任务:通过driver的getPageSource()获取网页的源码内容,在把网页中图片链接地址和跳转的url地址进行过滤,在get每个请求,来判断是否是死链
如图:
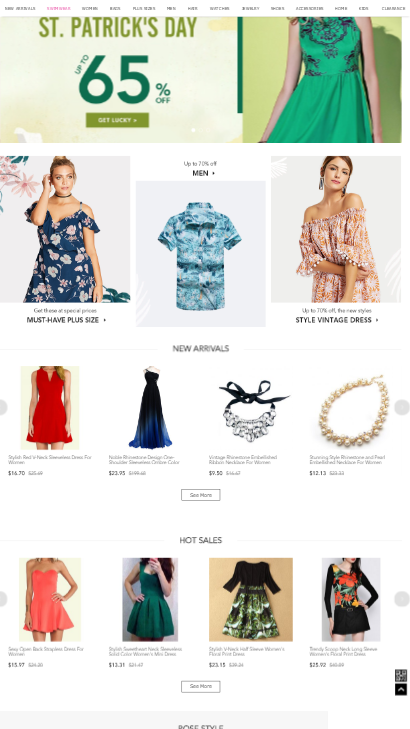
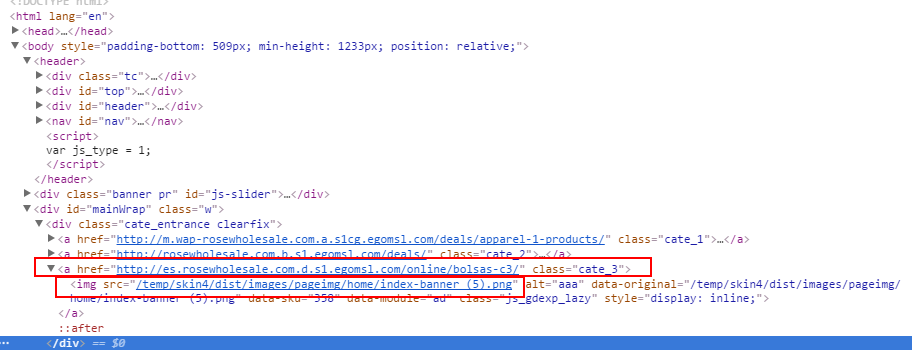
获取网页源码中所有的href,以及img src后的链接
代码实现:
调用代码实现,正则表达式
public void home_page(){ op.loopGet(home, 40, 3, 60); String source=driver.getPageSource();//获取网页源码 // System.out.println(source); String imageSrc="img\s*src="?(http:"?(.*?)("|>|\s+))";//图片的正则表达式 //要注意https的数据是否能loading出来,要注意查看 String jumpAdders="a\s*href="?(http:"?(.*?)("|>|\s+))";//获取html的地址 Regular(imageSrc,source); Regular(jumpAdders,source); }
Regular方法,使用正则表达式
public void Regular(String expressions, String sourceFile) { Map<String, String> result = new HashMap<String, String>(); Pattern p = Pattern.compile(expressions); Matcher m = p.matcher(sourceFile); while (m.find()) { //System.out.println(m.group()); //需要做对比是否需要全部去出数据更快, String regularURL = m.group().replace("img src=", "").replace("a href=", ""); regularURL=regularURL.substring(1,regularURL.length()-1);//会多引号 result = Pub.get(regularURL); if (!"200".equals(result.get("Code"))) { Log.logError("请求失败,请检查图片或者是网页链接否正常显示,请求地址为:"+regularURL); } } System.out.println("**********************"); }
Pub.get方法,发送get请求
public static Map<String, String> get(String url) { int defaultConnectTimeOut = 30000; // 默认连接超时,毫秒 int defaultReadTimeOut = 30000; // 默认读取超时,毫秒 Map<String, String> result = new HashMap<String, String>(); BufferedReader in = null; try { Log.logInfo("通过java请求访问:["+url+"]"); // 打开和URL之间的连接 URLConnection connection = new URL(url).openConnection(); // 此处的URLConnection对象实际上是根据URL的请求协议(此处是http)生成的URLConnection类的子类HttpURLConnection // 故此处最好将其转化为HttpURLConnection类型的对象,以便用到HttpURLConnection更多的API. HttpURLConnection httpURLConnection = (HttpURLConnection) connection; // 设置通用的请求属性 httpURLConnection.setRequestProperty("accept", "*/*"); httpURLConnection.setRequestProperty("connection", "Keep-Alive"); httpURLConnection.setRequestProperty("user-agent", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)"); httpURLConnection.setConnectTimeout(defaultConnectTimeOut); httpURLConnection.setReadTimeout(defaultReadTimeOut); if (staging != null) { httpURLConnection.setRequestProperty("Cookie", staging.toString()); } if (ORIGINDC != null) { httpURLConnection.setRequestProperty("Cookie", ORIGINDC.toString()); ORIGINDC = null; } // // Fidder监听请求 // if ((!proxyHost.equals("") && !proxyPort.equals(""))) { // System.setProperty("http.proxyHost", proxyHost); // System.setProperty("http.proxyPort", proxyPort); // } // 建立连接 httpURLConnection.connect(); result = getResponse(httpURLConnection, in, result); } catch (Exception requestException) { System.err.println("发送GET请求出现异常!" + requestException); // requestException.printStackTrace(); } // 关闭输入流 finally { try { if (in != null) { in.close(); } } catch (Exception closeException) { closeException.printStackTrace(); } } return result; }
结果展示:
图片正常展示

访问的链接地址,并查到某一处请求失效:
