照例传送门CNUOJ - 0385:http://oj.cnuschool.org.cn/oj/home/problem.htm?problemID=355
题目分析:首先感谢”数据结构与算法“群群友的支持与鼓励,没有你们的点拨&鼓励我不可能搞出来的。
这道题如果是暴力枚举循环节的话,可能数据会坑你一下……(只有一个循环节即两数互质= =)那就挂了……暴力好像也能拿30分吧。
这道题算法的雏形是Kael大神弄出来的,他是这么跟我说的:
假设是|T|>|S|,因为|A|=|B|,所以S与T的比较周期有|T|个,再检查S中的每个字符与T中字符不一样的个数,就得到所有周期比较完后的个数,然后把S中每个字符的个数加起来就是答案,如果|A|大于了|T|和|S|的最小公倍数,就把答案乘以M/|T|,M/|T|又是新一轮周期。
为什么S与T的比较周期有|T|个呢?通俗的说就是S中的每个字符都会跟T中的每个字符进行对位一次,而再次当S第一个字符与T第一个字符对位时,就是进行了|T|个周期了。
看不懂是吧?知道你也不会好好看,我来给你分析一下= =
比如这两个长度互质的串:
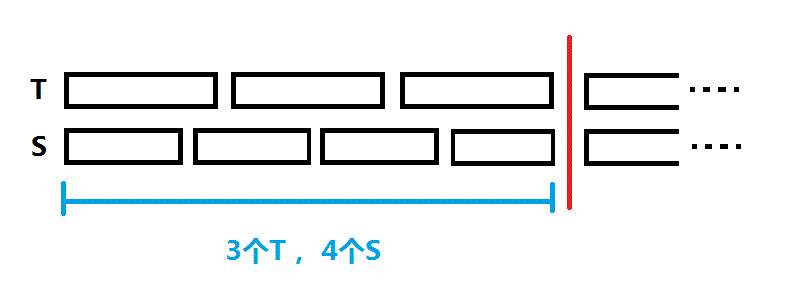
把长度标上后,让我们关注一下S串头元素进行了哪几次比较:
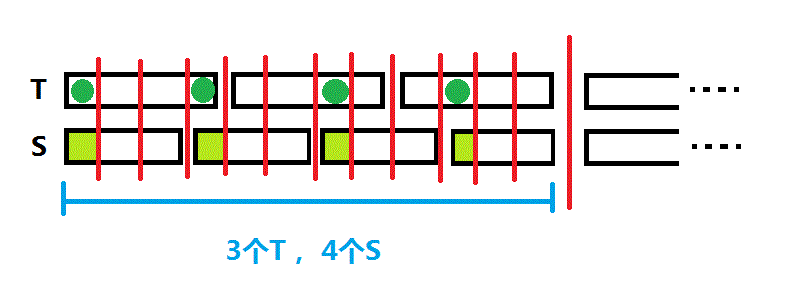
可以看到共有4次比较(用深绿色圆圈表示),我们发现这不就是T串里的4个元素吗?
