一、CAS是什么
Compare and Swap,
1)先读取当前值;
2)对数据操作;
3)写入前比较数据库取值是否是步骤1获取的值,如果是直接写入;如果不是继续回到步骤1的操作
适用场景:
- CAS 适合简单对象的操作,比如布尔值、整型值等;
- CAS 适合冲突较少的情况,如果太多线程在同时自旋,那么长时间循环会导致 CPU 开销很大
二、CAS的实际JDK应用AutomicXXX(无锁化的CAS)
javautilconcurrentatomic
以AtomicInteger为例进行说明:
public static AtomicInteger atomicInteger = new AtomicInteger(0);atomicInteger.incrementAndGet(); // JDK源码实现基于CAS实现三、CAS存在的问题 :自旋锁,ABA
1,线程自旋问题:
如果线程1在写入过程时发现数据库最新取值与最初的取值不一致,则会启动等待,重新执行一次CAS操作,直到操作成功。
2,ABA问题:
CAS 存在一个问题,就是一个值从 A 变为 B ,又从 B 变回了 A,这种情况下,CAS 会认为值没有发生过变化,但实际上是有变化的。
解决方案:数值增加版本号
并发包下倒是有 AtomicStampedReference 提供了根据版本号判断的实现,可以解决一部分问题。
AtomicStampedReference主要维护包含一个对象引用以及一个可以自动更新的整数"stamp"的pair对象来解决ABA问题。
//关键代码 public class AtomicStampedReference<V> { private static class Pair<T> { final T reference; //维护对象引用 final int stamp; //用于标志版本 private Pair(T reference, int stamp) { this.reference = reference; this.stamp = stamp; } static <T> Pair<T> of(T reference, int stamp) { return new Pair<T>(reference, stamp); } } private volatile Pair<V> pair; .... /** * expectedReference :更新之前的原始值 * newReference : 将要更新的新值 * expectedStamp : 期待更新的标志版本 * newStamp : 将要更新的标志版本 */ public boolean compareAndSet(V expectedReference, V newReference, int expectedStamp, int newStamp) { Pair<V> current = pair; //获取当前pair return expectedReference == current.reference && //原始值等于当前pair的值引用,说明值未变化 expectedStamp == current.stamp && // 原始标记版本等于当前pair的标记版本,说明标记未变化 ((newReference == current.reference && newStamp == current.stamp) || // 将要更新的值和标记都没有变化 casPair(current, Pair.of(newReference, newStamp))); // cas 更新pair } }
四、JDK8的优化LongAdder等
Java 8有一个新的类,java.util.concurrent.atomic.LongAdder。
他就是尝试使用分段CAS以及自动分段迁移的方式来大幅度提升多线程高并发执行CAS操作的性能,这个类具体是如何优化性能的呢?
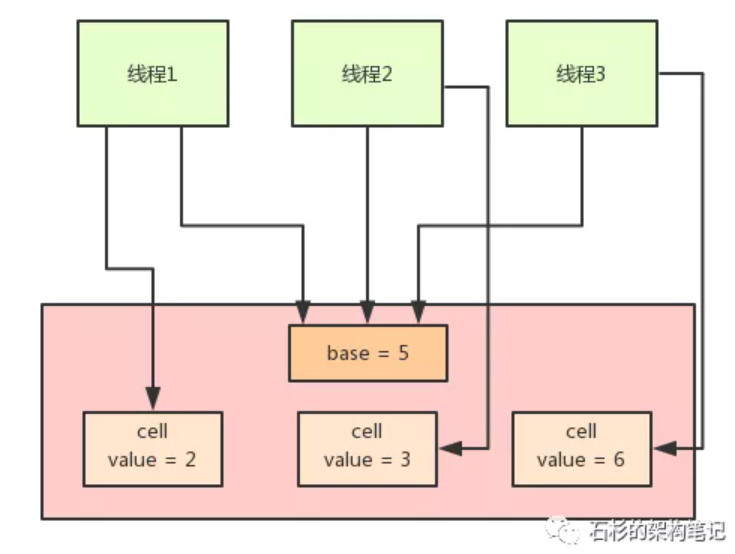
在LongAdder的底层实现中,首先有一个base值,刚开始多线程来不停的累加数值,都是对base进行累加的,比如刚开始累加成了base = 5。
接着如果发现并发更新的线程数量过多,就会开始施行分段CAS的机制,也就是内部会搞一个Cell数组,每个数组是一个数值分段。
这时,让大量的线程分别去对不同Cell内部的value值进行CAS累加操作,这样就把CAS计算压力分散到了不同的Cell分段数值中了!
这样就可以大幅度的降低多线程并发更新同一个数值时出现的无限循环的问题,大幅度提升了多线程并发更新数值的性能和效率!
而且他内部实现了自动分段迁移的机制,也就是如果某个Cell的value执行CAS失败了,那么就会自动去找另外一个Cell分段内的value值进行CAS操作。
这样也解决了线程空旋转、自旋不停等待执行CAS操作的问题,让一个线程过来执行CAS时可以尽快的完成这个操作。
最后,如果你要从LongAdder中获取当前累加的总值,就会把base值和所有Cell分段数值加起来返回给你。