1.利用客户端操作Document文档数据
1.1 创建一个文档(创建数据的过程,向表中去添加数据)
请求方式:Post 请求地址:es所在IP:9200/索引库/Type/文档ID(可给可不给,代表唯一标识,如果不给则会生成默认的字符串)
请求体
{ "id":2, "title":"Lucene是apache软件基金会4 jakarta项目组的一个子项目", "content":"Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的" }


1.2 修改文档数据:根据文档ID修改数据
请求方式:Post 请求地址:es所在IP:9200/索引库/Type/修改的文档ID
请求体
{ "id":2, "title":"[修改]Lucene是apache软件基金会4 jakarta项目组的一个子项目", "content":"[修改]Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的" }
1.3 删除文档数据:根据文档ID删除数据
请求方式:DELETE 请求地址:es所在IP:9200/索引库/Type/文档ID
2.文档数据的查询
2.1 根据文档ID查询文档数据
请求方式给GET 请求地址:es所在IP:9200/查询的索引库/查询的类型/查询的文档ID

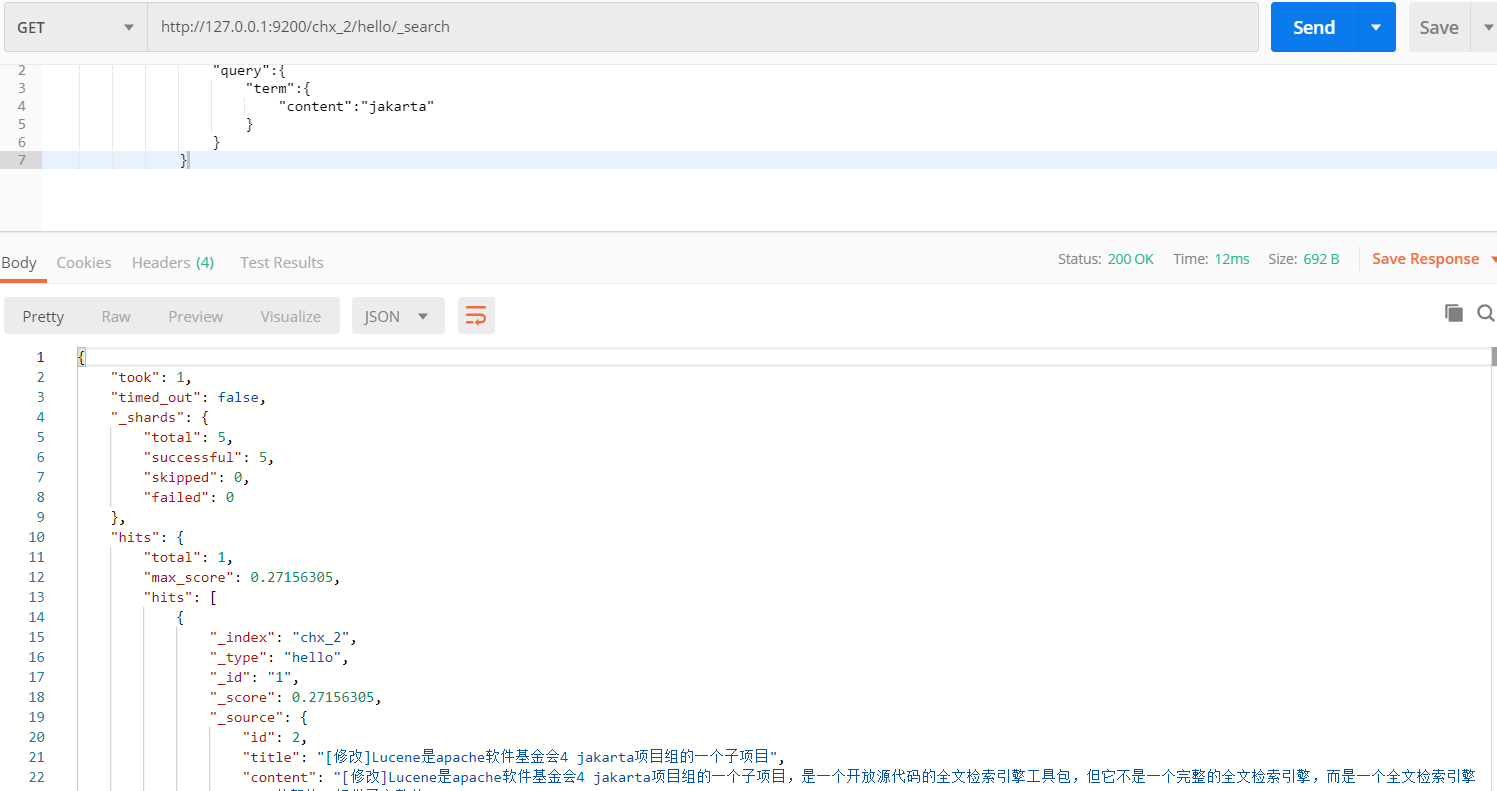
2.2 根据关键词查询文档数据
请求方式给GET 请求地址:es所在IP:9200/查询的索引库/查询的类型/_search