好,那我们看看在T串上S的头元素是怎么比较的:
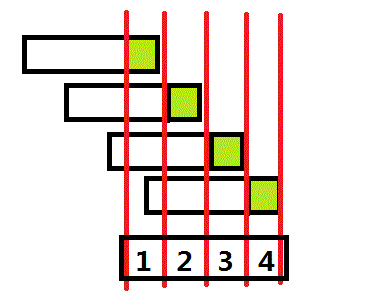
上面四个是S串,底下的是T串。我们来举一个例子:
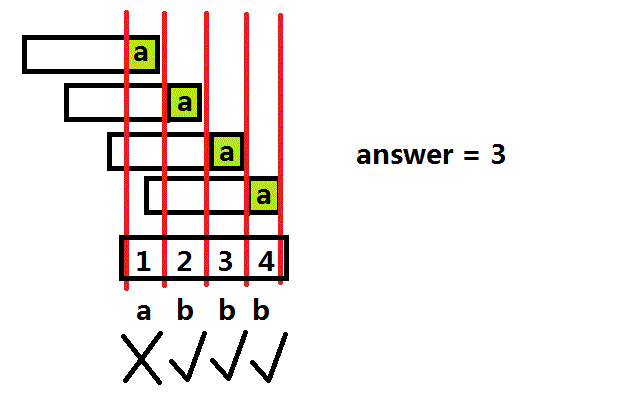
所以说头元素贡献了3份答案。
那么显而易见,不仅S串头元素会全都比较T串的四个元素,第二个、第三个元素也会比较,我们再画一个清晰的图:
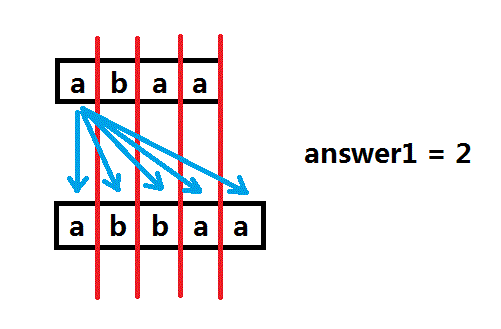
上面是S串,下面是T串,先让上面最左边的”a“进行一次全部比较,可以看到有2个答案。
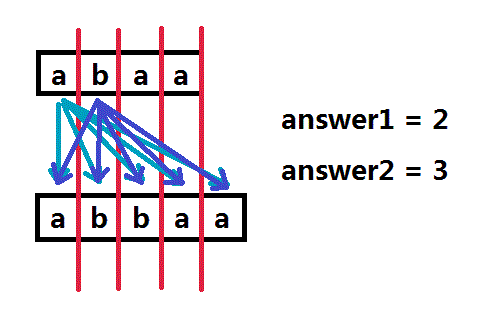
第二个元素同理有三个答案。
第三、第四个S串里的”a“元素答案一定和answer1是一样的(想一想,为什么?)
最后根据加法、乘法原理,答案应该是:3 * answer1 + 1 * answer2 = 3 * 2 + 1 * 3 = 9;
画回最原始的图再看一眼:
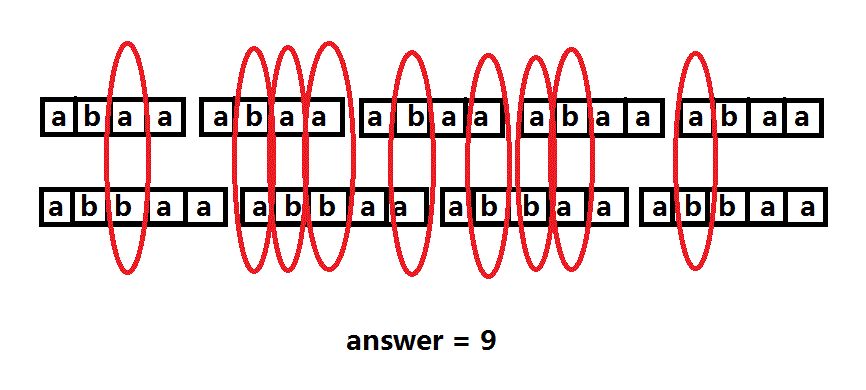
答案正确。此输入应该是:5 4 abaa abbaa 输出是:9
那如果输入的是10 8 abaa abbaa呢?
