前提说明,因为我比较菜,关于理论性的证明大部分是搬来其他大佬的,相应地方有注明。
我自己写的部分换颜色来便于区分。
邻项交换对比是求一定条件下的最优排序的思想(个人理解)。这部分最近做了一些题,就一起归纳一下。
【P1080国王游戏】
题目描述
恰逢 HH国国庆,国王邀请nn 位大臣来玩一个有奖游戏。首先,他让每个大臣在左、右手上面分别写下一个整数,国王自己也在左、右手上各写一个整数。然后,让这 nn 位大臣排成一排,国王站在队伍的最前面。排好队后,所有的大臣都会获得国王奖赏的若干金币,每位大臣获得的金币数分别是:排在该大臣前面的所有人的左手上的数的乘积除以他自己右手上的数,然后向下取整得到的结果。
国王不希望某一个大臣获得特别多的奖赏,所以他想请你帮他重新安排一下队伍的顺序,使得获得奖赏最多的大臣,所获奖赏尽可能的少。注意,国王的位置始终在队伍的最前面。
输入输出格式
输入格式:
第一行包含一个整数nn,表示大臣的人数。
第二行包含两个整数 aa和 bb,之间用一个空格隔开,分别表示国王左手和右手上的整数。
接下来 nn行,每行包含两个整数aa 和 bb,之间用一个空格隔开,分别表示每个大臣左手和右手上的整数。
输出格式:
一个整数,表示重新排列后的队伍中获奖赏最多的大臣所获得的金币数。
输入输出样例
说明
【输入输出样例说明】
按11、22、33 这样排列队伍,获得奖赏最多的大臣所获得金币数为 22;
按 11、33、22 这样排列队伍,获得奖赏最多的大臣所获得金币数为22;
按 22、11、33 这样排列队伍,获得奖赏最多的大臣所获得金币数为 22;
按22、33、11这样排列队伍,获得奖赏最多的大臣所获得金币数为99;
按 33、11、22这样排列队伍,获得奖赏最多的大臣所获得金币数为 22;
按33、22、11 这样排列队伍,获得奖赏最多的大臣所获得金币数为 99。
因此,奖赏最多的大臣最少获得 22个金币,答案输出 22。
【数据范围】
对于 20%的数据,有 1≤ n≤ 10,0 < a,b < 81≤n≤10,0<a,b<8;
对于 40%的数据,有1≤ n≤20,0 < a,b < 81≤n≤20,0<a,b<8;
对于 60%的数据,有 1≤ n≤1001≤n≤100;
对于 60%的数据,保证答案不超过 10^9109;
对于 100%的数据,有 1 ≤ n ≤1,000,0 < a,b < 100001≤n≤1,000,0<a,b<10000。
NOIP 2012 提高组 第一天 第二题
思路
这道题比起之后的三道要简单得多,可能最恶心的是高精【雾】。
以下题解来自洛谷League丶翎
题目分析:
我们对于国王身后的两个点来分析
队列可能是这样的:
| * | Left | Right |
|---|---|---|
| king: | a0 | b0 |
| p1 | a1 | b1 |
| p2 | a2 | b2 |
那么我们计算可得ans1=max(a0/b1,a0*a1/b2)
队列也有可能是这样的
| * | Left | Right |
|---|---|---|
| king: | a0 | b0 |
| p2 | a2 | b2 |
| p1 | a1 | b1 |
那么我们计算可得ans2=max(a0/b2,a0*a2/b1)
我们来对比一下两个答案:
ans1=max(a0/b1,a0*a1/b2)
ans2=max(a0/b2,a0*a2/b1)
可以替换得:
ans1=max(k1,k2)
ans2=max(k3,k4)
显然我们可以得到:
a0*a1/b2>a0/b2
a0*a2/b1>a0/b1
即: k2>k3
k4>k1
如果ans1<ans2
那么易得:
k4>k2
即: a0*a2/b1>a0*a1/b2
变形可得:
a1∗b1<a2∗b2
当a1∗b1<a2∗b2时,我们也能够得到ans1<ans2的结论
所以,为了ans取到最小值,我们需要将ai∗bi较小的放在前面
那么我们以ai∗bi为关键字排序即可
同时,统计答案时一定不要忘了写高精度!
