问题一:
在rancher的ui上,不能创建k8s的master节点的高可用集群。创建k8s集群,添加节点的时候,可以添加多个master,但是多个master又没有高可用,只要其中一个出问题了,那么整个集群就垮了。本想着自己来改配置,但是集群是使用docker启动组件,配置复杂繁琐,不太懂rancher组织集群的原理,个人能力有限等原因,只好找寻其他解决方案。
解决方法:在多个master情况下,其中一个master节点出毛病了,只需要在rancherUI上删掉这个节点就行了(以前不太了解,master出问题了,不敢删),rancher会自动update这个集群,使之master正常。目前只知道这个方法,由于这样业务中断耗时会比高可用多一点点,所以要做好主机监控。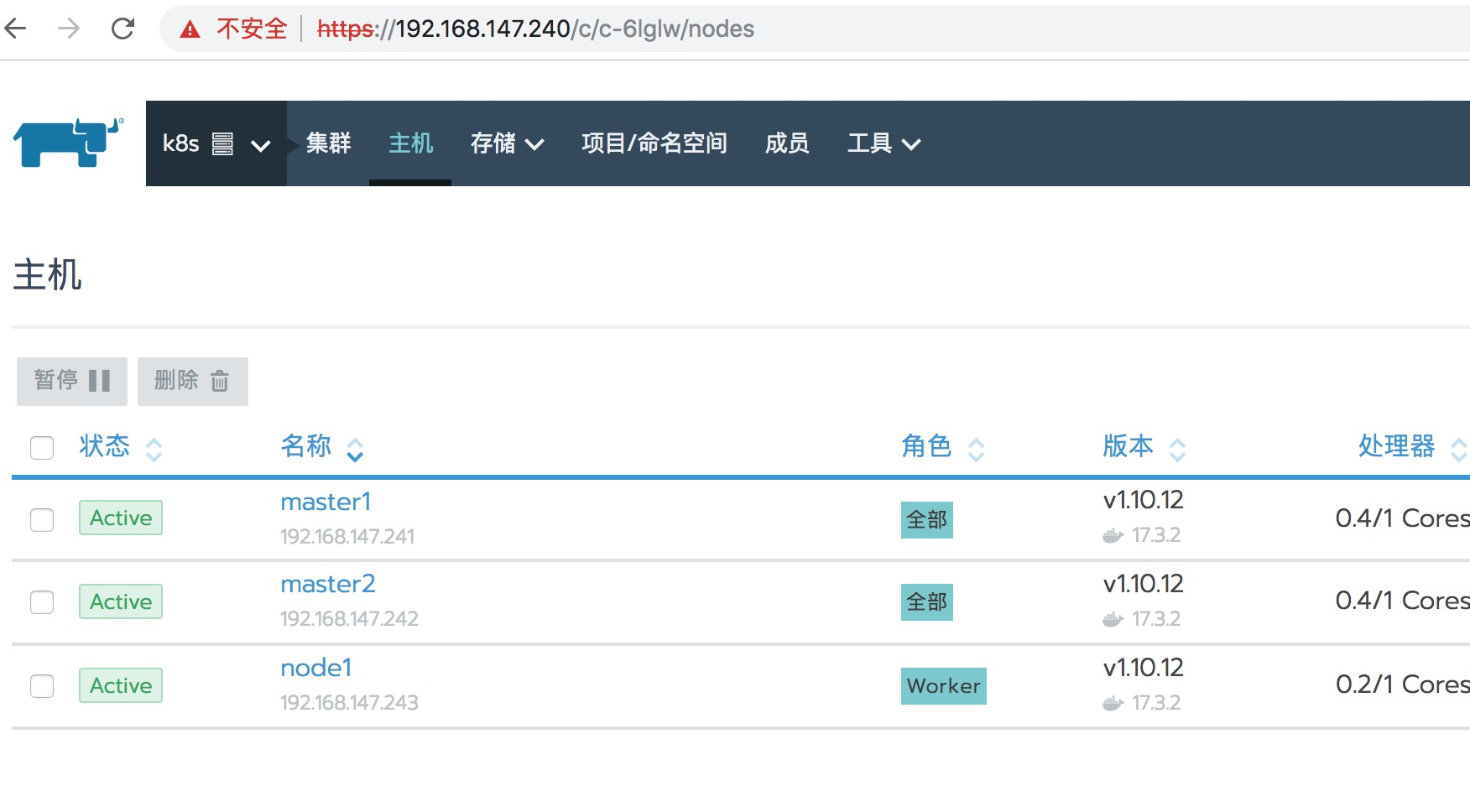


问题二:
使用rancher添加master节点时,选择了全部角色(不完美的操作,如果master节点资源丰富就可以完全忽略这个问题了)。master是集群里重要的一个角色,如果一个master既做管理节点,又做业务节点,会对节点主机资源占用过多,而容易导致master节点出问题的几率增大。让master节点只做管理任务,要么取消它的worker角色,要么就禁止pod等资源进入到这个节点。
rancher上可以编辑集群中的节点,然而,只能更新这个节点的标签,即使删掉worker这个标签,也无法去掉master节点的worker角色。
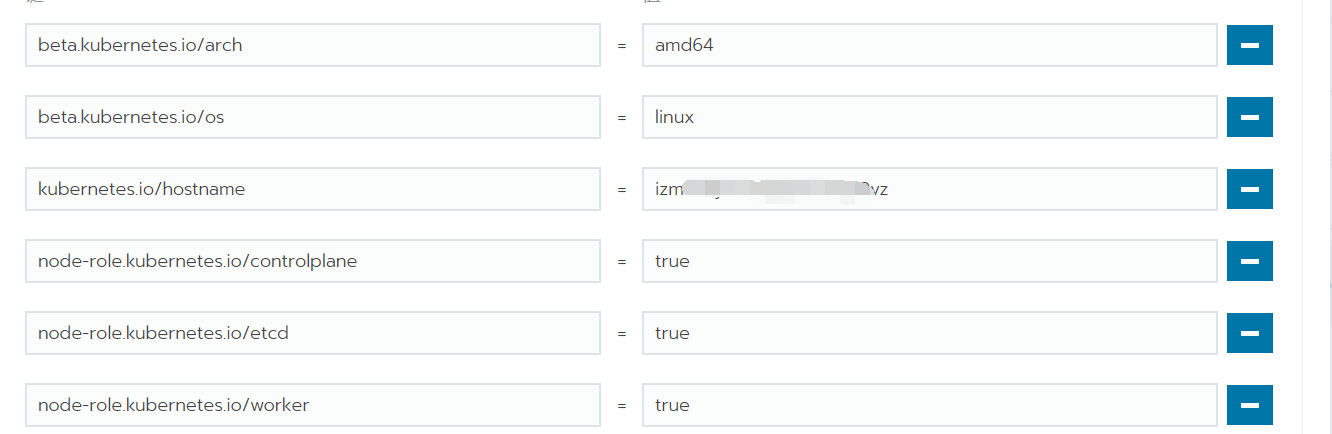
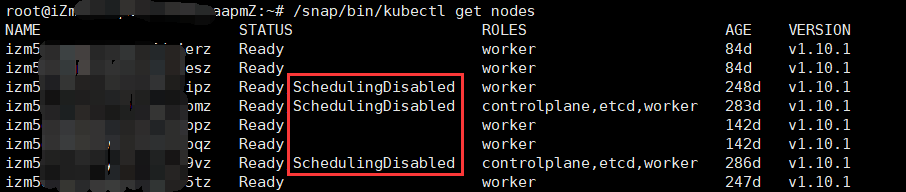
解决方法:这种情况就不在rancher操作了,在k8s上有两个维护命令cordon、uncordon,是设置节点不可调度和取消节点不可调度,一般是用于节点出现问题时维护使用的。
kubectl cordon master1
kubectl uncordon master1
设置不可调度后,k8s的pod都将不会再调度到此节点上。

问题三:
清除节点服务器:
df -h | grep kubelet | awk -F % '{print $2}' | xargs umount rm /var/lib/kubelet/* -rf rm /etc/kubernetes/* -rf rm /etc/cni/* -rf rm /var/lib/rancher/* -rf rm /var/lib/etcd/* -rf rm /var/lib/cni/* -rf rm /opt/cni/* -rf (ip link del flannel.1) (ip link del cni0) (iptables -F && iptables -t nat -F) docker ps -a|grep -v gitlab|awk '{print $1}'|xargs docker rm -f docker volume ls|awk '{print $2}'|xargs docker volume rm systemctl restart docker