卷积核学到了什么
如果想知道下图中第1个卷积层中的每个卷积核的功能,因为它参数比较少而且其输入是原图片,所以我们直接结合原图片观察卷积核的参数就可以知道该卷积核的功能。

如上图所示,CNN中第2个卷积层的输入不是直观的图片而且其卷积核的感受野比第1个卷积层中卷积核的感受野更大,因此我们无法通过观察卷积核参数了解卷积核学习到了什么。
上图中CNN第2个卷积层中有50个卷积核,每个卷积核的输出都是一个大小为11×11的矩阵。
现在定义函数(a^k=sum_{i=1}^{11}sum_{j=1}^{11}a^k_{ij})来衡量某卷积核被“激活”的程度,即将卷积核所输出矩阵的元素之和作为其被“激活”程度,被“激活”程度指CNN输入与该卷积核有多匹配。
接下来,通过梯度下降求得(x^*=arg max_x a^k),即找到最能“激活”卷积核的输入图片(x^*),然后将其可视化希求反映该卷积核学习到的内容。
上图左下角可视化了最能“激活”第2个卷积层中某12个卷积核的12张图片,可以看出各卷积核适用于检测小的纹理(这个案例是数字识别)。
全连接层学到了什么
如下图所示,我们同样可以用梯度下降找到最能“激活”全连接层中某个神经元的输入,将该输入其可视化,以此观察全连接层学习到了什么。和卷积核不同,卷积核学习到的是较小的pattern,全连接层中的神经元学习到的是尺寸较大的pattern。

输出层学到了什么
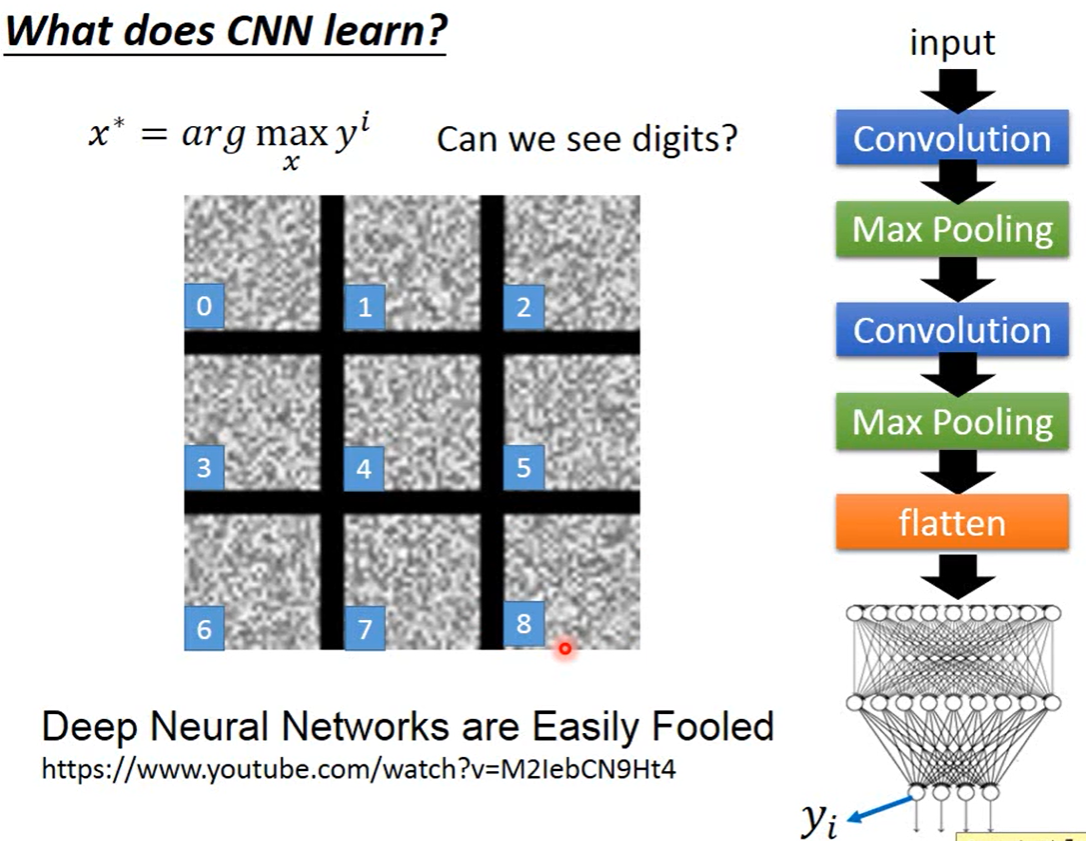
如下图所示,我们同样可以用梯度下降找到最能“激活”输出层中某个神经元的输入,将该输入其可视化,以此观察输出层学习到了什么。在想象中这些输入应该是对应的数字,然而并不是(有人说眯着眼马马虎虎可以从中看到数字)。
在其它的案例中也有这样的情况,即机器学习到的内容和人类所理解的内容是不同的。这个视频里讲了相关例子。
但这个方法(通过“激活”卷积核反映学习到的内容)确实是有效的,那如何改进呢?我们可以对输入做一些限制(constraint)。
在该例中数字图片中底色是黑色,前景色(数字)是白色。
如下图所示,简单考虑的话,我们可以添加图片中大部分像素是黑色的限制(值接近0,也就是L1正则化),然后将求得的输入可视化。

当然,我们可以用更好的方法(比如说更好的限制)找到人类更容易理解的输入……这也是Deep Dream的精神。
神经网络可视化

Github(github.com):@chouxianyu
Github Pages(github.io):@臭咸鱼
知乎(zhihu.com):@臭咸鱼
博客园(cnblogs.com):@臭咸鱼
B站(bilibili.com):@绝版臭咸鱼
微信公众号:@臭咸鱼
转载请注明出处,欢迎讨论和交流!