$ 0 写在前面
在DDL一次次的推动下,历经三个周期的更迭,一个月的时光匆匆而过。谨撰此博文,以记录这一段见证成长的心路历程。
$ 0-0 JAVA“一天速成”
没有修习过传说中的“OO先导课”,在学期开始之前也从未接触过JAVA编程,真正的从零开始学JAVA。有了先前课程的基础,经过了一年的积累,在短时间内学会使用一门语言并不困难,在加上JAVA天然的与C语言之间的某种相似性,也使得“JAVA一天速成”并非遥不可及。
$ 0-1 “过程式”VS“对象式”
但值得注意的是,JAVA作为一种面向对象的开发语言,其本质上与C语言有着重大差异,只不过在第一次作业的时候,由于对JAVA的一无所知,就也只能按照头脑中既定的那种根深蒂固的过程式程序模式来编写。而作业要求“注意体会过程式和面向对象式程序的区别”也成为了一直困扰我的难题。
$ 0-2 棘手的需求
在第二次作业中,由于有了第一次作业和实验课的经验,我也阅读了更多身边同学所编写的代码,使我对面向对象的概念有了进一步的了解。同时由于作业项目引入了一个具体的应用背景,也使我对“类”的定义和使用更加得心应手。不过新的难点总是会不断涌现,这一次我所面临的新难题便是—指导书。可以说指导书就是一种用户需求,相比于在未来工作中可能遇到的需求而言,指导书可以说是将规定做到尽量细致了。但是大量的内容同时涌现,个别定义的模糊不清,成为了对我的新的考验。
$ 0-3 惨痛的教训
紧接着第三个工作周期,也就是刚刚结束的那项任务对我而言是一次惨痛的教训。由于第三次作业的内容继承自上次作业,同时对上次作业的内容有了更进一步的需求,这就考验了我们所设计的代码的可扩展性。另外捎带请求、同质请求独特的判定方式相互交织,也为调度方法的设计与实现增添了不小的难度。能否做好与上次作业的衔接、能否架构好顶层设计便成为了这次作业的主题。
$ 1 第一次作业
$ 1-0 从I/O开始
万事开头难,一个程序往往是要以一组输入作为起始,由于一上手还不了解“对象”的概念与使用,java的一组用于控制输入的语句在我看来显得“玄妙异常”。
import java.util.Scanner; Scanner input = new Scanner(System.in); if(input.hasNextLine()) { text = input.nextLine(); } input.close();
这里的input为实例化的一个java内置Scanner类里的对象,System.in作为Scanner构造方法的参数被传递进去,hasNextLine()和nextLine()都是Scanner类里的方法。最后的close()方法的调用也是编译器的一种建议,不写该方法会收到一条警告信息。
注意在读入一行前,一定要先判断是否存在下一行,从而避免直接落入Exception的处理之中。同时也尽量在读入阶段末尾调用close()方法,以免出现未知错误。
下面列出一些常用的Scanner类中的方法,便于日后使用时查阅。
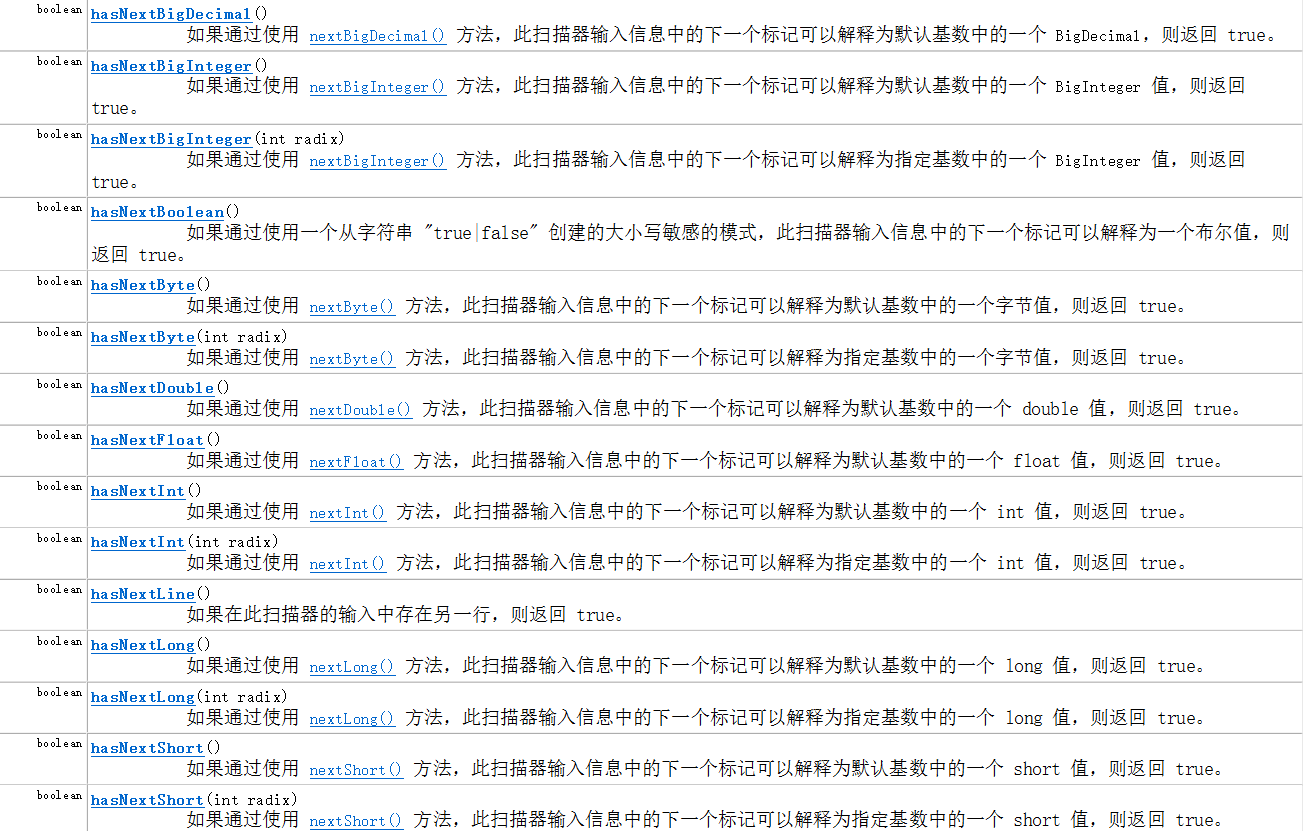

(图片来源于网络资料)
$ 1-1 正则!正则!
在上一学期的《计算机组成原理》Project 0中我们了解到,正则表达式是一种有效的字符串匹配机制,其本质就是基于FSM实现。因而这里我也尝试了一下在java中用简洁的正则式来取代原来书写FSM所采用的繁琐的状态转移。
正则式的表达虽然简洁,但随之而来的问题也着实为我带来不小的困扰—爆栈。
由于本次作业的输入是有一定规模的,总共输入项数的上限多达50*20。对于这种规模的输入,如果不加以拆分,直接进行整体正则匹配将无法通过压力测试(实验证实)。
由此我便得到启示:在待匹配的字符串规模较大时,可以采用以下语句,来实现对字符串的拆分:
// while(m.find()) // m.group(0)
其中find()方法用于判定找到了带匹配的字符串,group()方法则可以用于截取出匹配到的字符串。
至此,正则式的两大用途都很清晰了:一是可以用于格式检查,二是用于从原字符串中截取符合规格的标准段。那么如何综合应用这两种功能,去解决对大规模输入的匹配呢?
我在第一次作业中就应用了分段匹配的办法,每次只匹配一个多项式的长度,并将匹配好的部分存入一个String中,逐次累加,最后比对存储的串是否和原串相同,即可完成匹配。
还有几点值得说明的是,在正则式中尽量应用^$来标记待匹配字符串的首尾,用非捕获性的(?:)来代替捕获性的()匹配。这两处细节可以优化我们的正则处理过程。
$ 1-2 防御与攻击
第一次在互测阶段被发现了一处bug,这处bug出现的原因在于我对“-0”以及“前导0”的理解不够全面。仅考虑了形如“-0”的情况,却忽略了“-0”也可能存在前导零。这就在被测试阶段,给测试者留下了可攻击的漏洞。
在进行测试时,我所遵循的逻辑也是由表及里的策略:即通读指导书、略读I/O、检查异常处理、深入理解代码逻辑几个步骤。
拿到的第一份代码的漏洞出现在缺乏try-catch(关于try-catch的重要性将在下节叙述)。在这个基础上,在合理范围内使程序crash的几率就大大增加。紧接着我发现,作者运用了大量的定长数组代替长度可变的数组,而且在Input阶段的正则匹配也采用了十分开放的贪婪匹配策略,这就为程序引入了潜在威胁。
因此,通过构造一组恰好数组越界的小型数据输入用例便crash掉了这个程序。
$ 1-3 try everything && catch me if I fall
任何情况下程序都不应crash。
这一要求一点都不过分,对程序鲁棒性的追求没有极限。让自己的程序在高强度的测试下保持稳定性,是每位设计者必须要致力于的目标。
因此,永远不要忘记try和catch!
