需求:将爬取到的数据值分别存储到本地磁盘、redis数据库、mysql数据。
1.需要在管道文件中编写对应平台的管道类
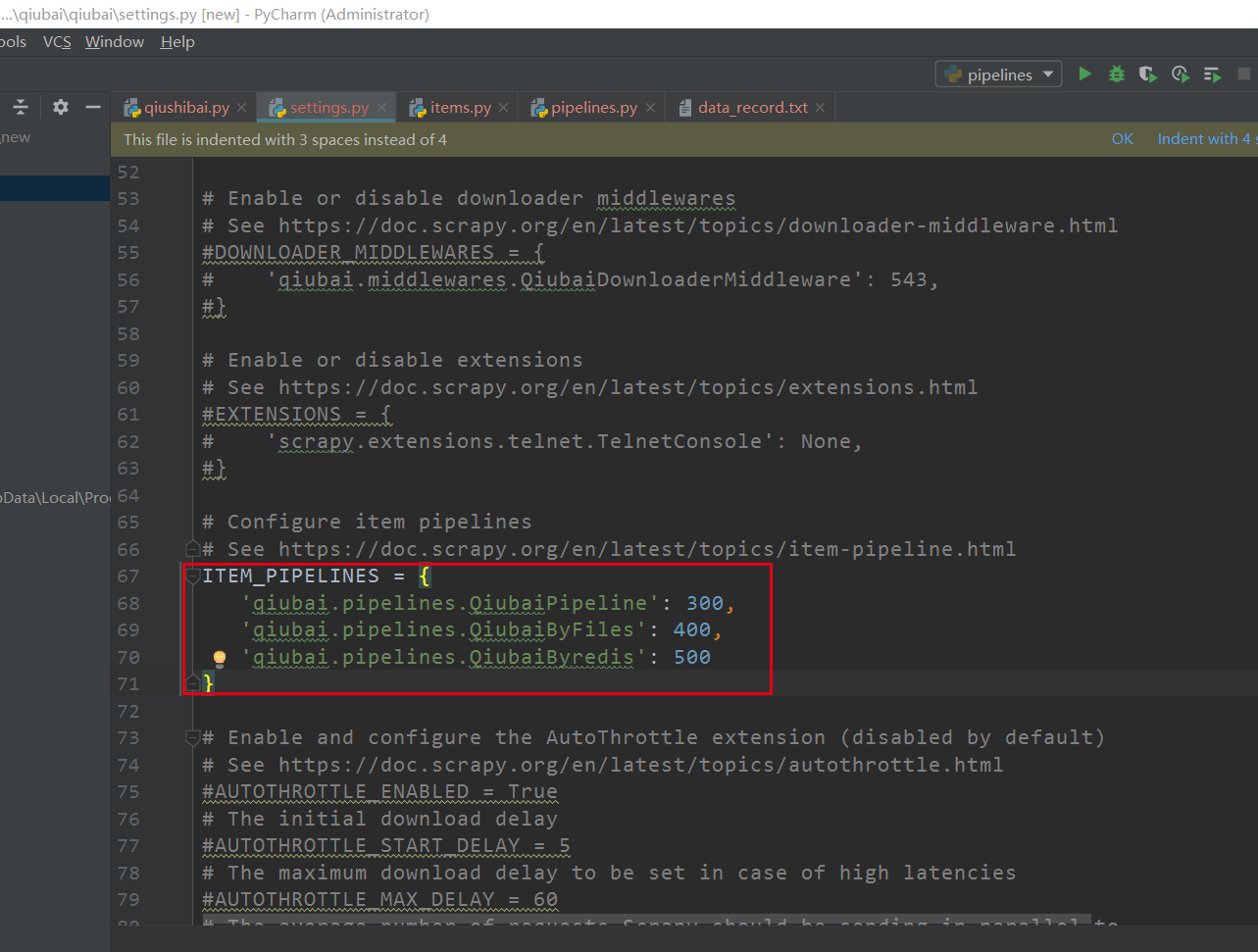
2.在配置文件中对自定义的管道类进行生效操作(在pipelines里面定义的类,加进settings.py里面 pipelines对应的里面,后面数字大小无所谓)
pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import pymysql class QiubaiPipeline(object): conn = None # 该方法只会在爬虫开始运行的时候调用一次 cursor = None def open_spider(self, spider): print("开始爬虫") # self.fp = open("./data_record.txt", "w", encoding="utf-8") self.conn = pymysql.Connect(host="127.0.0.1", port=3306, user="root", password="1228", db="qiubai") # 该方法就可以接受爬虫文件中提交过来的item对象,并且对item对象中存储的页面数据进行持久化存储 # 参数item就是接收到的item对象 # 每当爬虫文件向管道提交一次item,则该方法就会被执行一次 def process_item(self, item, spider): # 取出item中的对象存储数据 author = item["author"] content = item["content"] # 持久化mysql存储 sql = "insert into data values ('%s', '%s')" % (author, content) print(sql) # self.fp.write(author + ":" + content + " ") self.cursor = self.conn.cursor() try: self.cursor.execute(sql) self.conn.commit() except Exception as e: print(e) self.conn.rollback() return item # 该方法只会在爬虫结束时调用一次 def close_spider(self, spider): print("爬虫结束") # self.fp.close() self.conn.close() class QiubaiByFiles(object): def process_item(self, item, spider): print("数据已写入磁盘文件中") return item class QiubaiByredis(object): def process_item(self, item, spider): print("数据写入redis中") return item