参考:https://www.cnblogs.com/rickiyang/p/11074194.html http://kafka.apache.org/quickstart http://kafka.apache.org/documentation
----------------------------------------------------------------------------------
一、基础知识
适用场景:来自官网
-
payment transactions // 金融交易
-
geolocation updates from mobile phones // 地址位置更新
-
shipping orders
-
sensor measurements from IoT devices // IOT传感器测量数据
-
medical equipment, and much more.
与其他消息队列比较
-
分布式系统,集群方式运行,可自由伸缩; // 采用zookeeper作为集群选举
-
可复制、持久化、保留多长时间都可以; // 有配置文件可配置消息持久化规则
-
提供流式处理能力,极少代码动态处理派生流和数据集。
Kafka消息特征
-
数据分布在整个系统中,具备数据故障保护和性能伸缩能力。
-
按照一定顺序持久化保存,可按需读取。
-
消息:键(一致性Hash值),对主题分区数取模选择分区,保证相同键的消息总写到相同批次上。
-
Kafa消息序列化
对kafka来说,消息是难懂的字节数组,建议使用额外结构定义消息内容。
消息模式:JSON和XML虽然易用,但缺乏强类型处理能力。
推荐使用
-
- 模式和消息体分开,模式变化时不需要重新生成代码。
- 支持强类型和模式进化,支持前后向兼容。
数据格式一致性:消除消息读写操作之间耦合性。如果读写操作耦合,消费者必须升级应用程序才能同时处理新旧数据格式。
kafka.consumer.key.deserializer=io.confluent.kafka.serializers.KafkaAvroDeserializer
kafka.consumer.value.deserializer=io.confluent.kafka.serializers.KafkaAvroDeserializer
消息以追加方式写入分区,先入先出方式顺序读取。
由于一个主题包含几个分区,无法保证整个主题范围内消息顺序,仅保证消息在单个分区内内顺序。
Kafka通过分区实现数据冗余和伸缩性。

broker:
-
- 为消息者提供服务,对读取分区请求作出响应,返回已提交磁盘的消息。
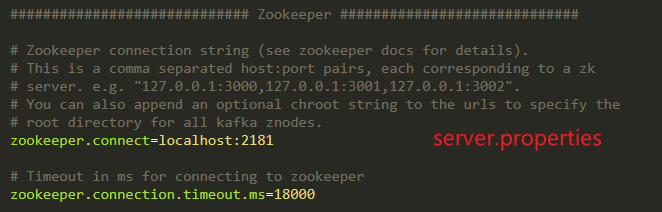
每个Kafka集群节点有一个全局唯一的broker-id(见server.properties中配置);

