
由此可以认为今后半精度浮点数将 被作为标准使用 (16位的半精度浮点 数(half float))