1.Hive 是什么
是Facebook开源的,用于解决海量的结构化日志统计问题
Hive是构建在Hadoop之上的数据仓库,
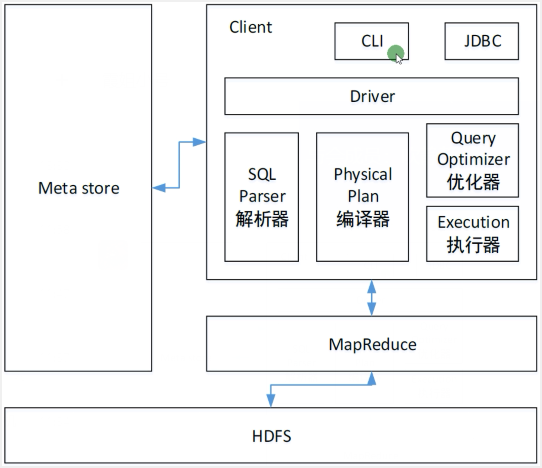
HDFS:Hive的业务数据是存放在HDFS上的(元数据存放在关系型数据库,例如:MySQL)
YARN:Hive的作业是提交到YARN上面去运行的
MR :Hive作业(SQL)是通过Hive的框架翻译成MR作业,MR只是一个计算引擎,现在还支持Tez、Spark引擎
======================================================================================
Hive其实就是一个客户端(提交机器),没有集群概念
任务执行流程:SQL --> Hive --> MR --> YARN
======================================================================================
Hive职责:将SQL翻译成底层对应的执行引擎作业
有统一的元数据(matedata)管理
元数据:描述数据的数据 schema
======================================================================================
架构:SQL on Hadoop
CLI、JDBC:客户端入口,编写sql语句的地方
2.Hive应用场景
批处理/离线处理,延时性很大;
尽量少涉及到update或者delete这种操作,虽然是支持的。
3.Hive vs RDBMS
分布式:都可以部署成分布式场景;
节点数:关系型数据库节点数比较少,Hive节点数不固定;
成本:关系型数据库成本比较高;
数据量:Hive > RDBMS ;
数据修改和删除:关系型数据库支持,Hive 1.4版本之后才支持,但是不建议使用;
事务:都支持,但是Hive不建议,也没有必要使用;
延时性:Hive延时性比较高;