Q:对于一个方案,a和b的调换,可能会影响到中间的数结果,怎么办?
A:让我们再来看一看
已知在国王后面的两个点a∗b 较小的应该放在前面,那么将国王左手的a0看做一段序列的乘积A,则又变成了这样的形式:
| * | Left | Right |
|---|---|---|
| king: | A |
|
| p1 | a1 | b1 |
| p2 | a2 | b2 |
对于这两个人来说,根据他们的排列,会贡献两种答案ans1和ans2,我们已经分析过应该怎么排才能取到min(ans1,ans2)
这就相当于对于相邻的两个点来说(先不管别的点怎么排),a∗b 较小的应该放在前面
这样,本来确定的在国王后面的两个点就被推广为了所有点对,根据冒泡排序你的智慧,很容易的发现将所有的点对以a∗b较小的放在前面会使总答案最小
Q:但是我还是不懂为什么点对位置的调换不会影响其他的答案呢?
A:在一段序列后面的两对点不管怎么掉换都不会影响前面那段序列的答案,并且,也不会影响后面序列的答案!
看看关系式,对于前面的序列的答案,根本就后面的点对没关系
对于后面的点对,他们的答案之和前面点的左手乘积和有关
那我将相邻两个点进行掉换,是不是有没有影响两个点前面的序列,又没有影响两个点后面的序列呢?
同时,它还将这两个点所贡献的答案取到了较小值min(ans1,ans2)
那么对于每个点对我们都这么做,掉换的不是当前点对时没影响,而且交换的点对的答案都减小了,那么最终能取到全局最优!(无法掉换以得到更优解)
Q:为什么你证明的是冒泡的方式答案会不断减小,而程序中用的是快排呢?
A:我们证明,当取到最小值时,对于相邻两对数上面的乘积必然要小于下面的乘积,对于整体来说,不就是上面的乘积最小,下面的乘积最大么?
也就是说我们用冒泡的方式证明了乘积的有序性,而使用快排来实现而已
然后是大佬的博客秋葉
这位大佬已经说得很清楚了,主要思路就是把每个大臣所拥有的属性a,b表示出来,设a1b1在前面的情况更优,依据题目列出关于金币数量不等式来,化简并得到最终的排序条件。
代码:
#include<iostream> #include<cstdio> #include<algorithm> #include<cstring> using namespace std; int n,l1,r1,cnt,tep,ans1; int s[21001],f[21001]; struct node{ int l,r,num; }a[1010]; struct node1{ int ss[21001]; int len; }ans; bool cmp(node x,node y){ if(x.num<y.num)return true; else return false; } void cheng(int x){ tep=0; for(int i=1;i<=cnt;i++){ s[i]=s[i]*x+tep; tep=s[i]/10; s[i]%=10; } while(tep){ s[++cnt]=tep%10; tep/=10; } } node1 chu(int x){ node1 c; memset(c.ss,0,sizeof(c.ss)); c.len=0; for(int i=1;i<=cnt;i++)f[i]=s[i]; int sum=0; for(int i=cnt;i>=1;i--){ sum=sum*10+f[i]; if(sum<x&&!c.len)continue; c.ss[++c.len]=sum/x; sum%=x; } if(!c.len)c.len++; return c; } node1 check(node1 x,node1 y){ if(x.len<y.len)return y; else if(x.len>y.len)return x; else{ for(int i=1;i<=x.len;i++){ if(x.ss[i]<y.ss[i]){ return y; } else if(x.ss[i]>y.ss[i]){ return x; } } } return x; } int main() { scanf("%d",&n); scanf("%d%d",&l1,&r1); for(int i=1;i<=n;i++){ scanf("%d%d",&a[i].l,&a[i].r); a[i].num=a[i].l*a[i].r; } sort(a+1,a+n+1,cmp); a[0].l=l1,a[0].r=r1; cnt=1,s[1]=1; ans.len=1; for(int i=1;i<=n;i++){ cheng(a[i-1].l); node1 d=chu(a[i].r); ans=check(ans,d); } for(int i=1;i<=ans.len;i++){ printf("%d",ans.ss[i]); } return 0; }
