工具及环境
1、操作系统:windows 64位系统
2、软件工具:谷歌浏览器、pycharm集成开发工具
3、第三方库:request
注:如果第三方库搭建有困难,请看博客:https://www.cnblogs.com/chuijingjing/p/9157049.html
明确要目标
首先,我们了解一下什么是爬虫。网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
我们今天要爬的内容是百度音乐里面的音乐,为什么要爬百度音乐呢?当然是因为这个软件太垃圾了,根本没有反扒机制,所以我们挑软柿子捏。像我们的信仰网易云音乐是不可能让我们轻易爬到它的内容的,如果想要爬网易云,要有防反爬机制。我们这次只是简单介绍爬虫的原理,写一个小小的爬虫,下次我会给大家带来一个加入防反爬机制复杂的爬虫。话不多说,让我们开干!
说干咱就干
1、脉络梳理
首先,我们把要做的工作先来大体梳理一下,好有一个清晰的脉络。
1.爬虫的本质(模拟浏览器的行为) 网络爬虫; 模拟浏览器,访问互联网资源,根据我们制定的规则, 批量的下载我们所需要的数据的程序。 2.利用谷歌浏览器分析http请求 网络资源(例如:网上的歌曲、图片),每一个网络 资源都有全球唯一的一个url。 url(全球统一资源定位符) F12 打开 network选项监控http请求 3.分析百度音乐的请求流程 下载mp3 倒推法 1、先找到mp3的下载请求 2、歌曲的下载地址也是从服务器请求回来的, 找到下载地址的那个请求,根据歌曲id 3、找到歌曲的id 4.通过python去实现请求
2、浏览器设置