此外,结合后续作业中的经验,try语句块不仅应出现在最顶层,在输入阶段、类型转换阶段、访问定长数组阶段等“危险”时期,最好都应用try-catch结构,而且为了忽略掉异常情况使程序继续正常运转下去,在内部的try-catch结构可以不用exit(0)。
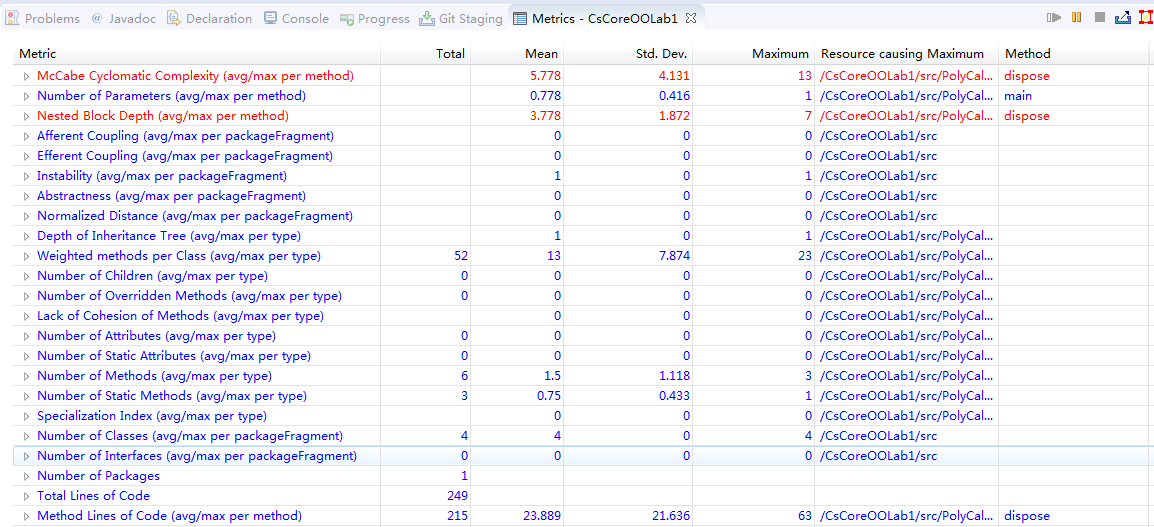
$ 1-4 代码度量分析
$ 2 第二、第三次作业
$ 2-0 “面向对象”的进一步理解
这一次作业由于有了具体的应用场景,在加上设计建议,让我有机会进一步理解了“面向对象”的概念。
为了便于我自己的理解,我认为我们在JAVA中定义的class视作和C中定义的struct类似,都是一类封装好的属性的集合,但class在struct的基础上还能在其中定义方法。尽管这种理解并不准确,但确实在我编程的过程中给我了一些提示。
“对象”则是我们实例化的一个具体的编程实体,实例一个对象的好处是其中的数据易于维护。这就和我之前在编程时喜欢用的全局变量截然不同,对象内部的数据易于保护,对外界不可直接访问与修改,这就大大降低了由数据共享所引入的风险。
$ 2-1 多变的需求与应对策略
第二、第三次的指导书内容庞大,issue的讨论区也有很大的信息量。如何整理出其中的逻辑,从何处下手是工作的重点。和测试同学交流过后,我也很认同他所提到的前期设计。而我也不得不承认,由于设计工作不够充分,导致了很多的细节考虑不够周到,也为我后来的debug工作造成了重大的影响。
一种值得借鉴的好习惯是,把指导书和issue中提及的关键点提取出来,记录到文档中,便于设计时查看;采取显式的设计模式,将设计流程完整的呈现出来,对自己的设计也是一个提示作用;测试驱动开发,测试点的设计要用心,多考虑边界情况,不断校正模型。
$ 2-2 新一轮的防御与攻击
在这一个周期的攻防阶段中,由于最后的提交阶段时间紧迫,没有来得及提交readme、还有很多细节的地方,比如Interface/toString()、包括一个已知的尚未来得及调试的bug。
在同质请求和捎带请求混杂在一起的情况出现时,边界条件的判断就显得尤为重要,尤其是同质判断和可捎带判断边界差了1秒的开关门时间。所以边界时间的+-1、是否取等号都需要纳入考虑的范畴。
由于设计工作的欠缺,后期陷入了调试的深渊。最终也因为一个边界取值的原因,被测试人员发现了一处bug。
同时测试中也发现了一些重要的bug,在类型转换过程中,溢出了数据类型规定的范围,导致程序异常终止。这也就是我在$ 1-3 中提到的,try-catch结构内置的意义,同时也要为输入的正则匹配加以限制,尽量避免贪婪匹配的使用。
$ 2-3 代码度量分析 && 类图
$ 2-3-0 第二次作业
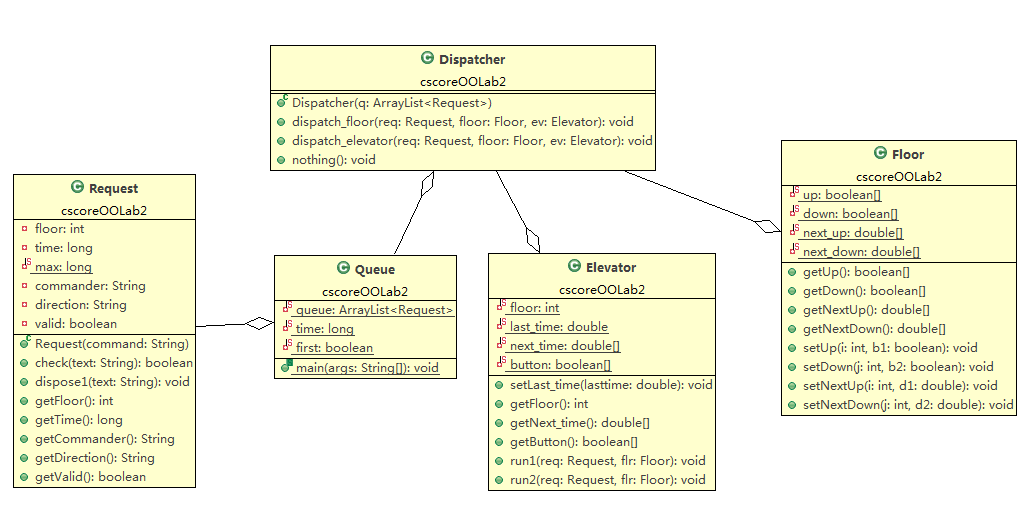
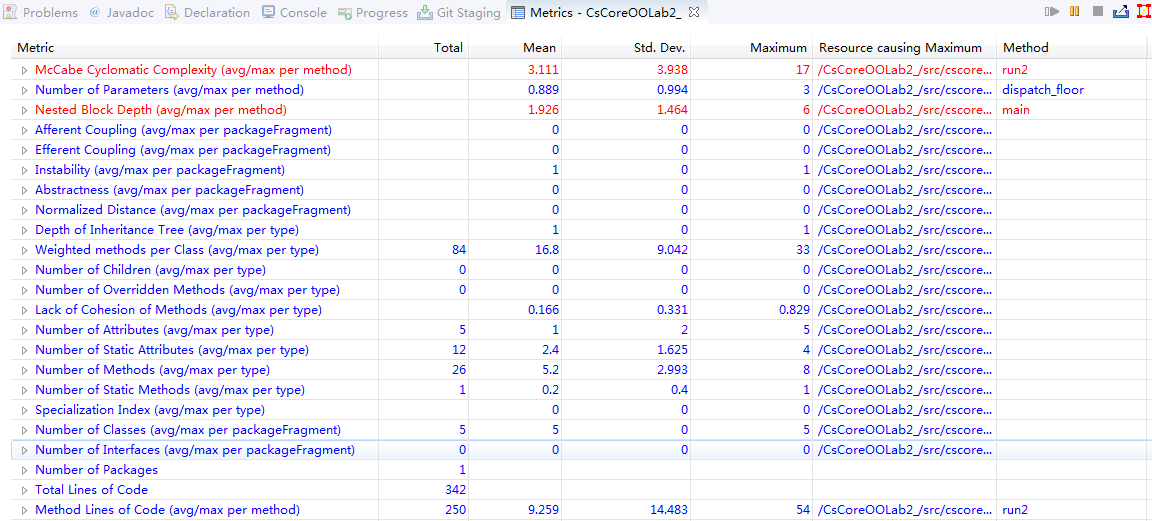
$ 2-3-1 第三次作业
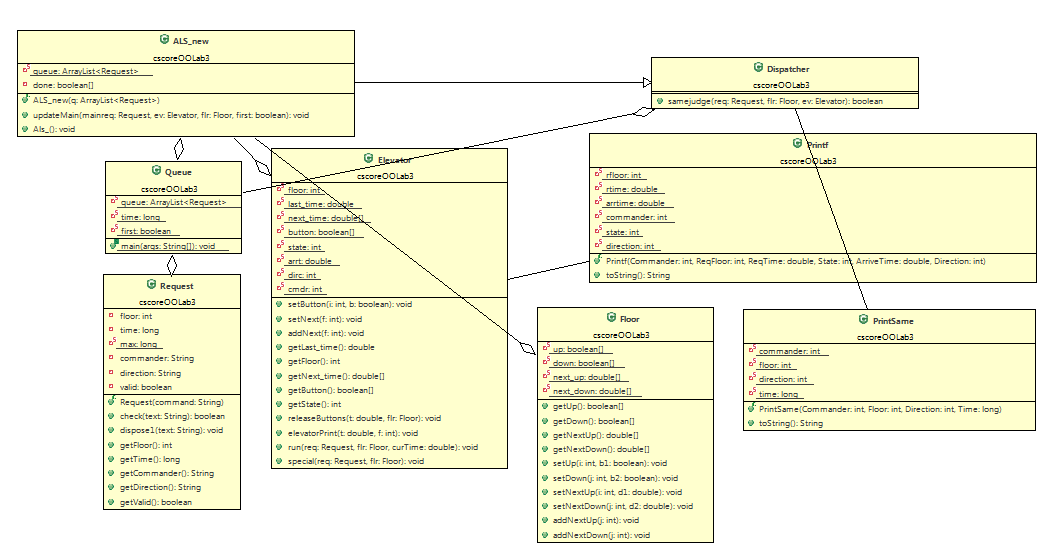

综合$ 1-4和本节的结果分析,从度量分析结果来看,代码的逻辑复杂度、嵌套块深度等指标在三次作业中均超出了标准值。内聚度不高、耦合度超标也是在设计中凸显的矛盾。在代码逻辑的部分、方法的抽象度不高,很多功能相似或相近的方法代码段出现大量重复。在第三次作业中这种矛盾更为明显:Complexity 均值高达6.3;Parameters per method 均值达1.3;Block depth 也超过标准值。这些显然都是由于代码中大量的循环嵌套、条件分支的交互错杂造成的,这也为我的调试带来了难以估量的灾难性后果。
工程化方法的指导思想在于“高内聚、低耦合”,但要做到这一点显然需要前期大量的准备工作,顶层的架构、显式的设计过程、测试驱动的开发,都将有效帮助我在下次的设计中进一步优化。