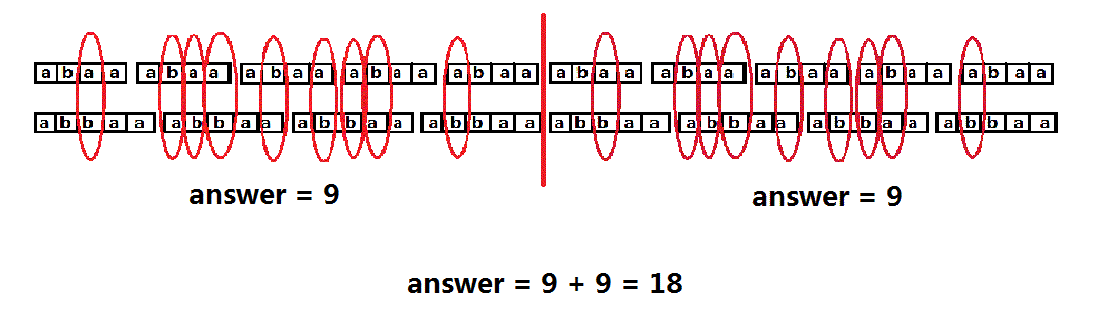
那么就应该有两个循环节了,答案是18。
那么至此为止,两字串长度互质的情况我们已经会算了,可以用两个哈希表vis_S[27], vis_T[27]分别表示26个小写字母在S串和T串中分别出现了几次。
程序不难写出,建议读者好好看一眼哈希表的使用,为下边打好基础:
1 #include <iostream> 2 #include <cstdio> 3 #include <algorithm> 4 using namespace std; 5 6 void read(int& x) 7 { 8 x = 0; 9 int sig = 1; 10 char ch = getchar(); 11 12 while(!isdigit(ch)) 13 { 14 if(ch == '-') sig = -1; 15 ch = getchar(); 16 } 17 18 while(isdigit(ch)) 19 { 20 x = x * 10 + ch - '0'; 21 ch = getchar(); 22 } 23 24 return ; 25 } 26 27 int tot; 28 29 long long ans; 30 31 const int maxn = 1000000 + 10; 32 33 char S[maxn], T[maxn]; 34 int T1, T2; 35 36 int vis[2][27]; 37 38 int read_str1() 39 { 40 char tmp = getchar(); 41 42 while(!isalpha(tmp)) tmp = getchar(); 43 44 tot = 0; 45 46 while(isalpha(tmp)) 47 { 48 S[tot++] = tmp; 49 50 vis[0][tmp - 'a']++; 51 52 tmp = getchar(); 53 } 54 55 S[tot] = '�'; 56 return tot; 57 } 58 59 int read_str2() 60 { 61 char tmp = getchar(); 62 63 while(!isalpha(tmp)) tmp = getchar(); 64 65 tot = 0; 66 67 while(isalpha(tmp)) 68 { 69 T[tot++] = tmp; 70 71 vis[1][tmp - 'a']++; 72 73 tmp = getchar(); 74 } 75 76 T[tot] = '�'; 77 return tot; 78 } 79 80 void vis_init() 81 { 82 long long tmp; 83 84 for(int i = 0; i < 27; i++) 85 { 86 tmp = 0; 87 for(int j = 0; j < 27; j++) 88 { 89 if(i == j) continue; 90 tmp += vis[1][j]; 91 } 92 ans += vis[0][i] * tmp; 93 } 94 95 return ; 96 } 97 98 int main() 99 { 100 read(T1); 101 read(T2); 102 103 int s1 = read_str1(); 104 int s2 = read_str2(); 105 106 vis_init(); 107 108 ans = (long long)((double)ans * ((double)T1 / (double)s2)); 109 //记得是同时约了一个s1 110 111 printf("%lld ", ans); 112 113 return 0; 114 }
好,那么我们来看看非互质的情况:
先来说一下为啥互质与非互质不同,感谢路人们贡献的反例:
比如 3 2 abac ababac:

如果用互质法来解答案应该是:2 * 3 + 1 * 4 + 1 * 5 = 15 (想想都觉得多= =)
正解看下图:
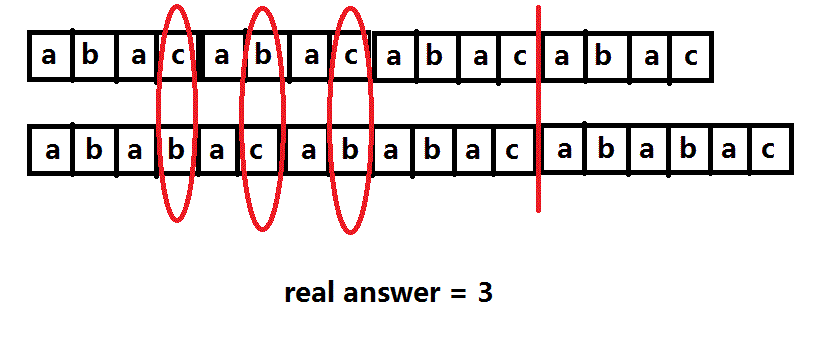
正解是3,少了一大堆,那为啥一不互质就不行了呢?