我们先进入“百度音乐”,搜索你喜欢的歌手的音乐,我比较喜欢华仔。然后点击浏览器右上方的三个点,选择“更多工具”,选择“开发者工具”,进入开发者模式。或者直接按“F12”进入开发者模式。
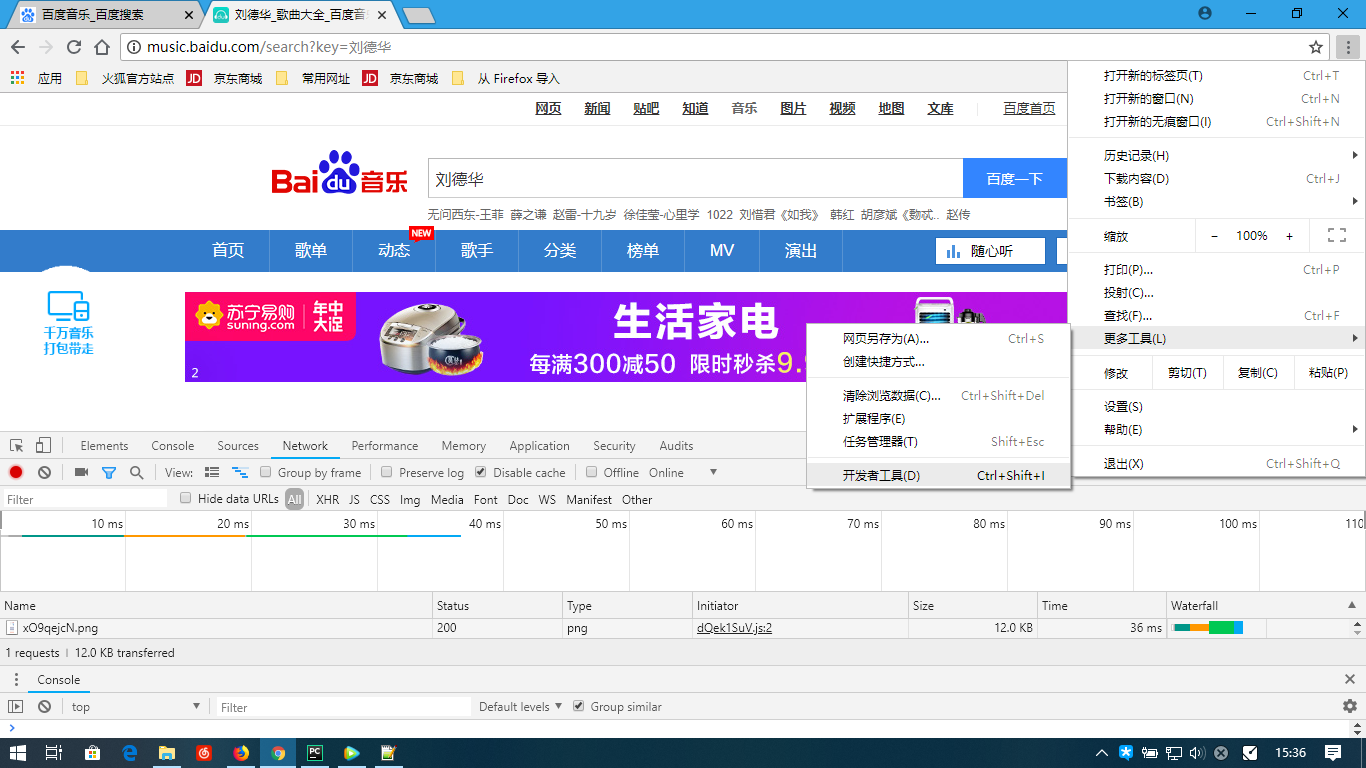
点击“Network”,在“Disable cache”前面打上√,不要去缓存,否则死活找不到请求的数据
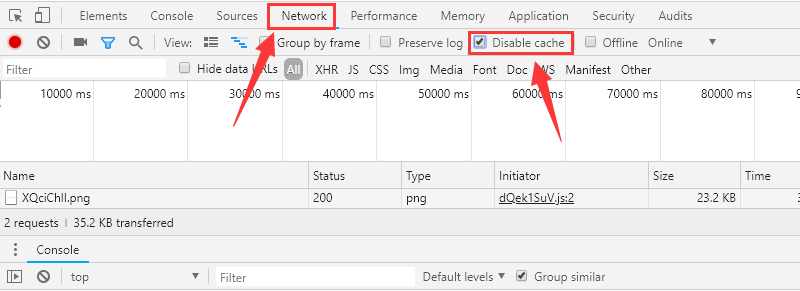
按照1、2、3、4、5的顺序做下来
1:清空内容;
2:回车,发出请求;
3:查看所有请求的信息;
4:每个请求的名字;
5:每个请求的详细信息。
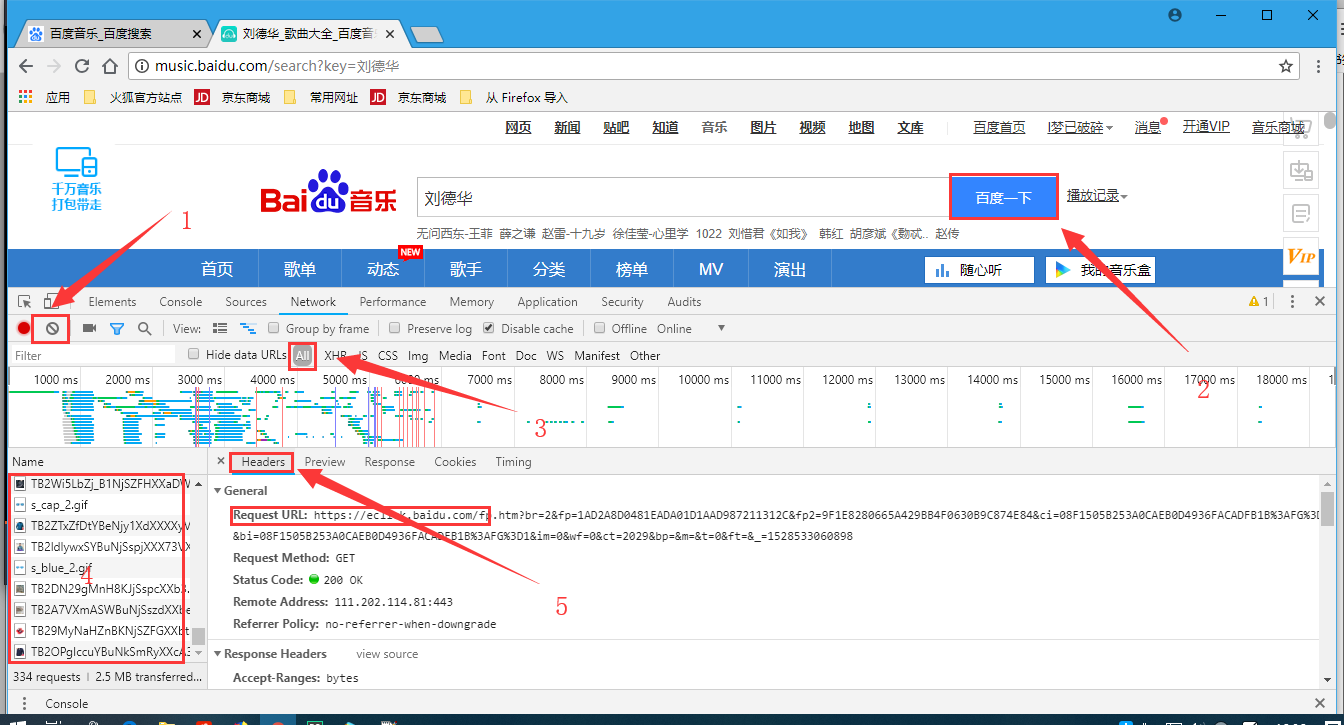
Header:头信息
先点完上面三个标注按钮,然后点击播放按钮,播放音乐;
音乐播放几秒钟后关闭播放,然后点击下面的三个按钮;
接下来就是分析歌曲的头信息Headers了。
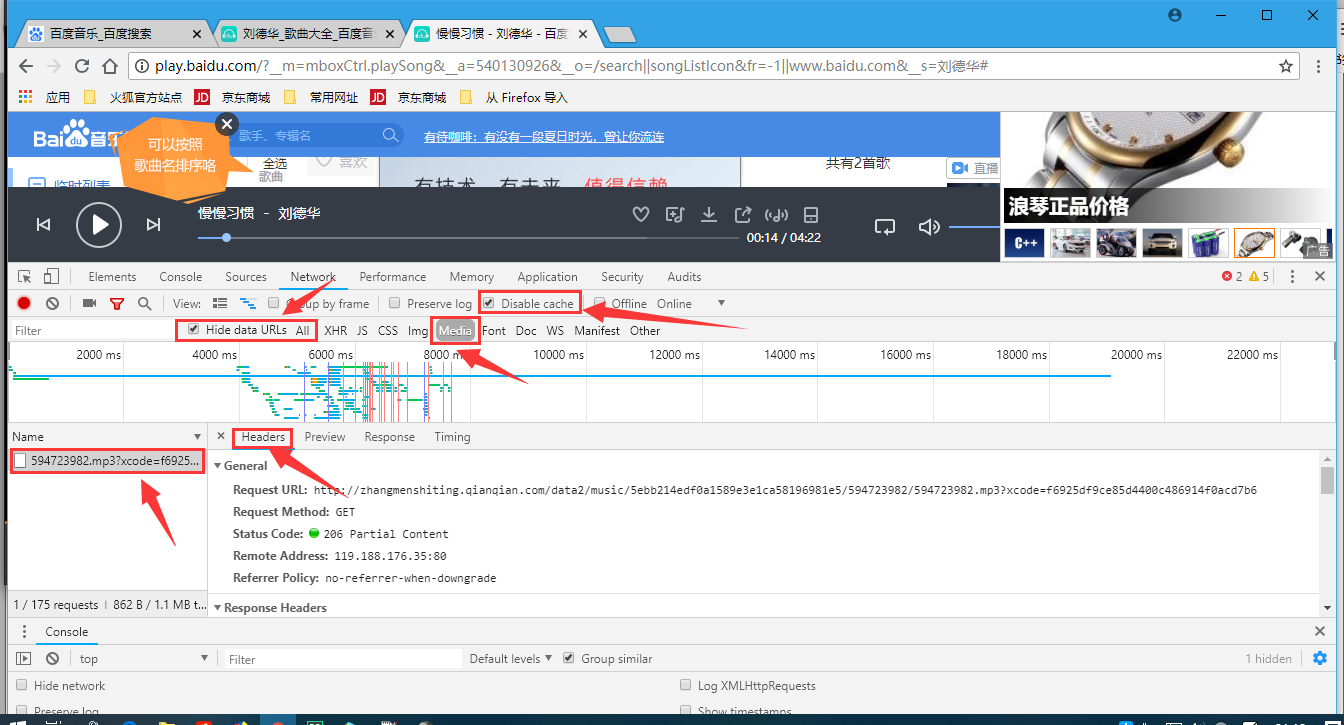
按照图示,找到网页文字对应的网页源码的信息

上面界面中鼠标右键查看页面源码,出现下面的源码界面,按Ctrl+F出现搜索界面,搜索要用到的内容。

3、爬取一首歌曲
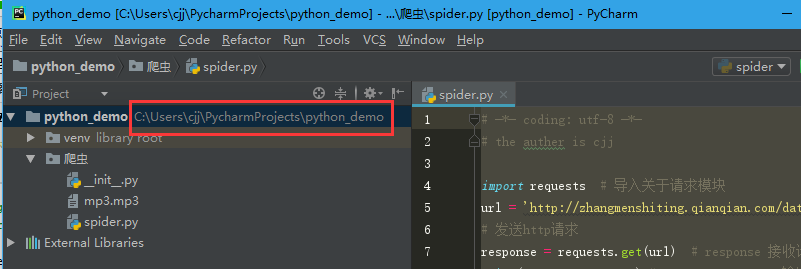
由浅入深,我们先来写一段简单的代码,用它来只爬取一首歌。
# -*- coding: utf-8 -*- # the auther is cjj import requests # 导入关于请求模块 url = 