这道题目还比较简单,最后只要根据a*b来进行排序就可以,接下来看看其它几道不一样的。
【P1248加工生产调度】
题目描述
某工厂收到了n个产品的订单,这n个产品分别在A、B两个车间加工,并且必须先在A车间加工后才可以到B车间加工。
某个产品i在A、B两车间加工的时间分别为Ai、Bi。怎样安排这n个产品的加工顺序,才能使总的加工时间最短。这里所说的加工时间是指:从开始加工第一个产品到最后所有的产品都已在A、B两车间加工完毕的时间。
输入输出格式
输入格式:
第一行仅—个数据n(0<n<1000),表示产品的数量。
接下来n个数据是表示这n个产品在A车间加工各自所要的时间(都是整数)。
最后的n个数据是表示这n个产品在B车间加工各自所要的时间(都是整数)。
输出格式:
第一行一个数据,表示最少的加工时间;
第二行是一种最小加工时间的加工顺序。
输入输出样例
34 1 5 4 2 3
思路
是不是看题面都能和【流水调度问题】对应上
题意很明确,给出n个物品,每个物品需要分别在两个车间加工,并且先去完A才能去B,问最小的总时间。
依然使用邻项交换的思想来进行推理,但推出不等式的排序关系以后还有更需要注意的地方。
以下题解来自洛谷 Irressey
读完题后,我们可以发现,这道题中的决策无后效性,可以用贪心来解。
如何确定贪心的顺序
首先,我们假设只有2个产品,在A车间加工的时间为a1,a2,在B车间加工的时间为b1,b2。我们假设先加工产品1的方案较优
如果先加工1,再加工2,所需时间即为最后加工完2所需的时间。也就是 a1+max(b1,a2)+b2。
反过来,如果先加工2,再加工1,所需时间为 a2+max(b2,a1)+b1。
因为我们假设了先加工产品1的方案较优,所以前一种方案的时间更少,也就是 a1+max(b1,a2)+b2<a2+max(b2,a1)+b1 。
移项,得到max(b1,a2)−a2−b1<max(b2,a1)−b2−a1
然后我们发现不等式两边较大的数都被消掉了,原式即为 −min(b1,a2)<−min(b2,a1)
也就是min(a1,b2)<min(a2,b1)
可以用贪心思想排序的题都有这么一条性质:如果2个物品按某种方法排序时结果较优,那么多个物品按这种方法排序时结果一定最优。
式子化不化简对于结果没有影响,下面是用a1+max(b1,a2)+b2<a2+max(b2,a1)+b1 排序的代码(洛谷上能A,但是方法是错的)
struct node{ long long a,b; //在两个车间分别加工的时间 int in; //原来的下标 bool operator<(const node &x)const{ return a+max(b,x.a)+x.b < x.a+max(x.b,a)+b;//重载小于运算符,用于sort } }c[1005]; sort(c+1,c+n+1);
为什么刚才的方法是错的
因为min(a1,b2)<min(a2,b1)中,不等关系不具有传递性。
表示我翻了一下网上的题解发现都是这么说的,不过后来我手动模拟分类讨论逐一判断一下发现这个式子具有传递性。
不等式的传递性是指:有3个元素x,y,z和不等关系(此处设为a<b),当x<y且y<z时,x<z一定成立。
那么,基于上面的公式排序后,所有相邻的元素都满足min(a1,b2)<min(a2,b1)时,最终结果是正确的。
下面我们考虑min(a1,b2)=min(a2,b1)的情况。设有3个工件x,y,z,我们发现当min(x.a,y.b)=min(x.b,y.a)且min(y.a,z.b)=min(y.b,z.a)时,min(x.a,z.b)=min(x.b,z.a)不一定成立。
举个栗子:x.a=3,x.b=5,y.a=1,y.b=1,z.a=6,z.b=4
如果有3个元素x,y,z和不等关系(此处设为a<b),当x<y,y<x与y<z,z<y均不成立时,x<z与z<x一定不成立,这叫做不可比性的传递性。
(你可以暂时理解为有三个数均相等,这是不可比性的传递性的一个例子。)
而在排序时的不等关系除了要满足传递性外,还要满足不可比性的传递性。所以不能够直接用min(a1,b2)<min(a2,b1)排序。
(如果你对于上述说明还不能完全理解,可以参考一下dalao ouuan的文章 浅谈邻项交换排序的应用以及需要注意的问题%%%ouuan tql)
所以我们要找出一个具有不可比性的传递性的式子
分析一下这个式子,我们发现这与两个元素a,b的大小有关 :
-
a1<b1且a2<b2时,按a1<a2排序。
-
a1=b1且a2=b2时,如何排序对结果没有影响。
-
a1>b1且a2>b2时,按b2<b1排序。
然后我们发现上面的不等式要优先找a比b小的,所以将上面的3种情况按顺序排即可。
于是我们设 -1(ai<bi)
di= 0(ai=bi)
1(ai>bi)
(也就是ai-bi的符号)
以d为第一关键字,d相等的按上面的规则排序即可。
这有个名词叫做Johnson 法则
排序代码 :
bool operator<(const node &x)const{ if(d==x.d){ if(d<=0)return a<x.a;//这里的等于是将上面的情况2找了一种方法排序 else return b>x.b; } return d<x.d; }
然后,这道题需要我们求出总共需要的时间。按题意模拟一下即可。
fa=c[1].a;fb=c[1].a+c[1].b;//fa为i在车间A加工完需要的时间,fb为i在车间B加工完需要的时间 for(int i=2;i<=n;++i){ fb=max(fa+c[i].a,fb)+c[i].b;//i开始在车间B加工时,需要先在车间A加工完成,而且i-1需要完成在车间B的工序 fa+=c[i].a; }
这位大佬解释了为什么按那个min的不等式来排序其实是错误的,并给出了以d为第一关键字的正确排序。
在相邻两项d相等的时候按d的不同情况排序,d=-1时按a升序排,d=1时按b降序排,这样满足a或b大时最优情况不等式的符号。
而d升序排则是因为整体排序使前面的a越小越好,这样可以让一开始B的空闲时间最少,即让B紧跟着A,相当于屯下“存货”。显然d为负的时候,在b相等的情况下a最小。
而关于最后求总体时间,个人还有一种不同的方法,其实是上面证明过程中某一步的变形,但是没有什么人这么写,可能缺乏合理性。
根据解题思路的开头:
设先加工a优于b,a、b两个物品的加工时间分别为a1,b1以及a2,b2,则最短加工时间为a1+max(b1+a2)+b2
解题时排完序以后整个序列已经满足了先加工排在前面的最优,那么可以直接用上面的式子,推广到整个序列,求加工时间
加工时间为:a1+max(a2+a3+a4+...+an,b1+b2+b3+...+bn-1)+bn
开头和结尾的时间一定要分离出来考虑。设ans1=a2+a3+...+an,ans2=b1+b2+b3...+bn
首先在a车间各个物品中间没有加工时间间隔,所以a1+ans1就是a车间整体所用时间。如果a车间加工时间长就选择ans1。这里发现an加工完才能加工bn,所以后面要加上bn
但是如果在b车间加工时间比a长,这个时候b车间整体加工时间为ans2+bn。加工完a1才能加工b1,所以前面要加上a1。
即:
for(int i=1;i<=n;i++){ if(i!=1)ans1+=f[i].a; if(i!=n)ans2+=f[i].b; } printf("%d ",max(ans1,ans2)+f[1].a+f[n].b);
另外,同机房神犇宇興写了证明一种排序的过程,由于是手写版这里直接放博客链接,可以移步去看一下,直接下拉到第二张图片 流水作业调度问题
最后是我的代码:
#include<iostream> #include<cstdio> #include<cmath> #include<algorithm> using namespace std; int n,ans1,ans2; struct node{ int a,b,d,id; }f[1001]; bool cmp(node x,node y){ if(x.d<y.d)return true; else if(x.d==y.d){ if(x.d<=0){ if(x.a<y.a)return true; else return false; } else{ if(x.b>y.b)return true; else return false; } } else return false; } int main() { scanf("%d",&n); for(int i=1;i<=n;i++)scanf("%d",&f[i].a); for(int i=1;i<=n;i++){ scanf("%d",&f[i].b); if(f[i].a==f[i].b)f[i].d=0; else f[i].d=(f[i].a-f[i].b)/abs(f[i].a-f[i].b); f[i].id=i; } sort(f+1,f+n+1,cmp); for(int i=1;i<=n;i++){ if(i!