先来看以前那个图:
可以看到,上面的S串的头元素(还记得吗?)与下面的T串全都进行了比较。但是在非互质情况里则不一定,我们来看一眼刚才那个例子:
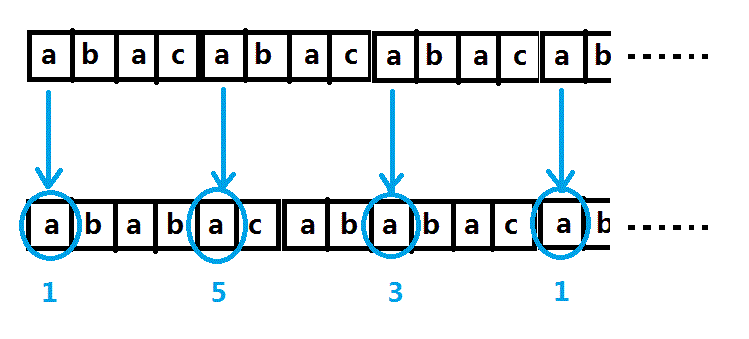
S串头元素与T串的1,3,5进行比较(注意不是全部元素了!)
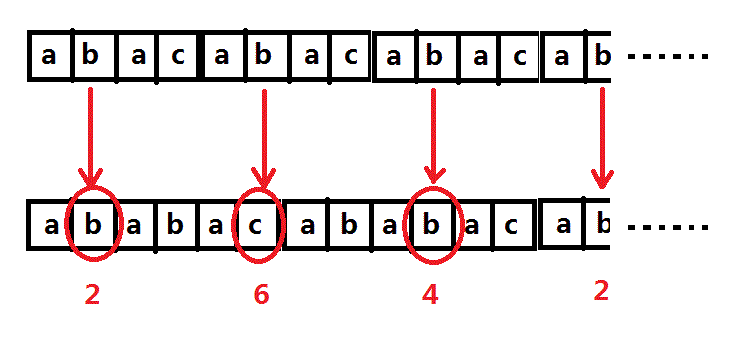
S串第二元素元素与T串的2,4,6进行比较:(S和T老忘了打你们将就看吧……)
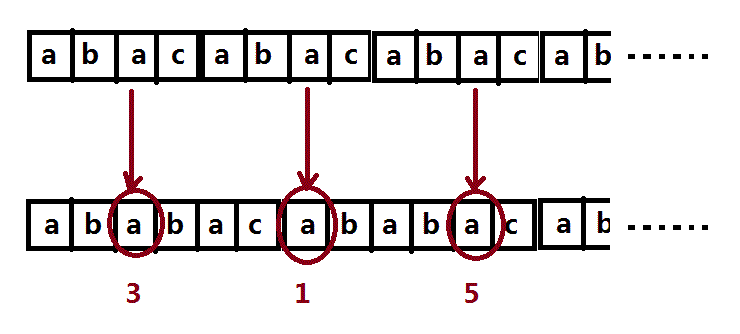
S串第三元素元素与T串的1,3,5进行比较:
(插:你们写博客一定要随时保存,刚才一断网后面写的全没了TAT,还有插图一定要随时保存TAT)
那么我们来看,对于S串的元素来说,他们都和T串的一个子串相对应(在这里就是1,3,5 和 2,4,6)
把S串的每一个元素单独分析,对于S串第一个元素a,在第一个子串(以后讲为什么叫做“第一个”)中进行询问,答案是0。
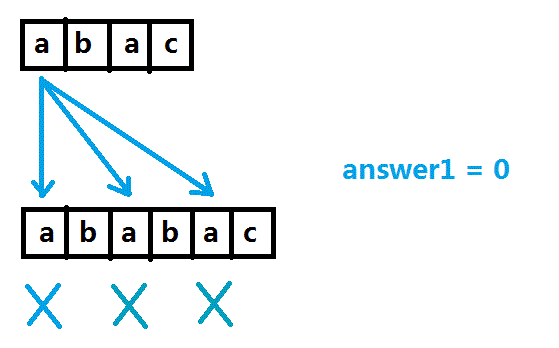
对于S串第二个元素b,在第二个子串中进行询问,答案是1。
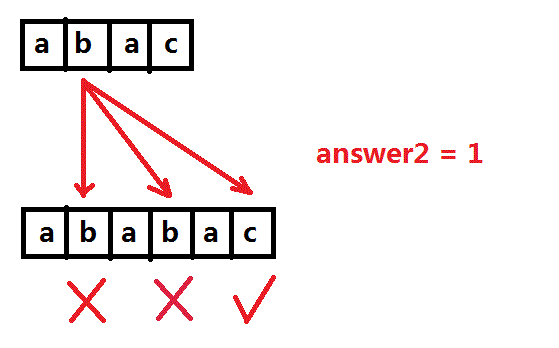
同理,对于S串第三、四个元素a、c,分别在第一、二个子串中进行询问,答案是0和2。
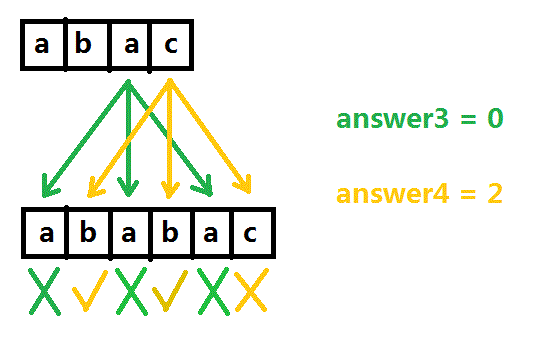
与互质算法同理,得到最后的答案0 + 1 + 0 + 2 = 3
在分析过程中我们为了区分不同的T串的子串所以给他们分别表上了号,待会会再说这个编号。
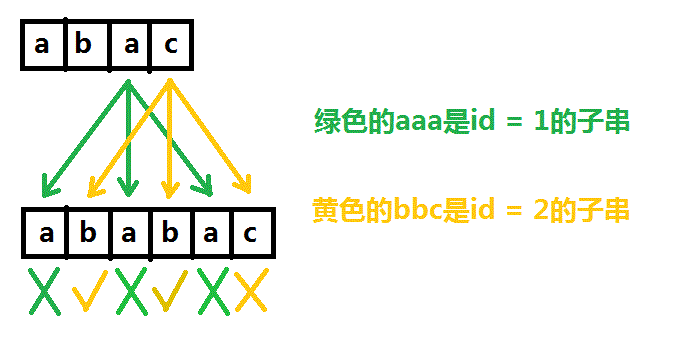
那么这些字串有什么规律呢?首先可以看出来他们是穿插的,其次发现他们每个串的“间隔”是一样的,比如看上面的图:绿色的1号子串aaa中每个a都差了2个格(我们定义相邻为差了一个空格),黄色的2号子串bbc中每个元素也都差了2个格。这个2有什么特殊含义呢?请读者自己画一画下面两个数据的子串。
1. 4 2 ab abac
2. 9 3 ab ababac
不难发现(这四个字会不会伤了很多人的心…),两个字串长度的最大公约数即是子串元素间的间隔长度 以及子串的个数
那我们可以借此规律为子串标号,还是上图,绿色的就叫1号,黄色的就叫2号。因此我们将T串分成了许多个相互穿插的子串,每一部分都可以用互质算法进行求解,不再赘述。
还有很关键的一点是:如何存放这些子串的信息?原来存放一个T串我们用了只一个哈希表,那么现在我们可以用标号造一大堆哈希表分别对应每一个子串。说白了,就是在vis前面再多一维度。