'http://zhangmenshiting.qianqian.com/data2/music/5ebb214edf0a1589e3e1ca58196981e5/594723982/
594723982.mp3?xcode=f6925df9ce85d4400c486914f0acd7b6' # 发送http请求 response = requests.get(url) # response 接收请求回来的数据 print(response.content) # response.content 输出歌曲的二进制信息 # 把下载下来的歌曲储存为mp3文件 with open('mp3.mp3','wb') as f: # 把文件以‘f’的名字命名,下面以‘f’为名字打开 f.write(response.content)
这样,我们就可以实现爬虫的基本功能了,我们来看一下这首歌能不能听。
这是你的代码和歌曲储存地址,我们去这里来找一下华仔的“慢慢”
果然在这里找到了,双击之后发现歌曲可以正常播放。
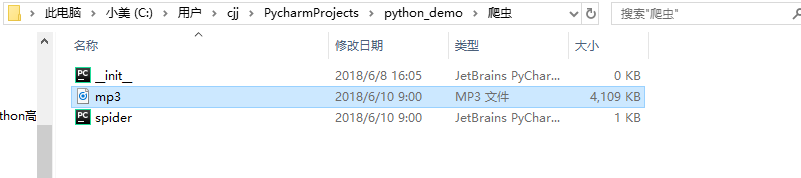
这样,我们完成了一个最简单的歌曲的爬取。
注:文件操作方面如果不了解可以参考:https://www.cnblogs.com/chuijingjing/articles/8034238.html
4、代码演示
文件操作内容:https://www.cnblogs.com/chuijingjing/articles/8034238.html
字典相关内容:https://www.cnblogs.com/chuijingjing/articles/8007387.html
json相关内容:https://www.cnblogs.com/chuijingjing/articles/8074292.html