$ 3 关于Object Oriented 的一些其他感想
$ 3-0 关于申诉
第一次OO作业的申诉经历,足以证明:我航学子的学品与素养,托得住,信得过。即使在OO的高压双盲互测体制下。依然可以保持人与人之间最单纯的信任,真心希望能与诸位同行一道,摒弃流言蜚语,摒弃偏见,以此课程平台为契机,增进交流,建立信任。学在其中,乐在其中。共同收获技术上的不断提升!致力于正能量的传递,我们一起!
$ 3-1 关于无效作业
在OO Project2 中,我遗憾的看到了身边有很多朋友被申报了无效作业。而产生无效的原因也很令人诧异。看到查找别人个人信息的方式也不禁令我大跌眼镜。故意找别人的个人信息申无效,难道这是课程组设计的本意么?交流技术,看代码,看文档就好。一般情况下难道会有人特意点开pdf属性看作者?或是用强行打开.project文件?就为了找个人信息申无效?为了多得分方法有很多,最好的方法还是做好自己的任务,毕竟每个人都很努力,还是希望能够彼此多尊重对方的劳动成果吧。
$ 4 特别致谢
“没有人是一座孤岛”。说实话,前三次作业的过程充满了艰辛,一路走来,必须要感谢在这一过程中给我最大帮助的朋友们。他们是:
中国好室友LCJ,对于我解决各种琐碎的疑难总是回应以最大的热情,尤其是第三次作业ddl前极限操作时帮我赶制readme和interface,让我至今回想起来都很感动。
RHX哥、ZZH哥,给我在解决问题上提供了大量宝贵的思路。NYZ、GZP在具体的技术实现的细节上给了我大量的指导。ZKN、LHY、LQY为我提供的大量测试用例,帮助我有效的检验修正模型。JSH搭建了公共测试平台并维护,造福全系同胞。
当然更要感谢在每次互测阶段,秉持公平公正、认真互测的测试者,和坚持积极沟通交流并给我充分理解的被测试者们,是你们让我看到的跟多的是这一机制的积极一面。
希望在紧接着即将到来的挑战中,总结经验、继续努力,不断提高技术能力。也希望能尽我个人之所能,为这一课程做出一份贡献!