# 训练模型 # 损失函数:categorical_crossentropy,优化器:adam ,用准确率accuracy衡量模型 model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) # 划分20%作为验证数据,每次训练300个数据,训练迭代300轮 train_history = model.fit(x=X_train, y=y_train, validation_split=0.2, batch_size=300, epochs=300, verbose=2)
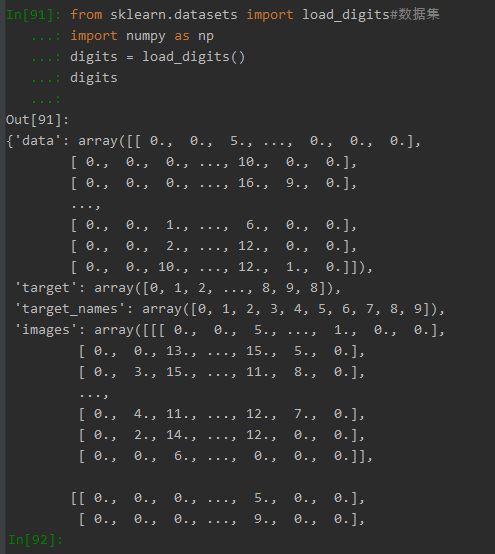
1.手写数字数据集
- from sklearn.datasets import load_digits
- digits = load_digits()
(1)获取的数据集:
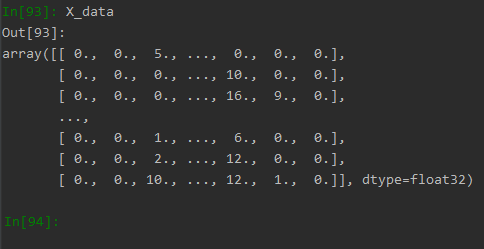
(2)提取的x值:
2.图片数据预处理
- x:归一化MinMaxScaler()
- y:独热编码OneHotEncoder()或to_categorical
- 训练集测试集划分
- 张量结构
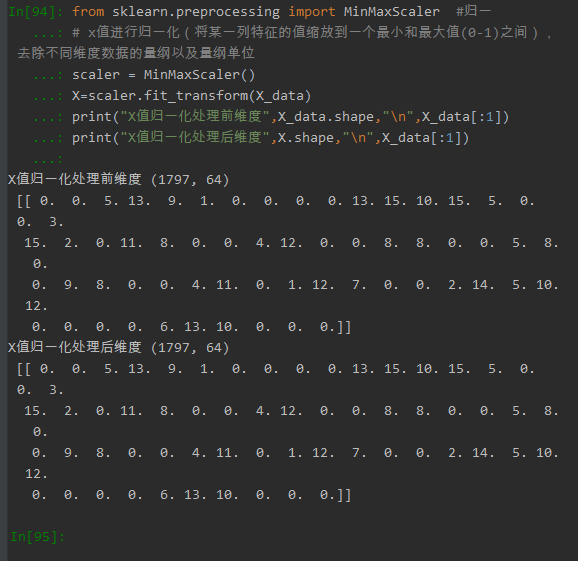
(1)x值归一化:
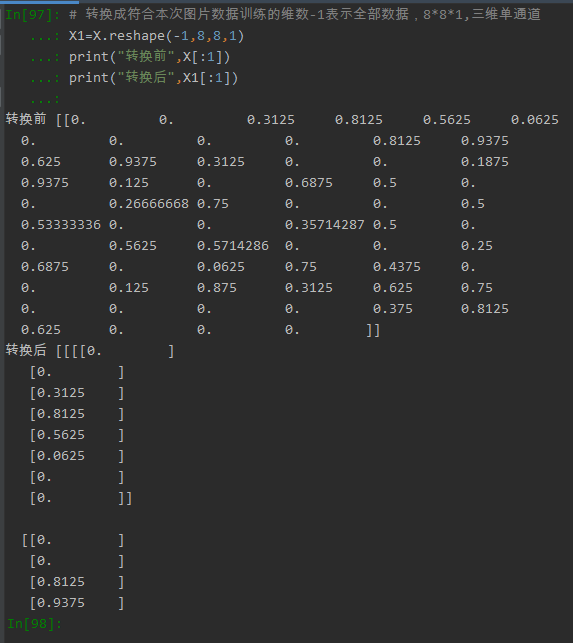
(2)将x转换为图片维数
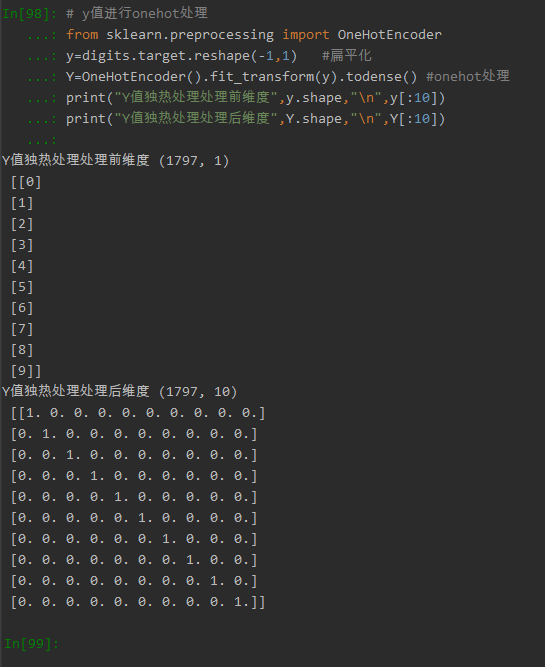
(3)对y值进行onehot处理
(4)模型切割
