2019-04-09
关键词: 消息队列、为什么使用消息队列、消息队列的好处、消息队列的意义、Kafka是什么
本篇文章系本人就当前所掌握的知识关于 消息队列 与 kafka 知识点的一些简要介绍,不保证文章所述内容的绝对、完全正确性。
1、消息队列于消息系统的意义
笔者这里所提到的 消息系统 可不是那些社交网站上用于站内交流的消息系统。
在互联网中,但凡涉及到消息传递的过程,都可以称之为是一个消息系统,规模或大或小而已。举个例子:12306 购票过程就包含了消息系统,客户的查询、下单等请求都被封装成消息传递到服务器上并被处理。还有淘宝京东的购物流程,学校图书馆的借阅系统等等都涉及到消息系统。消息系统在互联网中的应用是非常广泛的。
在一个消息系统中,服务器端即 消息处理端 是至关重要的。且不管你配备什么配置的硬件,它的处理能力始终是有上限的。如果单位时间内消息产生的数量超过了服务器所能处理的数量,那我们的系统就肯定要出问题了。当然我们可以通过多部署几台服务器以分布式的方式来分摊消息压力来解决,但成本是个大问题啊。消息爆发的情况总是少数,你看淘宝一年就搞一次购物节,12306 一年也就那么几次抢票高峰期。因此,为我们的消息系统引入 消息队列 就是一个最佳选择了。
什么是消息队列呢?
我们可以简单地把它理解成是消息系统中 介于 客户端与服务端之间的一个 消息中转站 。消息队列在消息系统中主要有以下 3 个作用
1. 应用解耦
2. 流量削峰
3. 异步消息
应用解耦
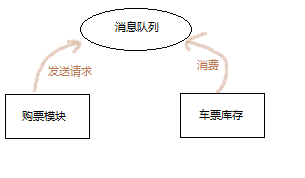
相信你一定还记得软件设计的原则就是:高内聚,低耦合。 在没有引入消息队列模块时,应用模块之间通常都是直接进行消息传递过程的。我们以 12306 购票过程为例,用户购票下单的过程与车票库存直接相关。当用户下单购票时,会同时调用车票库存模块,使车票余量减少。这样就使得下单模块与车票库存模块存在强耦合关系。当车票库存模块服务不稳定时,例如,刚好要下单时库存模块就暂停服务了,这样一来就可能直接引发下单失败等一系列不良体验。而若加入了消息队列,下单请求将会直接发送到消息队列中暂存,待到车票库存模块恢复工作后再主动去消费下单请求。
流量削峰
这个就是前面提到的 “消息爆发” 的情况了,俗称 “流量爆发” 。这种情况常见于电商网站的秒杀活动里。在引入了消息队列以后,所有来自客户端的请求都被积压在消息队列里,任凭你产生了多大的瞬时流量,我服务器就按照我所能处理的速率按顺序来逐条消费这些请求。这样就可以保证我们的服务器在任何情况下都能正常服务,只是将这种流量爆增的代价转架到客户端头上使他们多排排队而已。
异步消息
这种情况主要是应用于请求需要等待反馈结果情况。当有一条请求被发起时,各响应模块对请求的处理也是需要时间的,若所依赖的模块再多一点,响应时延可能就会很长了。那我们知道:用户都是急躁的! 所以我们可以通过引入消息队列的方式来异步处理请求消息。一种常用的方式是,用户通过网页下达了一条指令,当后台接收到这条指令并将它压到消息队列时就立即返回 “成功” 的提示,随后再等待各模块去执行这一指令。这种方式可以大大提升用户体验。
消息队列真这么优秀吗?
