1.string
1)setex +key+时间(单位s)+value:添加数据,设置超时时间,单位是s。
2)psetex +key+时间(单位ms)+value:添加数据,设置超时时间,单位是ms。
3)getrange+key+start(起始下标)+end(终止下标):获取key对应的value值的从start到end的数据。
4)getset +key+value:先get再set,也就是在set的同时,将set之前的数值返回。
5)mset +key+value+key+value...:批量添加多个数据。
6)mget +key+key...:批量获取多个数据。
7)setnx+key+value:当且之后当前key不存在时,才可以添加成功,否则不成功,也就是不能覆盖旧value值。
8)strlen +key:当前的key的value的长度。
9)msetnx +key+value+key+value...:利用事务的原子性,要么都成功,要么都失败。如果有一个key已经存在,则都不能正确添加。
10)incr+key:如果当前key对应的value是int类型,即数值,则可以执行incr命令,表示自增1。如果不是数值,这个命令不能正常执行。
11)incrby+key+步长:将key对应的value值+步长。
12)decr +key:自减1。
13)decrby+key+步长:将key对应的value值-步长。
14)append +key+数据:将当前key对应的value值append后面的数据,也就是字符串连接。
2.hash
1)hset+hash表名+key字段名+value值:添加一个hash类型的数据,key是这个hash表中的一条数据的key名,value值对应的是这条数据的value值。
2)hexists+hash表名+key字段名:查看当前hash表中的key字段是否存在。
3)hget+hash表名+key字段名:查看当前hash表中的key字段所对应的value值是否存在。
4)hgetall+hash表名:获取当前hash表的所有字段和对应的值。如下所示:
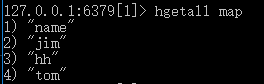
其中,name是字段名,jim是name对应的value值,hh是字段名,tom是hh对应的value值。
5)hkeys+hash表名:获取当前hash表的所有字段名。
6)hvals +hash表名:获取当前hash表的所有value。
7)hlen+hash表名:获取当前hash的长度,也就是hash表中的字段的个数。
8)hmget +hash表名+字段名+字段名...:批量获取hash表中各个字段所对应的value值。
9)hmset+hash表名+字段名+value值+字段名+value值:批量对hash表,添加多个数据。
10)hdel +hash表名+字段名+字段名...:批量删除hash表中字段名所对应的数据。
11)hsetnx+hash表名+字段名+value值...:如果字段名已经存在,则不会添加成功,返回0;如果不存在,则可以添加成功,返回1。
3.list(可有重复数据)
1)lpush+list名+value值+value值+value值...:新建一个list名的list,value是它里面的数据。(类似于java里面的list)。【倒入】
2)llen +list名:获取当前list的长度,即里面的数据个数。
3)lrange+list名+start(起始下标)+end(终止下标):获取list的从start到end的数据。如下所示:
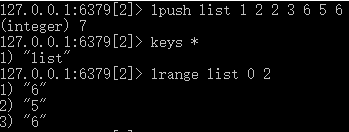
4)lset +list名+pos(下标)+value值:将list中,下标为pos的数值更新为value。
5)lindex+list名+pos(下标):根据下标获取list中对应的数据值。
6)lpop+list名:移除list中第一个元素,并将其返回。
7)rpop+list名:移除list中最后一个元素,并将其返回。
4.set(无序集合,没有重复数据,以hash来实现,删除,添加,查找的复杂度是o(1))
1)sadd +set名+value值+value值+value值...:新建一个set名的集合,各个value值是集合里面的数据。如果value值已经存在,则不能正确添加。此命令没有原子性,也就是如果有其中一个value是已经存在的,其他的value仍然能正常添加。
2)scard +set名:获取当前集合的数据个数。
3)rename+旧set名+新set名:更改当前集合的名字。
4)smembers+set名:查看当前set中的所有数据。
5)sdiff +set1名+set2名:求set1-set2差集,即在set1集合而不在set2集合中的数据。
6)sinter+set1名+set2名:求set1和set2交集,即同时在set1和set2集合中的数据。
7)sunion +set1名+set2名:求set1和set2并集。
8)srandmember+set名+个数:随机返回set集合中的数值,数量按个数而定。
9)sismember+set名+value值:查看当前value值是否存在于set集合中。
10)srem+set名+value值+value值...:从set集合中移除value数据(可以批量移除)。
11)spop+set名:随机移除并返回set集合中的某个数据。
5.sortedset(有序集合,集合元素唯一,分数(权重)不唯一,按分数进行排序)
1)zadd +set名+分数+value+分数+value...:添加一个新集合set,并对其添加元素。
2)rename+旧set名+新set名:更新set名。
3)zcard+set名:计数当前集合的元素个数。
4)zscore+set名+value:查看当前集合中当前元素的分数。
5)zcount+set名+start_score(起始分数)+end_score(结束分数):计数当前集合中分数在[起始分数,结束分数]之间的元素个数。
6)zrank+set名+value:返回当前集合中value值的下标。
7)zincrby+set名+步长+value:增加当前集合中的value元素所对应的分数,即当前分数+步长。
8)zrange+set名+start_pos(起始下标)+end_pos(结束下标):返回从起始下标到结束下标之间的元素。
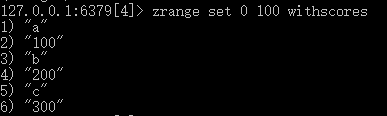
9)zrange+set名+start_pos(起始下标)+end_pos(结束下标)+withscores:返回期间元素并其相对应的分数。如下所示: