总结的JAVA零碎知识点
学习和工作中总会有一些零碎的知识点,可能不经常用到或者以前不熟知,在此记录一下。
一、有关Lamda表达式
Lamda表达式是1.8新增特性,所以使用前请确定项目JDK版本是否支持。
Lamda主要解决匿名内部类和函数的啰嗦语句问题,比如曾经的Jframe的Jbutton监听事件addActionListener
JButton jb = new JButton("click");
jb.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
System.out.println("1");
}
});
可以简化为jb.addActionListener(a -> System.out.println("1"));
1.Lamda语法:
(参数) ->单行语句;
例子:jb.addActionListener((a)-> System.out.println("1"));
(参数) ->{多行语句};注意多个语句的分号。
jb.addActionListener((a) -> {
System.out.println("2");
System.out.println("1");
});
(参数) ->表达式;比如某接口返回int型
test((a)-> 5*9);
2.用法,当传入参数是接口,且需要自己实现时,可以用Lamda简化代码。
3.本人并不建议过多使用Lamda,因为会给阅读代码带来很大困扰。
二、volatile关键字
首先说一下volatile有什么功能:它保证的是有序性和可见性!!!注意没有原子性!!!!只修饰变量,是轻量级实现。这也是和synchronized主要区别。
也就是说,用volatile修饰的变量,每次读取时都会获取修改后(最新)的值进行操作(即可见性)。
比如我们用某个变量控制线程结束,如果不加volatile,在外部改变该变量时,run总是获取旧值。
public class VolatileKey extends Thread { volatile boolean flag = false; public void run() { while (!flag) { System.out.println("run"); } System.out.println("stop"); } public static void main(String[] args) throws Exception { VolatileKey vt = new VolatileKey(); vt.start(); Thread.sleep(2000); vt.flag = true; } }
去掉volatile关键字后,线程不会主动停止。
造成这种问题的原因主要是JVM对内存分配的优化,不加volatile时,线程会保存副本,而不是每次都从主内存获取。而volatile限制线程不进行内部缓存和重排,既而解决掉可见性问题。
啰嗦一句:实现多线程的三种方式,一种是继承Thread类使用此方式就不能继承其他的类了,还有两种是实现Runnable接口或者实现Callable接口。
三、JAVA语法糖
语法糖主要目的,为了方便开发和减少开发时、编译期、运行前以及语法错误。
语法糖就是通过二次封装,提供更加简单的操作,比如变长变量,不用程序员定义一个超长参数列表,或者为了不同个数参数定义多个方法。
但是运行时jvm并不认识这些,这些都在编译期进行了解语法糖,并且转成了jvm认识的东西。
比如说变长变量,用的数组,外层封装好之后,编译期通过增强for循环(话说回来,增强型for循环也是语法糖,内部是while遍历迭代器iterator)进行参数置入。
四、CountDownLatch
CountDownLatch是一个计数器闭锁,通过它可以完成类似于阻塞当前线程的功能,即:一个线程或多个线程一直等待,直到其他线程执行的操作完成。
CountDownLatch用一个给定的计数器来初始化,该计数器的操作是原子操作,即同时只能有一个线程去操作该计数器。当计数器为0时执行await()方法后的代码。
用法:
1.在线程结束时调用.countDown()方法。
2.在主线程合适位置调用.await()方法。
五、CyclicBarrier
作用是设置栅栏阻挡所有线程,当所有线程都完成后才进行后续操作。可循环利用,且提供reset方法重置。
用法:
1.在线程内调用.await()方法,CyclicBarrier会在所有线程都将await前的任务完成时,才继续执行后面的代码(本线程内的)。可以在一个方法内多次调用.await()。
2.和countDownLatch的区别:countDownLatch是减法计数器cyclicBarrier是加法计数器。cyclicBarrier可复用,即一个函数可调用多次.await()方法,且提供rest()函数进行主动重新计数。countDownLatch是一次性的。
六、Semaphore
Semaphore用来控制同时访问某个特定资源的操作数量,或者同时执行某个指定操作的数量。还可以用来实现某种资源池限制,或者对容器施加边界。比如限制最大5个人同时访问。
用法:
1.Semaphore semp = new Semaphore(5);//创建通行5个线程
2.semp.acquire();//发放通行证
3.semp.release();//释放资源
当同时访问线程数大于等于5个时,会阻塞,达到限流目的。
七、有关List的set()方法、ArrayList扩容相关
1.public E set(int index, E element)其功能是覆盖掉原index位置上的元素,注意!!!index位置上必须有数据才可操作,否则报IndexOutOfBoundsException异常。
源码ArraList判断如下:
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
2.ArrayList扩容(jdk1.7):
当创建一个List时,如List a = new ArrayList(20);会分配20个空间。
当第21个元素添加进来时,判断需要的空间是否大于当前数组长度,即21>20,源码:
if (minCapacity - elementData.length > 0)
grow(minCapacity);
进行扩容且扩容1.5倍(右移1位,源码:int newCapacity = oldCapacity + (oldCapacity >> 1);),即将数组复制到更大的数组中。
八、有关yield()方法
功能为:暂停当前正在执行的线程对象,并执行其他线程。
注意:yield()让当前运行线程回到可运行状态,以允许具有相同优先级的其他线程获得运行机会,但是不保证一定让其他线程执行,因为有可能会被再次选中。
所以yield()从未导致线程转到等待/睡眠/阻塞状态。在大多数情况下,yield()将导致线程从运行状态转到可运行状态,但有可能没有效果。
九、有关设计模式
模版模式:定义一个算法结构,而将一些步骤延迟到子类去实现
备忘录模式:在不破坏封装的前提下,保持对象的内部状态
抽象工厂:创建相关或依赖对象的家族,而无需指明具体类
组合模式:将对象组合成树形结构以表示部分和整体的层次结构
单例模式有懒汉(调用时实例化)、饿汉(定义时实例化)、双重锁(即懒汉模式加锁,并在锁内再次判断是否为空)、枚举。
十、有关访问权限

