1). 扑克牌手动演练k均值聚类过程:>30张牌,3类
第一次,随机选取三个聚类中心K,7,6,随后随机抽取30张进行分类

算平均值,三堆牌平均值分别约为12,7,4,然后重新将牌再次分类,按照距离最小分类

再算平均值,三堆牌平均值分别约为12,7,3,然后重新将牌再次分类

最后算得平均值不变,分类结束
2). *自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。(加分题)
import numpy as np from sklearn.datasets import load_iris import matplotlib.pyplot as plt # 选取数据空间中的K个对象作为初始中心,每个对象代表一个聚类中心 def initcenter(data): k = int(input("请输入k值")) center = np.random.choice(data, k) # 随机从data里取三个数作为聚点中心 return center, k # 对于样本中的数据对象,根据它们与这些聚类中心的欧氏距离 def getnear(x, y): dist = np.linalg.norm(x - y) # 计算欧式距离 return dist # 按距离最近的准则将它们分到距离它们最近的聚类中心(最相似)所对应的类, 更新聚类中心:将每个类别中所有对象所对应的均值作为该类别的聚类中心 def nearest(center, k): # 循环调用算各个点的欧式距离,并将其存入dist1数组里 for i in range(n): #0-149 for j in range(k): #0-2 dist1[i, j] = getnear(data[i], center[j]) #算欧式距离 dist1[i, k] = np.argmin(dist1[i, :k]) # 取dist数组每i行的前k个中的最小值放进dist1[i,k]里 for i in range(k): index = np.where(dist1[:, k] == i) # 当i等于下标时取出到index center_new[i] = np.mean(data[index]) # 计算复制到False平均值复制到数组里做为新的聚合中心 if (np.all(center == center_new)): # 判断新聚合中心是否和旧聚合中心相同 print("聚合分类完毕,最终的聚点为", center_new) else: center = center_new # 更新聚合中心 nearest(center, k) #递归调用算法 return dist1 #函数调用 if __name__ == '__main__': iris = load_iris() # 导入鸢尾花数据 data = iris.data[:, 0] # 取出鸢尾花的花瓣数据 n = len(data) # 计算数据的长度 center, k = initcenter(data) # 获得center和k dist1 = np.zeros([n, k + 1]) # 生成n*k+1的全零矩阵,用作储存距离以及最小距离的下标 center_new = np.zeros(k) # 生成一个长度为k的数组聚合中心center_new a = nearest(center, k) #调用函数聚合 # 画散点图 plt.scatter(data, data, c=a[:, k], s=50, cmap="rainbow") plt.show()
运行结果如图

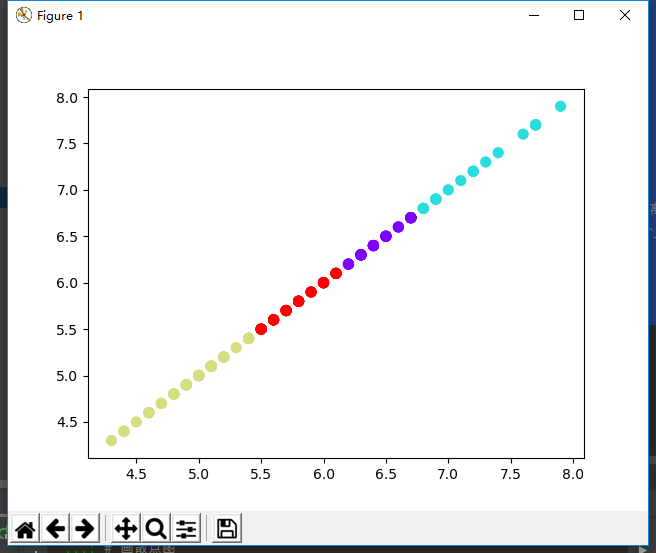
3). 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
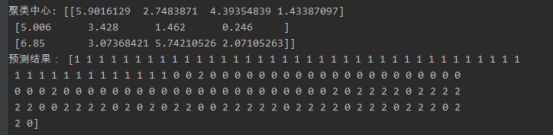
from sklearn.datasets import load_iris from sklearn.cluster import KMeans import matplotlib.pyplot as plt iris = load_iris() # 获取鸢尾花数据集 iris.keys() x = iris.data[:,0] #获取鸢尾花花瓣长度数据 x = x.reshape(-1,1) #将数据转换为一列数据 # 直接调用sklearn库实现对鸢尾花数据进行聚类分析 km_model = KMeans(n_clusters=3) # 构建模型 分成三个类 km_model.fit(x) # 训练模型 y = km_model.predict(x) # 预测模型 print("聚类中心:", km_model.cluster_centers_ ) print("预测结果:", y) # 画图 plt.scatter(x[:, 0], x[:, 0], c=y, s=50, cmap='rainbow') plt.show()
结果如下图


4). 鸢尾花完整数据做聚类并用散点图显示.
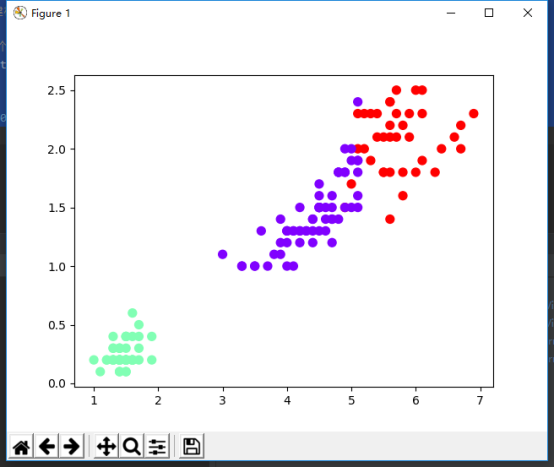
from sklearn.datasets import load_iris from sklearn.cluster import KMeans import matplotlib.pyplot as plt iris = load_iris() # 获取鸢尾花数据集 x = iris.data # 鸢尾花完整数据 # 直接调用sklearn库的KMeans实现对鸢尾花数据进行聚类分析 km_model = KMeans(n_clusters=3) # 构建模型 km_model.fit(x) # 训练模型 y = km_model.predict(x) # 预测模型中每个样本的聚类索引 print("聚类中心:", km_model.cluster_centers_ ) print("预测结果:", y) # 画图 plt.scatter(x[:, 2], x[:, 3], c=y, s=50, cmap='rainbow') #x,y,c plt.show()
结果如图所示
5).想想k均值算法中以用来做什么?
k均值算法是款无监督学习的聚类算法,我们可以用它来做机器学习,分析和预测,让机器学习通过聚类学习之后,以后出现相类似的东西,它也可以聚类分辨出来,还可以通过聚类来压缩图片。