请求体当中指定要查询那个域当中的哪个关键词
{ "query":{ "term":{ "content":"java" } } }
没有查到的效果
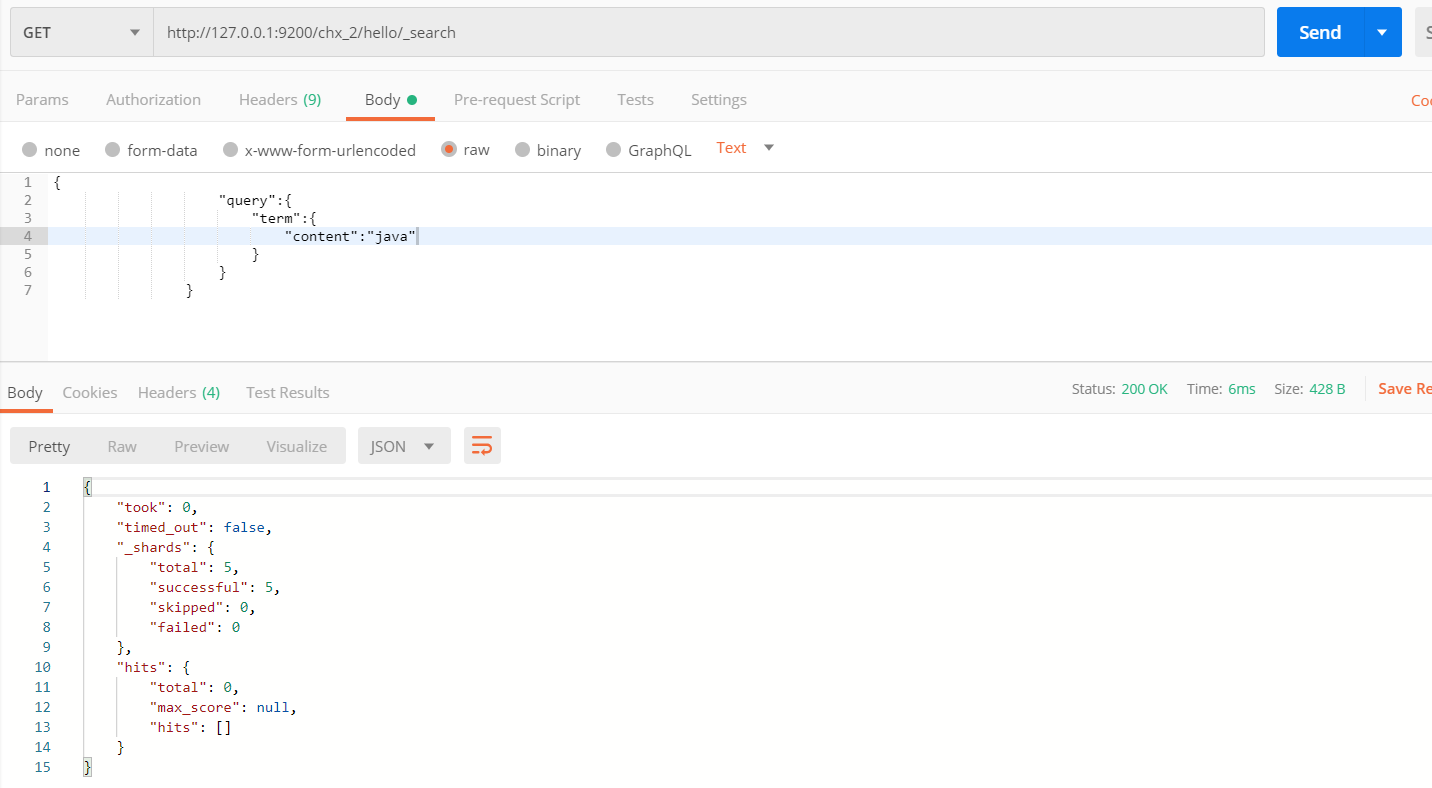
查到的效果
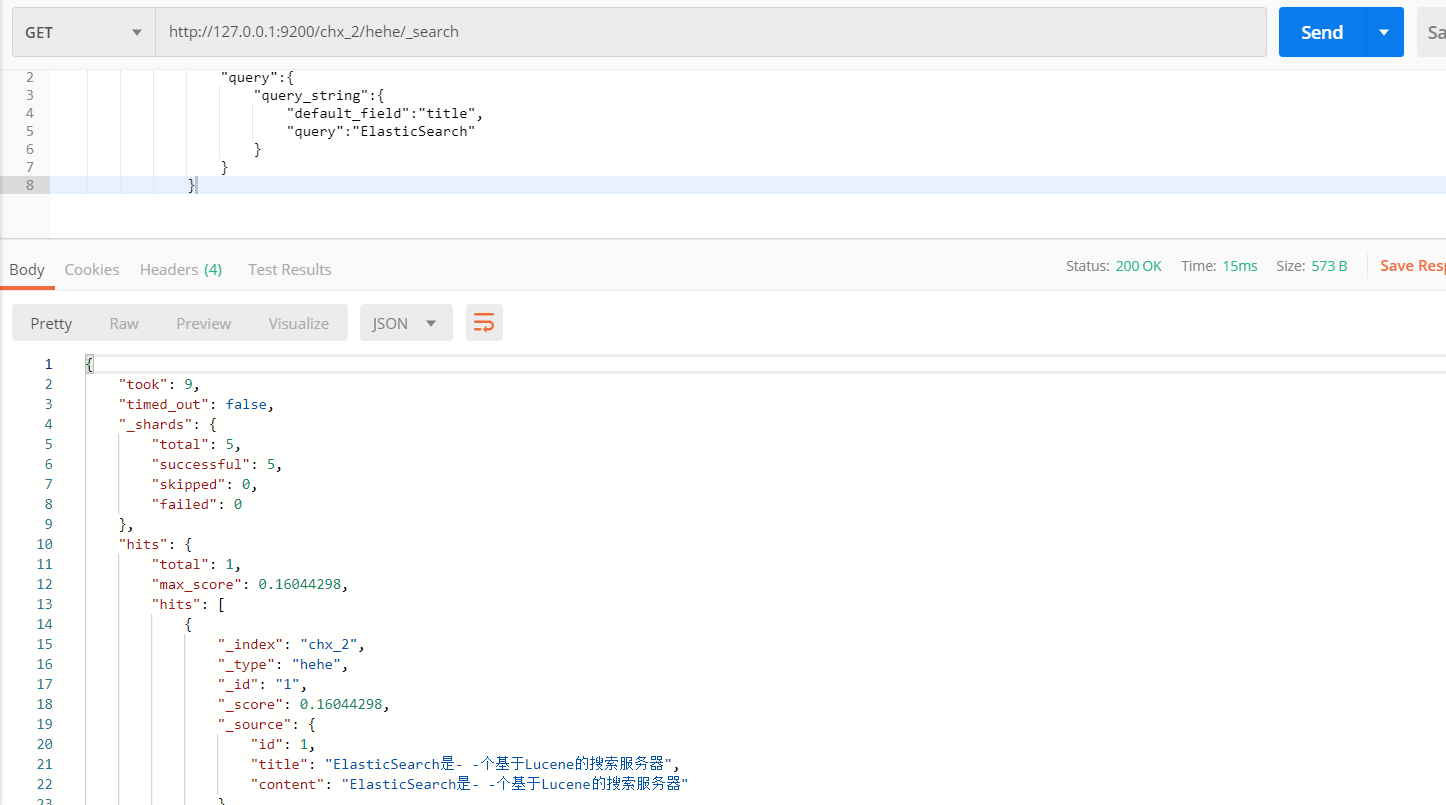
2.3 QueryString,将搜索内容分词后再查询
请求方式给GET 请求地址:es所在IP:9200/查询的索引库/查询的类型/_search
请求体当中指定要查询那个域当中的一段话,会将查询的条件先分词再查询
{ "query":{ "query_string":{ "default_field":"title", "query":"ElasticSearch" } } }
默认不分词效果

分词效果