前面介绍了这么多消息队列的好处,并且现在的互联网消息队列的使用也确实是非常广泛。但消息队列也是有缺点的,它最大的一个缺点就是会增加 “系统复杂度” 。对于一个系统来讲,模块越少越简单,运行起来出现故障的几率就越小,换句话说就是越容易稳定。而我们引入消息队列这一行为,至少是给我们的系统增加了一个模块,这必然会提升系统复杂度。另一个缺点是你不可避免要面对消息队列模块故障的问题。当消息队列模块故障了,你的整个消息系统也就瘫痪了。不过总体而言,引入消息队列还是弊大于利的。
2、Kafka 简介
消息队列框架还是不少的,不同的消息队列框架有各自不同的适用场景。在大数据领域里要数 Kafka 比较热门。
2.1、Kafka 是什么
Kafka 是由 LinkedIn 团队开发的一款 发布/订阅 模型的分布式流处理平台 ,主要用于对数据流的存储与处理。于 2012 年成为 apache 顶级项目之一。Kafka 既然被当作消息队列来使用,那么它的核心功能自然就是 高性能的消息发送与消费 了。同时 Kafka 还是一个依赖于 Zookeeper 的分布式消息队列。
2.2、什么是发布/订阅模型
发布/订阅模型可以简单理解为就是一种 “一对多” 的消息推送系统。消息的发送者不会直接将消息发给消息接收者。而是消息发送者首先以某种方式将消息分类,由消息接收者主动订阅某种分类下的消息。当这一操作完成后,有新消息到来时,消息发送者才会将新消息推送给所有订阅了该类型消息的接收者。
2.3、Kafka 的架构
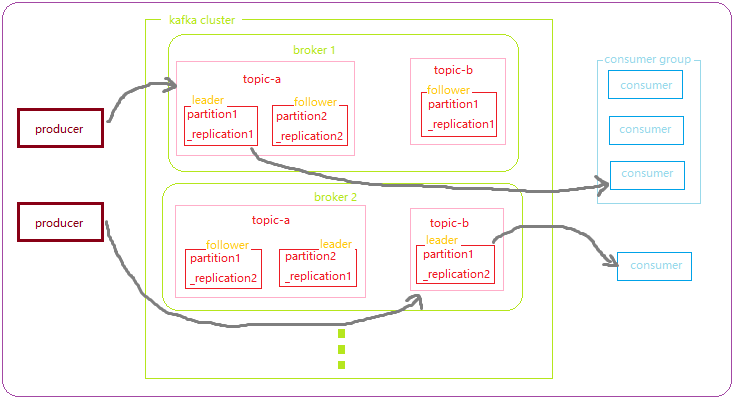
1、
从消息流向角度来看,Kafka 中共有 3 个角色
1. producer
2. topic
3. consumer
producer
即消息的生产者。
topic
消息的分类。在 Kafka 中,不同类型的消息以 topic 划分。例如在某电商网站中,下单消息被划为一个 topic ,取消订单被划分为另一个 topic 等等。在某种程度上也可以将 topic 理解为是一个 队列 。所有的消息都是以先进先出的形式被保存在一个 topic 中的。
consumer
即消息的消费者。
2、
从消息管理的角度来看,可以分为 3 个角色
1. topic
2. partition
3. replication
topic
上面已经有解释。
partition
如果一个 topic 规模过大,则可以将它拆分成多个 partition 以存储在不同的节点上。可以理解为 topic 是由 1 ~ n 个 partition 组成的。
replication
replication 即是 partition 的副本。它是为了提高 topic 的可用性而设立的一个角色。其意义与 HDFS 中的副本是一样的。
值得一提的是,对于同一个 topic 中的多个 partition 副本中,会有其中一个 partition 副本是 leader 副本,其余的是 follower 副本。消费者只与 leader 副本交互。
3、
从集群的角度看,可以分成 2 种角色
1. broker
2. cluster
broker
通常一台 kafka 服务器就是一个 broker ,而一个 broker 里又可以包含多个 topic 。
cluster
多台 broker 构成一个 Kafka 集群。
4、
从消费者的角度看,可以分为 2 类
1. consumer
2. consumer group
consumer
消费者。
consumer group
消费者组。多个消费者可以划分到一个消费者组里。若某个消费者组订阅了某个 topic ,则有新消息到来时,只会发送给这个消费者组中的一个消费者而不是发给所有消费者。
5、
综上所述,可以作出如下图所示的 Kafka 架构图
kafka 架构简图
2019-04-09