我们用vis1[id][i]表示S串内第id个串中字母i出现的次数(这里是字母编号),相应的,用vis2[id][i]表示T串内第id个串中字母i出现的次数。
下面给出代码,请读者留意哈希表id的运用。
1 #include <iostream> 2 #include <cstdio> 3 #include <algorithm> 4 using namespace std; 5 6 void read(int& x) 7 { 8 x = 0; 9 int sig = 1; 10 char ch = getchar(); 11 12 while(!isdigit(ch)) 13 { 14 if(ch == '-') sig = -1; 15 ch = getchar(); 16 } 17 18 while(isdigit(ch)) 19 { 20 x = x * 10 + ch - '0'; 21 ch = getchar(); 22 } 23 24 return ; 25 } 26 27 int gcd(int a, int b) 28 { 29 return b == 0 ? a: gcd(b, a % b); 30 } 31 32 int tot; 33 34 long long ans; 35 36 const int maxn = 1000000 + 10; 37 38 char S[maxn], T[maxn]; 39 int T1, T2; 40 41 int vis1[maxn/4][27]; //放maxn内存超限,具体情况看下文分析。 42 int vis2[maxn/4][27]; 43 44 int HASH; 45 46 int s1, s2; 47 48 int read_str1() 49 { 50 char tmp = getchar(); 51 52 while(!isalpha(tmp)) tmp = getchar(); 53 54 tot = 0; 55 56 while(isalpha(tmp)) 57 { 58 S[tot++] = tmp; 59 tmp = getchar(); 60 } 61 62 S[tot] = '�'; 63 return tot; 64 } 65 66 int read_str2() 67 { 68 char tmp = getchar(); 69 70 while(!isalpha(tmp)) tmp = getchar(); 71 72 tot = 0; 73 74 while(isalpha(tmp)) 75 { 76 