一、Github链接
先附上我的Github链接:https://github.com/chu307/031804106
作业:设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
一开始看到这个题目感觉有点无从下手,想了想先确定使用python语言来进行编程,依赖python强大的库来实现。
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 60 |
| Estimate | 估计这个计划需要多少时间 | 30 | 30 |
| Development | 开发 | 210 | 220 |
| Analysis | 需求分析 | 500 | 480 |
| Design Spec | 生成设计文档 | 45 | 40 |
| Design Review | 设计复审 | 30 | 30 |
| Coding Standard | 代码规范 | 60 | 60 |
| Design | 具体设计 | 150 | 160 |
| Coding | 具体编码 | 150 | 180 |
| Code Review | 代码复审 | 30 | 30 |
| Test | 测试 | 120 | 200 |
| Reporting | 报告 | 20 | 20 |
| Test Report | 测试报告 | 30 | 30 |
| Size Measurement | 计算工作量 | 20 | 20 |
| Postmortem&Process Improvement Plan | 事后总结,并提出过程改进过程 | 30 | 50 |
| 合计 | 1485 | 1610 |
三、计算模块接口的的设计与实现
一开始我引入分词API库jieba、文本相似度库gensim,通过建立语料库。语料库是一组向量,向量中的元素是一个二元组(编号、频次数),对应分词后的文档中的每一个词。然后使用TF-IDF模型对语料库建模,获得原文本每个词的TF-IDF值。最后对每个目标文档,分析测试文档的相似度。经过测试,貌似得到的重复率低的离谱。

最高的重复度只有0.36,而最低的仅仅为0.06,只能把调用gensim库这个方法给pass了。然后看了一些资料,准备采用余弦算法。
原理:对于如何计算两个向量的相似程度问题,可以把这它们想象成空间中的两条线段,都是从原点([0, 0, ...])出发,指向不同的方向。两条线段之间形成一个夹角,如果夹角为0度,意味着方向相同、线段重合;如果夹角为90度,意味着形成直角,方向完全不相似;如果夹角为180度,意味着方向正好相反。因此,我们可以通过夹角的大小,来判断向量的相似程度。夹角越小,就代表越相似。
步骤:
step1:分词
step2:列出两个句子的并集
step3:计算词频向量
step4:计算余弦值

但是实际使用中文本长度可能过长,如果采用分词,复杂度较高,可以采用TF-IDF的方式找出文章若干个关键词,再进行比较。
文章的长度可能不一致,所以关键词词频率可以使用相对词频率。
四、计算模块接口部分的性能改进
性能耗时分析

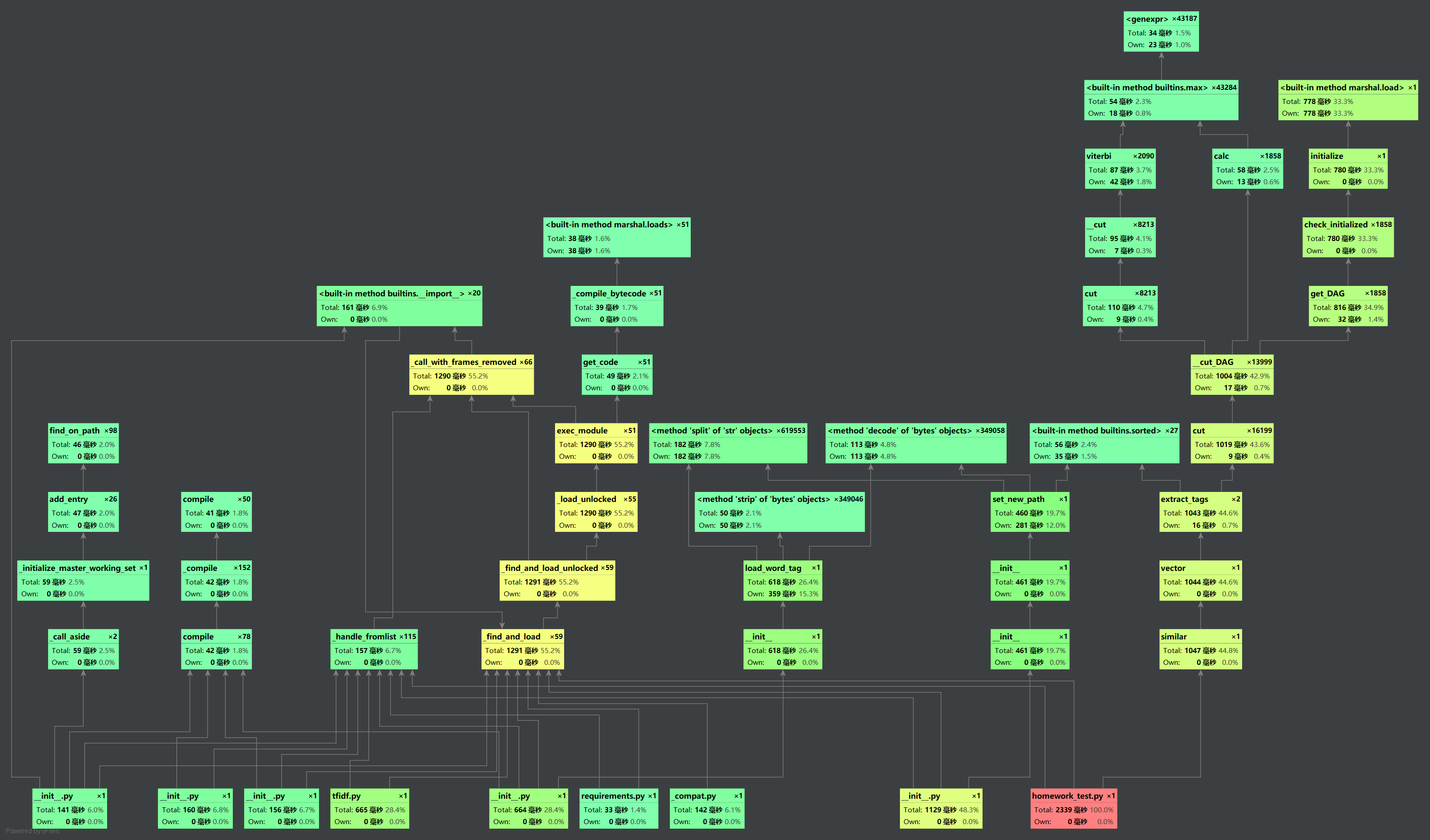
覆盖率

样例中一共给了9个例子,自己新建了一个new.txt,里面全写的是英文字母。

jieba.analyse.extract_tags() 可以使用默认的TF-IDF模型对文档进行分析。
参数withWeight设置为True时可以显示词的权重,topK设置显示的词的个数。
class Similarity(): #初始化,给定要比对的文本和关键字
def __init__(self, target1, target2, topK=10):
self.target1 = target1
self.target2 = target2
self.topK = topK
def vector(self):
self.vdict1 = {} #topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
self.vdict2 = {} #withWeight 为是否一并返回关键词权重值,默认值为 False
top_keywords1 = jieba.analyse.extract_tags(self.target1, topK=self.topK, withWeight=True)#self.target 为代提取的文本
top_keywords2 = jieba.analyse.extract_tags(self.target2, topK=self.topK, withWeight=True)
for k, v in top_keywords1:
self.vdict1[k] = v
for k, v in top_keywords2:
self.vdict2[k] = v
def mapminmax(vdict):
#计算相对词频
_min = min(vdict.values())
_max = max(vdict.values())
_mid = _max - _min
# print _min, _max, _mid
for key in vdict:
vdict[key] = (vdict[key] - _min) / _mid #计算相对词频
return vdict
def similar(self): #余弦算法
self.vector()
self.mix()
sum = 0
for key in self.vdict1:
sum += self.vdict1[key] * self.vdict2[key] #计算分子
A = sqrt(reduce(lambda x, y: x + y, map(lambda x: x * x, self.vdict1.values())))
B = sqrt(reduce(lambda x, y: x + y, map(lambda x: x * x, self.vdict2.values())))
return sum / (A * B)
五、计算模块部分异常处理说明

六、总结
本次作业,让我意识到自己有很多不足,也在完成本次作业的过程中收获了不少,由于时间问题,感觉自己还有许多地方不懂,希望能够好好利用接下来的时间进行自主学习以及向身边优秀的同学学习,提高自己的编程能力。希望之后的作业自己能够拿出更多的时间来来完成,并且不断学习、不断进步。