十一、有关接口和类的问题
十二、Java执行顺序
public class TestOne extends TestTwo { public static ThreeTest demo = new ThreeTest("子类"); public TestOne() { System.out.println("子类构造函数"); } { System.out.println("子类代码块"); } static { System.out.println("子类静态代码块"); } public static void main(String[] args) { new TestOne(); } } class TestTwo { public static ThreeTest demo = new ThreeTest("父类"); public TestTwo() { System.out.println("父类构造方法"); } static { System.out.println("父类静态代码块"); } { System.out.println("父类代码块"); } public static void find() { System.out.println("静态方法"); } } class ThreeTest { public ThreeTest(String flag) { System.out.println(flag + "静态变量构造函数"); } }
问:执行顺序是怎样的。首先Java执行顺序是:
1.有父类:父类静态变量初始化——>父类静态代码块——>子类静态变量初始化——>子类静态代码块——>父类代码块——>父类构造函数——>子类代码块——>子类构造函数
2.只有子类:子类静态变量初始化——>子类静态代码块——>子类代码块——>子类构造函数
十三、面试题坑
题目:可以把任何一种数据类型的变量赋给Object类型的变量。判断对错。
答案:正确。虽然基础数据类型不是对象,但可以赋值给Object变量,震惊。
题目:下列哪个选项是Java调试器?如果编译器返回程序代码的错误,可以用它对程序进行调试?
java.exe
javadoc.exe
jdb.exe
javaprof.exe
答案:jdb.exe。
解析:
java.exe是java虚拟机
javadoc.exe用来制作java文档
jdb.exe是java的调试器
javaprof.exe是剖析工具
十四、有关算法时间复杂度的概念:
算法的时间复杂度是一个函数,它定性描述该算法的运行时间,用O(f(n))表示,即O()。在上学时一直有疑问,明明是O(2n^2+11),却要说时间复杂度是O(n^2),最高阶的常数项、加的常熟没有了。
是因为在比较时间复杂度时,其增长率主要受高阶的影响,如果最高阶存在且不是1,则去掉高阶的常数项及尾随的常数。如O(2n^5+5N+5)复杂度即为O(n^5)
十五、JDK1.8中,HashMap 求某KEY值hash的原理:
(h = key.hashCode()) ^ (h >>> 16) 即用key的hasCode的高位与hashCode进行异或。这样的好处是把hashCode的高位也进行了计算,更加散列。
如果只计算低位,会增加hash冲突。
计算索引时,源码为
if ((p = tab[i = (n - 1) & hash]) == null)
即 i=(n-1)&hash 进行求余操作。
十六、Thread、ThreadLocal、ThreadLocalMap
ThreadLocal主要是做到线程间数据隔离,从而达到多线程安全的效果,与Synchronized完全不同。
ThreadLocalMap的代码位置在ThreadLocal里,并且是一个静态内部类。
而每一个Thread里都会有ThreadLocalMap实例,所以TheadLocal里保存变量的集合就是此map。
由于ThreadLocalMap里的entry里的Key部分采取的弱引用,如果ThreadLocal没有强引用指向它,则不会阻止GC回收ThreadLocalMap里Entry的Key部分,但是Value部分却是强引用。就会导致内存泄漏。
所以推荐ThreadLocal采用静态声明或每次用完都调用一次remove()函数。
十七、牛客网题
今天刷到一个有关内存和引用很直观的题,mark!
以下代码结果是什么? public class foo { public static void main(String sgf[]) { StringBuffer a = new StringBuffer(“A”); StringBuffer b = new StringBuffer(“B”); operate(a, b); System.out.println(a +”.”+b); } static void operate(StringBuffer x, StringBuffer y) { x.append(y); y = x; } }
答案是AB.B。往方法中传参,传的仅仅只是地址,而不是实际内存,所以不要以为y=x程序的执行,是 b=a的执行。这两者是不相等的
十八、集合相关
- JAVA中容器分为Collection和Map
- Collection是线性集合,而Map是典型的Key-value数组+链表(本质上是一个映射)形式。
- Collection中的linkedList和ArrayList,link是链表形式,链表的优点就是增、删快。而ArrayList是是典型的数组,数组的优点是查、改快。
- array和link在增删时,最大的时间差距在array需要扩容、复制、将左边的数据集体右移。在查找时,由于数组在分配空间时就是连续的,而link需要去不断寻址。
- HashMap几乎可以等价于Hashtable(不过效率是有差距的,毕竟HashTable加了锁),除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
- 有关HashMap放入新元素时有哪些操作。调用put方法是很简单的,但是put方法内部真的做了超级多事情。
首先HashMap存放的数据都是Node节点,Node节点有hash(int型),key,value,下一个Node引用。如下图所示:
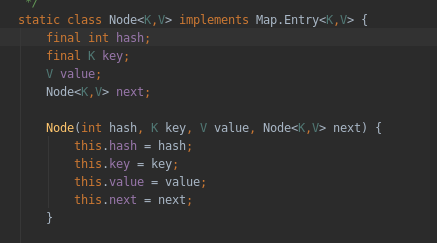
在put时,会判断map的数据集table是否为空,空就创建一个数组用于存放Node。
如果当前位置为空,则创建一个新的Node放入table数组中。如图所示:

如果这个hash值的位置有数据了,并且key相等,则覆盖。

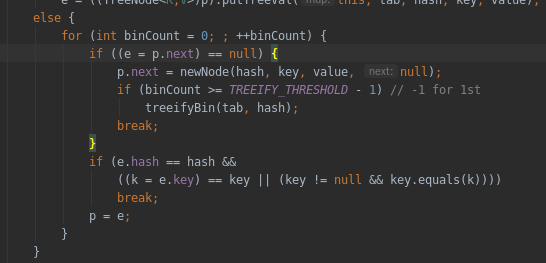
如果是TreeNode,就放入树中。

其他情况下,尾插。1.8之前是头插法,据说是为了避免死循环(多线程下resize导致),等查好了更新此处。
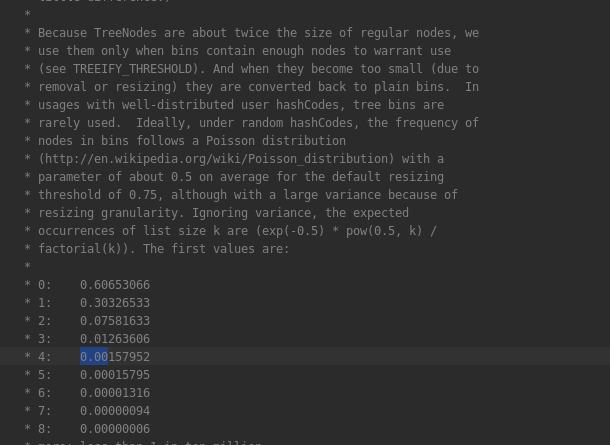
至于为什么hash冲突数大于8这个数作为链表转树的临界值,注释中说是按照帕松公式来的。。。链表中元素个数为8时的概率已经非常小。。。所以转成树的消耗是值得的。
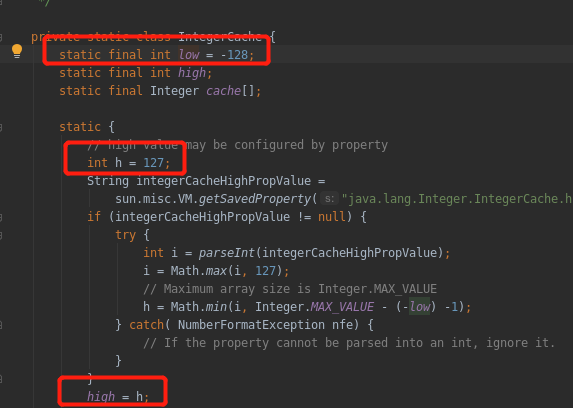
十九、有关于Integer比较
Interger的范围时[-128,127],在这个范围内比较大小,相等为true,超过范围为false。
在JDK1.8中,如果用Integer.valueOf();也会判断是否是小于-128或大于127才会创建新的实例,否则直接用常量池的。但是要注意,只要new Integer那就一定创建了新的引用。

二十、有关try catch finally
在try语句块或catch语句块中执行System.exit(0)会直接退出而不执行finally块。
二十一、有关URL类
执行URL url = new URL("www.aaa.com");时,不管www.aaa.com是否存在,url的值都是www.aaa.com。如果格式异常则会抛出MalformedURLException异常。
二十二、语法总结
1.抽象类可以包括抽象方法和非抽象方法。
2.只要有抽象方法,则所属类必须是抽象类。
3.JAVA中整数相除,比如13/5,结果只取整,不四舍五入,即结果为2。
4.Object中的方法:hashCode、equals、toString、clone、notify、notifyall、wait、finalize、getClass。
5.Math.Floor(double d);向下取整方法会返回double数值。传入参数也可为int。