T[tot++] = tmp; 77 tmp = getchar(); 78 } 79 80 T[tot] = '�'; 81 return tot; 82 } 83 84 void solve() 85 { 86 for(int i = 0; i < s1; i++) 87 vis1[i % HASH][S[i] - 'a']++; 88 89 for(int i = 0; i < s2; i++) 90 vis2[i % HASH][T[i] - 'a']++; 91 92 return ; 93 } 94 95 void vis_init() 96 { 97 long long tmp; 98 99 for(int id = 0; id < HASH; id++) 100 { 101 for(int i = 0; i < 27; i++) 102 { 103 tmp = 0; 104 for(int j = 0; j < 27; j++) 105 { 106 if(i == j) continue; 107 tmp += vis2[id][j]; 108 } 109 ans += vis1[id][i] * tmp; 110 } 111 } 112 113 return ; 114 } 115 116 int main() 117 { 118 read(T1); 119 read(T2); 120 121 s1 = read_str1(); 122 s2 = read_str2(); 123 124 HASH = gcd(s1, s2); 125 126 solve(); 127 128 vis_init(); 129 130 printf("%lld ", ans); 131 132 return 0; 133 }
还有一个小问题,就是第41行开哈希表的时候,由于内存不够,我们这里用的是maxn/4,数据通常不会给两个长度相同或呈二倍关系的子串吧?这分就这么到手了。如果要写出完美解答,可以事先加一个判断:如果两字串长度相等或呈2倍关系就直接暴力循环节也行。(此代码略,感兴趣的读者可写一遍)
最后我们来比较一下暴力循环节法和这种数学方法的优劣:
当两字串长度极为接近或互质,那么几乎没有循环节,此数学方法反而效率极高且十分省内存(哈希表成一维了),而暴力循环节绝对会爆掉。
当两字串公共因子极多时,可能会出现大量循环节,这时暴力循环节发效率增高,而此数学方法内存会一下多出很多(效率是不变的,请读者尝试证明)。
所以说,两种方法各有优劣,但综合来看数学方法更加稳定且效率高。如果追求完美,可以尝试一半用暴力一半用数学,程序一秒就能高大上,带你逗逼带你飞~。