正则相关内容:http://www.runoob.com/regexp/regexp-syntax.html
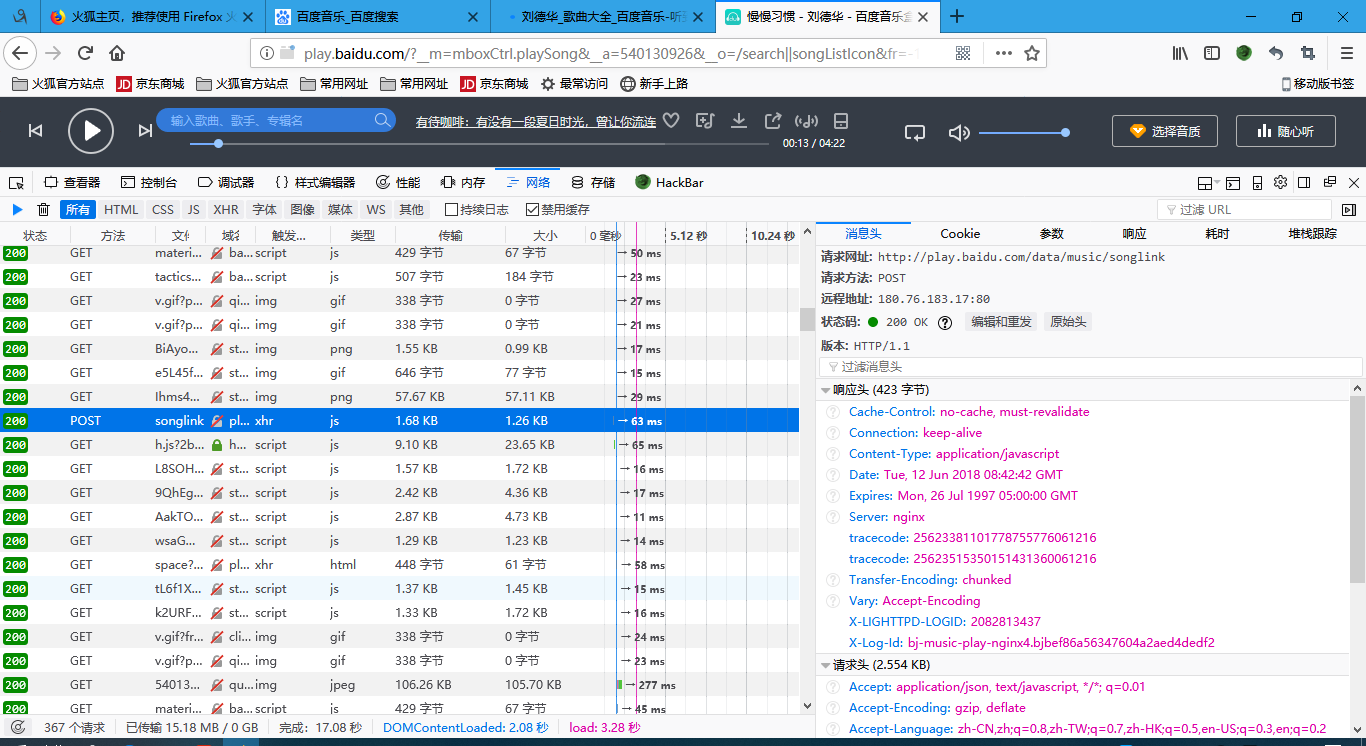
# -*- coding: utf-8 -*- # the auther is cjj import requests import re # 第一步,获取歌曲的ids search_api = 'http://music.baidu.com/search' # 搜索关键字,传递参数,通过字典构造 keyword = {'key': '刘德华'} # 发送get请求 params 是传递的get参数 response = requests.get(search_api, params=keyword) # 取出html的源码 response.encoding = 'utf-8' # 编码转换 html = response.text # 通过正则表达式获取id ids = re.findall(r'{"id":"(d+)"',html) # 第二步,获取歌曲的信息 mp3_info_api = 'http://play.baidu.com/data/music/songlink' data = { 'songIds': ','.join(ids), 'hq': 0, 'type': 'm4a,mp3', 'rate': '', 'pt': 0, 'flag': -1, 's2p': -1, 'prerate': -1, 'bwt': -1, 'dur': -1, 'bat': -1, 'bp': -1, 'pos': -1, 'auto': -1 } # data就是 post的参数 res = requests.post(mp3_info_api,data=data) # 返回值的数据是就送格式,直接调用json方法,转成字典 info = res.json() # 第三步,去下载歌曲 # 根据数据的结构获取歌曲的信息 song_info = info['data']['songList'] # 循环 for song in song_info: # 根据数据结构获取信息 # 歌名 song_name = song['songName'] # mp3地址 song_link = song['songLink'] # 格式 for_mat = song['format'] # 歌词地址 lrclink = song['lrcLink'] print(song_name) # 下载mp3 if song_link: # 可能没有地址 song_res = requests.get(song_link) # 下载 # 写文件 with open('%s.%s' % (song_name, for_mat),'wb') as f: f.write(song_res.content) # 歌曲是二进制 # 下载歌词 if lrclink: lrc_response = requests.get(lrclink) # 写文件 with open('%s.lrc' % song_name, 'w', encoding= 'gbk') as f: f.write(lrc_response.text)
下面是成功爬取到的音乐!