from sklearn.model_selection import train_test_split #模型切割 # 划分训练集与测试集 X_train, X_test, y_train, y_test = train_test_split(X1, Y, test_size=0.2, random_state=0, stratify=Y)
3.设计卷积神经网络结构
- 绘制模型结构图,并说明设计依据。
模型结构图:

模型选择:
(1)此次才用经典模型中的vggnet模型,图片结构为(8,8,1)所以可以设置三层池化,通过反复堆叠3*3的小型卷积核和2*2的最大池化层完成,整个网络有4层卷积,每一层的卷积核数量依次为:16,32,64128。
(2)都使用了同样大小的卷积核尺寸(3*3)和最大池化尺寸(2*2),卷积过程使用"SAME"模式,所以不改变feature map的分辨率。
(3)网络通过2*2的池化核以及stride=1的步长,每一次可以分辨率降低到原来的1/4,即长宽变为原来的1/2。
from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPool2D # 4、建立堆积模型 model = Sequential() ks = (3,3) # 定义一个三行三列的卷积核 input_shape = X_train.shape[1:] # 获取图片的维数 # 第一层卷积,卷积核个数为16,卷积核大小3*3,移动步长默认为1,模式为same模式(卷积前后尺寸 一样) # 第一层输入数据时需指定数据的维度input_shape8*8*1 ,选用relu激活函数relu对于随机梯度下降的收敛有巨大的加速作用,只需要一个阈值就可以得到激活值 