一:使用配置元件csv data set config参数化
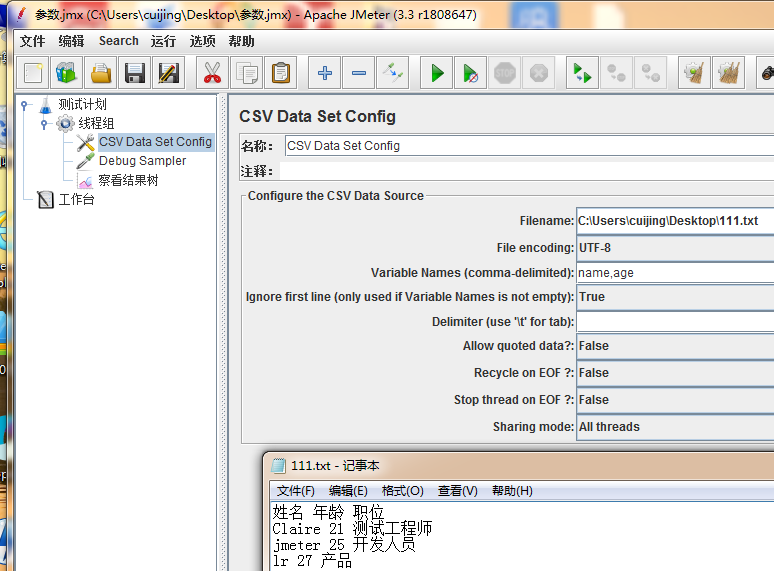
1.filename :文件名,点击浏览按钮,打开要从中取值的文件
2.file encoding:文件编码方式
3.variable names:参数名称,以上图中文件举例,假设需要取出文件中的姓名和年龄,这里就要填写 name,age(名称随便取,但是要用逗号隔开)
4.ignore first line:是否忽略第一行,以上图文件举例,第一行不是我要取的参数值,因此该项选为true
5.delimiter:上图文件中,各参数是以空格分开的,这里就填写空格就好了
6.allow quoted data:取到的参数里面是否允许有分隔符。以上图文件为例,如果选择true,则第一次迭代取到的参数为 (Claire)和(21 测试工程师)
7.recycle on eof:是否循环取值。假设设置迭代次数为4次并且不循环取值,此时第四次迭代是取不到参数值的。我们可以通过debug sample来观察一下
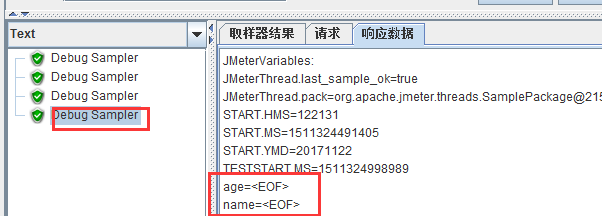
8.stop thread on eof:是配合recycle on eof=false使用的,当设置循环取值,迭代次数又大于参数个数时,此项为true,则停止测试;此项为false,则 不停止测试,但是参数是取不到的(如上面图中所示,参数为<EOF>
9.sharing mode:是指参数文件共享模式。
all thread:参数文件对所有线程共享,该测试计划下的所有线程组之间都可共享
current thread group:只对当前线程组的线程共享
current thread:仅当前线程可用
如果在其他sample中要用到上面所取到的参数,使用方法为${name},${age}----与设置的variable names一致
二、使用函数参数化

random string length:产生的字符串长度,比如我要生成一个长度为100的产品描述,这里 填写00就可以了
chars to use for random string generation:相当于种子。生成的字符串中,每个字符都从这个种子里面取得
name of variable in which to store the result:给生成的字符串取个名字,作者是为了产生产品说明,因此取名为proDes,如果填写了该项,则参数可以在debug sample中看到(如下图)
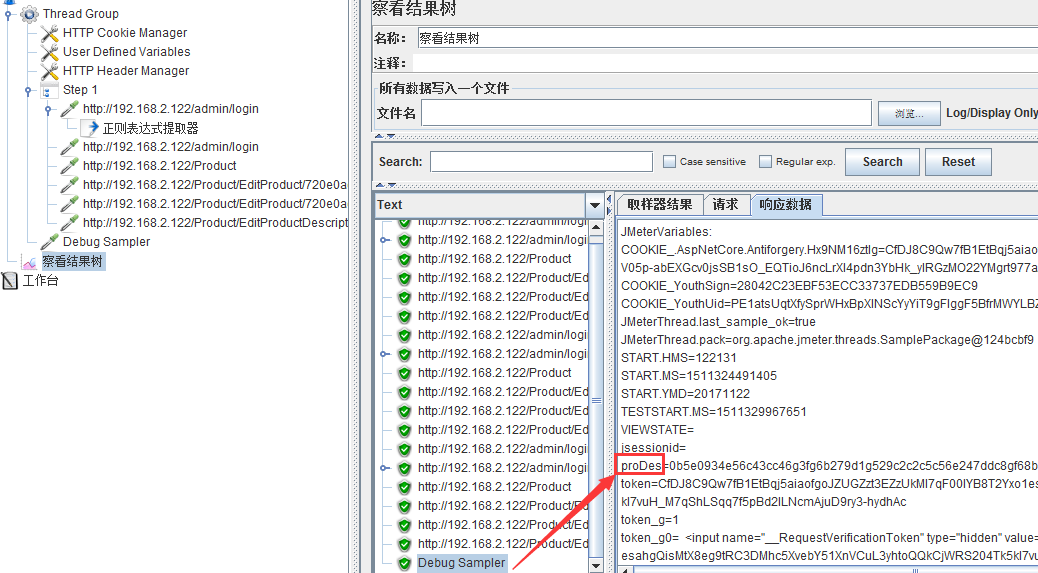
注意:上面实例中用到的正则表达式提取器也是参数化的一种方式。比如,为了安全,每次请求/admin/login页面时,服务端代码都会新生成一个requesttoken返回,之后的请求都要带上该值。此时就可以用后置处理器中的正则表达式提取将该值提取出来,方便后面sample发送请求时带上该参数。
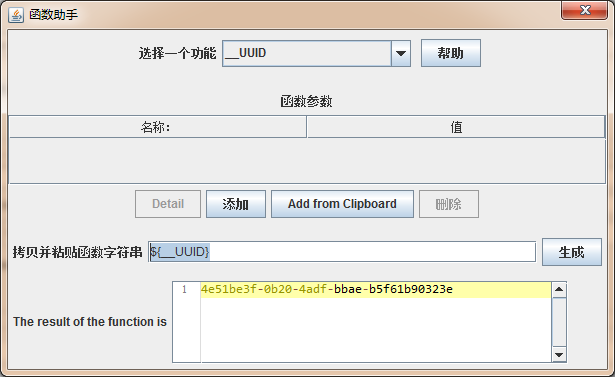
有些系统产生的ID是类似这样的: 【f525183a-ca6e-4267-b3de-700b141185d8】。这种情况下我们可以使用函数来生成该ID。
三:用户参数
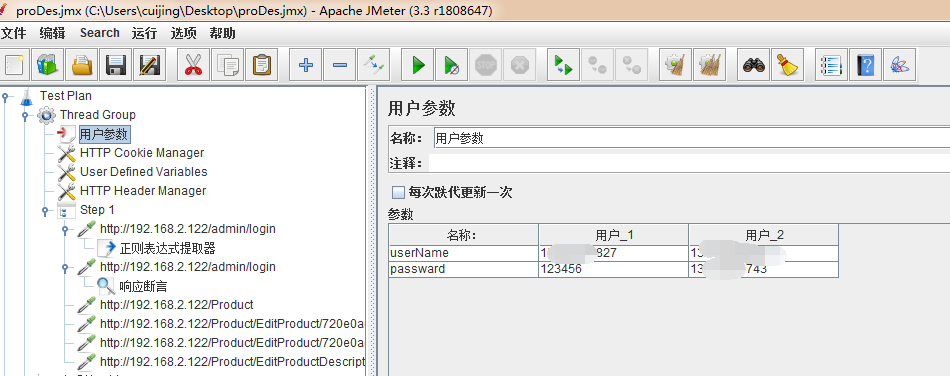
这里的用户代表的是线程。
上面实例中,添加了参数username。假设设置线程个数为2(暂且叫做thread1和thread2)。sample中使用该参数(${username},${password}),之后运行脚本,thread1取到的username就是用户_1里面设置的值;thread2取到的username就是用户_2里面设置的值。
感觉与csv data set config有些类似
四:Variables From CSV File
jmeter官网下载该组件,解压后放到jmeter的安装路径下即可(笔者是放在这里的-----E:apache-jmeter-3.3libext),之后重启jmeter即可使用该插件(如下图)
先设置该元件的参数
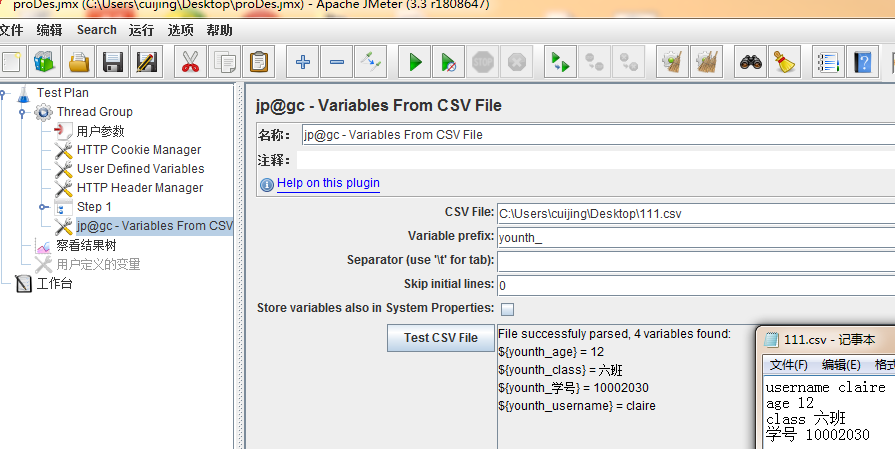
csv file:文件地址
variable prefix:参数前缀。通过上图示例:该前缀结合文件中的第一列产生了参数名
separator:分隔符
skip initial lines:跳过行数。假设输入1,则产生的参数中,就不会有younth_username了
store variable also insystem properties:是否将参数存储为系统属性(在变量很多时就不要勾选了)
之后点击test CSV file就可以看到结果了
该组件与之前的CSV data set config 的差别是可以一次性参数化多个数据
五:用户定义的变量(测试计划中添加或者添加一个用户定义变量的配置元件)
该方式比较简单,不做阐述。