消费者和消费者组
消费者组: 保证每个分区只能被一个消费者使用,可以消费包含大量消息。
见下图:上述所有数字只代表offset,不是实际的内容。共计发送了15条消息。
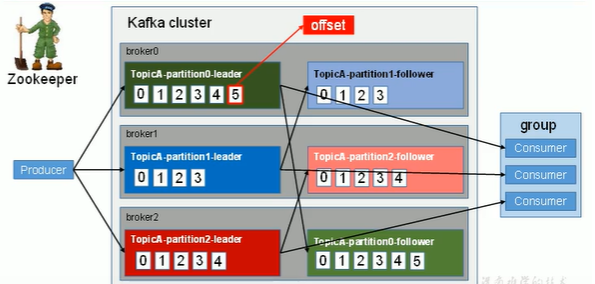
offset:
每个用户组通过自动提交或主动提交偏移量方式进行offset的提交
-
创建消息时,Kakfa添加到消息中。在给定分区中,每个消息偏移量是唯一的。
-
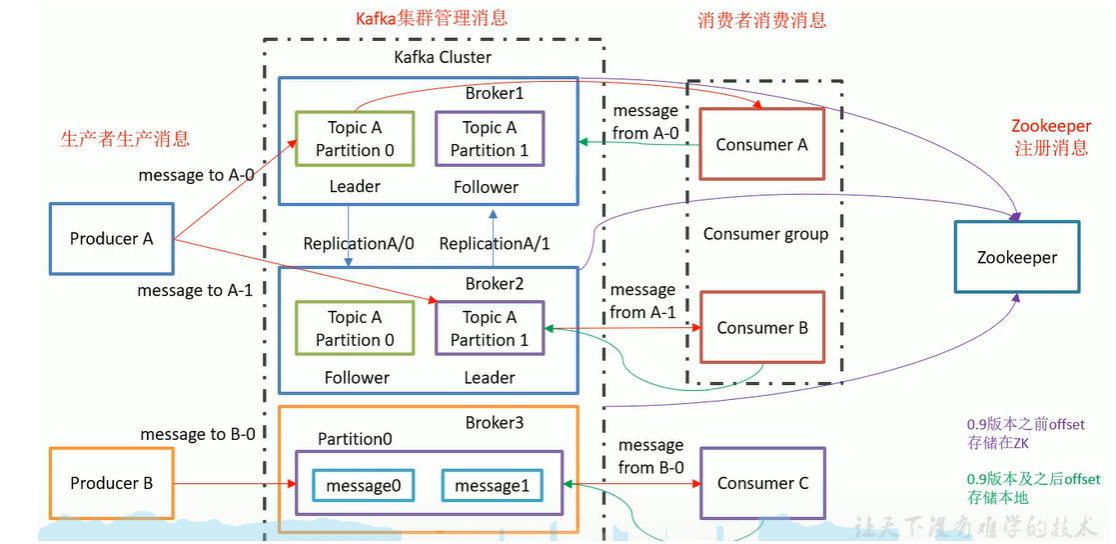
zk作用:1)Kafka集群工作,支撑Leader选举;2)0.9版本前消费者的offset(0.9后存储在Kafka磁盘中),降低对ZK的频繁交互;
Leader和Follower:面向具体Topic,而不是整体面向Broker。
broker:一个服务器是一个broker;一个集群由多个broker组成;一个broker可容纳多个topic。
Consumer Group:消费者组内每个消费者负责消费不同分区的数据。一个分区只能一个组内消费者消费。消费者组间互不影响。
Partition: 为实现扩展性,一个topic可分为多个Partition。每个partition是一个有序的队列。
Replication
Partition->Segment:
由于生产者消息不断追加到log末尾,为防止log过大而导致数据定位效率问题。所以采用分片+索引机制:
-
将每个partition分为多个segment。
-
每个segment对应文件:index+log,位于同一目录(topic名称+分区号)
-

1、
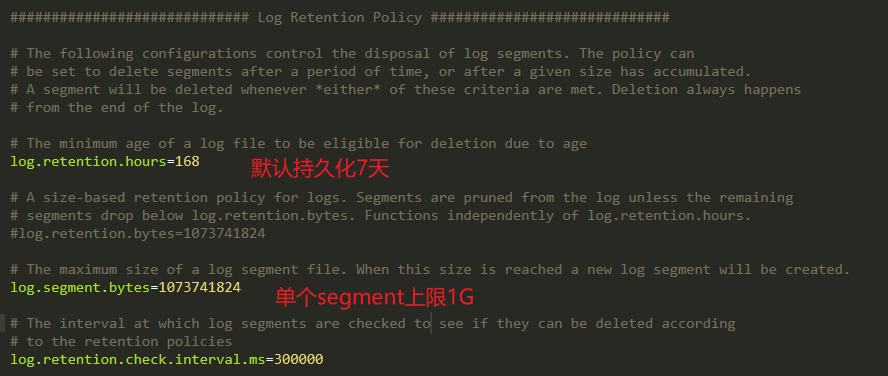

3、index和log以当前segment第1条消息offset命名。

查找过程示意:1)定位segment;2)根据offset查找消息