model.add(Conv2D(filters=16, kernel_size=ks, padding='same', input_shape=input_shape, activation='relu')) # 第一层池化层,缩小到1/4维度 model.add(MaxPool2D(pool_size=(2, 2))) # 防止过拟合,随机丢掉连接25%的连接 model.add(Dropout(0.25)) # 第二次卷积 卷积核个数为32,卷积核大小3*3,移动步长默认为1,模式为same模式 model.add(Conv2D(filters=32, kernel_size=ks, padding='same', activation='relu')) # 第二层池化 model.add(MaxPool2D(pool_size=(2, 2))) model.add(Dropout(0.25)) # 第三层卷积 model.add(Conv2D(filters=64, kernel_size=ks, padding='same', activation='relu')) # 第四层卷积压缩图片 model.add(Conv2D(filters=128, kernel_size=ks, padding='same', activation='relu')) # 第三层池化 model.add(MaxPool2D(pool_size=(2, 2))) model.add(Dropout(0.25)) # 平坦层 model.add(Flatten()) # 全连接层 model.add(Dense(128, activation='relu')) model.add(Dropout(0.25)) # 激活函数softmax model.add(Dense(10, activation='softmax')) print(model.summary())

4.模型训练
# 训练模型 # 损失函数:categorical_crossentropy,优化器:adam ,用准确率accuracy衡量模型 model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) # 划分20%作为验证数据,每次训练300个数据,训练迭代300轮 train_history = model.fit(x=X_train, y=y_train, validation_split=0.2, batch_size=300, epochs=300, verbose=2)
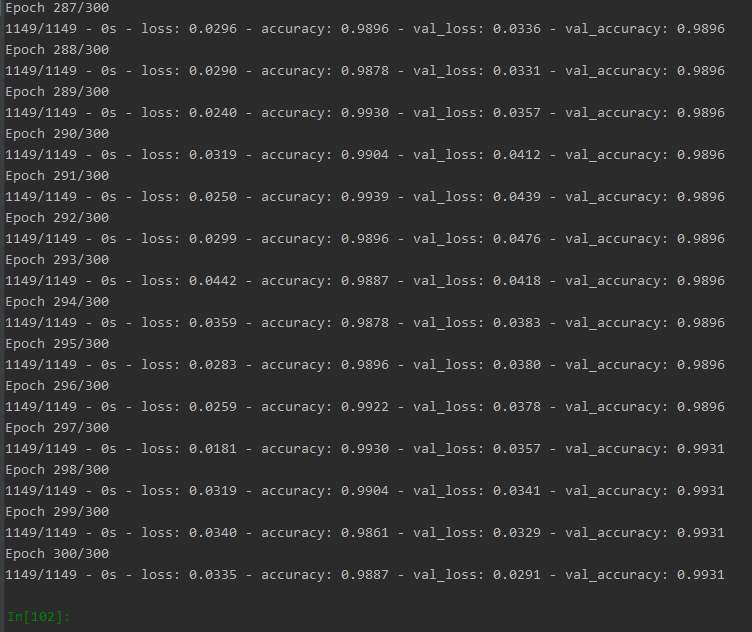
(1)训练结果:
(2)准确率随次数的变化曲线图
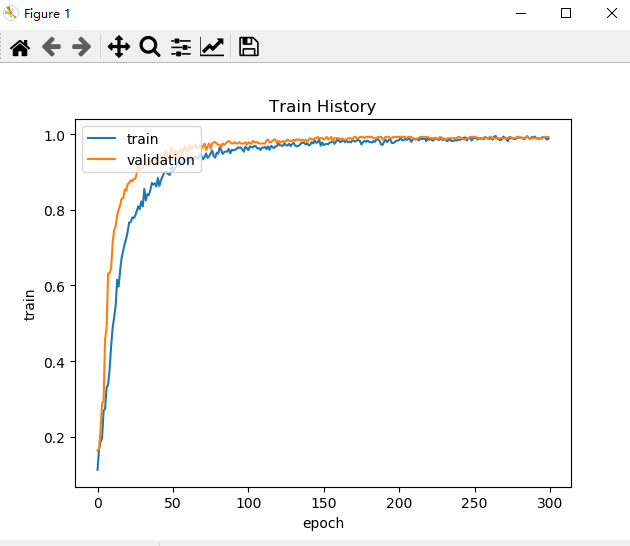
(3)损失值随次数的变化曲线

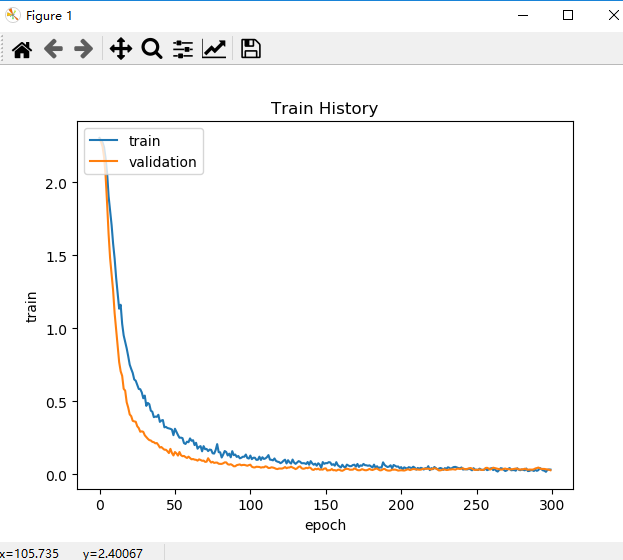
从图中可见训练迭代次数在200次左右,准确率最高,损失值最小,模型效果最好。
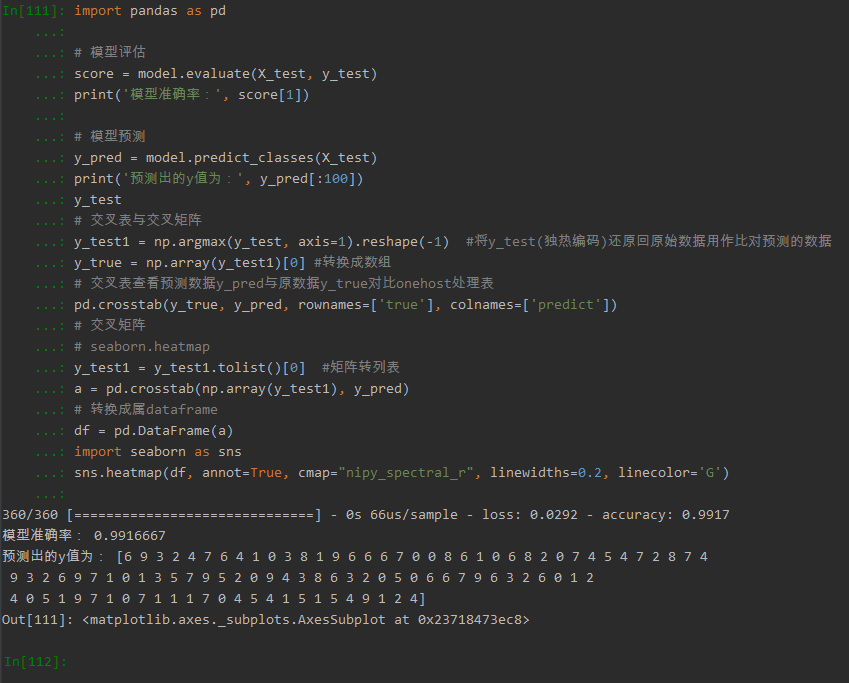
5.模型评价
- model.evaluate()
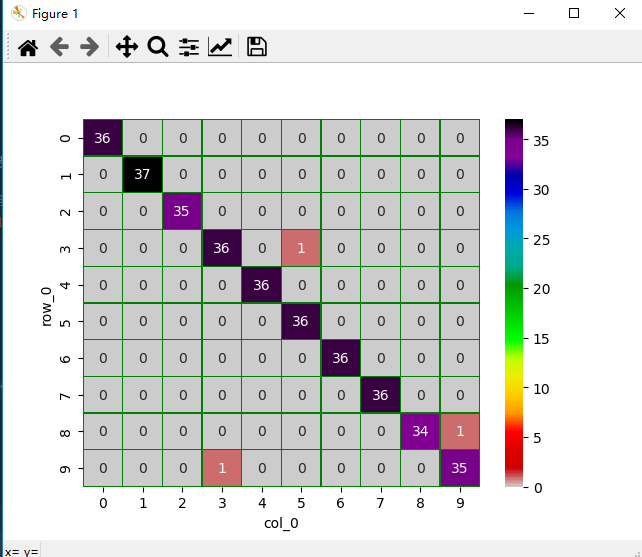
- 交叉表与交叉矩阵
- pandas.crosstab
- seaborn.heatmap