=1)ans1+=f[i].a; if(i!=n)ans2+=f[i].b; } printf("%d ",max(ans1,ans2)+f[1].a+f[n].b); for(int i=1;i<=n;i++)printf("%d ",f[i].id); return 0; }
那么来看下一道题,与这道题有着密切联系。
【P2123皇后游戏】
题目背景
还记得 NOIP 2012 提高组 Day1 的国王游戏吗?时光飞逝,光阴荏苒,两年过去了。国王游戏早已过时,如今已被皇后游戏取代,请你来解决类似于国王游戏的另一个问题。
题目描述
皇后有 n 位大臣,每位大臣的左右手上面分别写上了一个正整数。恰逢国庆节来临,皇后决定为 n 位大臣颁发奖金,其中第 i 位大臣所获得的奖金数目为第i-1 位大臣所获得奖金数目与前 i 位大臣左手上的数的和的较大值再加上第 i 位大臣右手上的数。
形式化地讲:我们设第 i 位大臣左手上的正整数为 ai,右手上的正整数为 bi,则第 i 位大臣获得的奖金数目为 ci可以表达为:
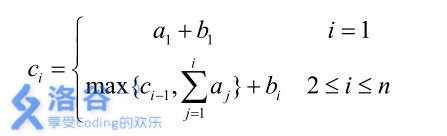
当然,吝啬的皇后并不希望太多的奖金被发给大臣,所以她想请你来重新安排一下队伍的顺序,使得获得奖金最多的大臣,所获奖金数目尽可能的少。
注意:重新安排队伍并不意味着一定要打乱顺序,我们允许不改变任何一位大臣的位置。
输入输出格式
输入格式:
第一行包含一个正整数 T,表示测试数据的组数。
接下来 T 个部分,每个部分的第一行包含一个正整数 n,表示大臣的数目。
每个部分接下来 n 行中,每行两个正整数,分别为 ai和 bi,含义如上文所述。
输出格式:
共 T 行,每行包含一个整数,表示获得奖金最多的大臣所获得的奖金数目。
输入输出样例
说明
按照 1、2、3 这样排列队伍,获得最多奖金的大臣获得奖金的数目为 10;
按照 1、3、2 这样排列队伍,获得最多奖金的大臣获得奖金的数目为 9;
按照 2、1、3 这样排列队伍,获得最多奖金的大臣获得奖金的数目为 9;
按照 2、3、1 这样排列队伍,获得最多奖金的大臣获得奖金的数目为 8;
按照 3、1、2 这样排列队伍,获得最多奖金的大臣获得奖金的数目为 9;
按照 3、2、1 这样排列队伍,获得最多奖金的大臣获得奖金的数目为 8。
当按照 3、2、1 这样排列队伍时,三位大臣左右手的数分别为:
(1, 2)、(2, 2)、(4, 1)
第 1 位大臣获得的奖金为 1 + 2 = 3;
第 2 位大臣获得的奖金为 max{3, 3} + 2 = 5;
第 3 为大臣获得的奖金为 max{5, 7} + 1 = 8。
对于全部测试数据满足:T≤10,1≤n≤20 000,1≤ai,bi≤10^9。
902
思路
这道题看上去和加工生产调度并没关系,看题面和名字好像和国王游戏关系还比较大
但是仔细看ci的定义,就能发现越往后的大臣得到的奖金一定越多,最多的不就是“生产所需总时间”吗
再看这个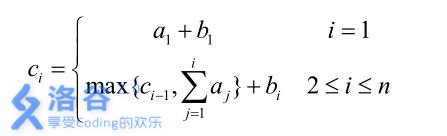
是不是很像加工生产调度中求最后总时间的模拟?
仔细想想,好像还真是那么一回事儿。其实也真就那么一回事儿。
但是这道题的题解中还有优秀的从整个序列推结论的题解,而不是像上面一样只用1,2号物品来推论,这里一样放上来。
以下题解来自洛谷liuzibujian
乍一看,这题和NOIP 2012 提高组 Day1 的国王游戏很像,做题方法应该也差不多,找出一个排序方法,使得以这样排序得到的序列会使最大的ci最小。观察可知,ci是逐渐递增的。我们用相邻交换法考虑。设某个位置上的大臣编号为i,后面一位大臣的编号为j。设i前面所有大臣的a值之和为x,i前面那一位大臣的c值为y。若不交换,则c值较大的大臣的c值(cj)为
max(max(y,x+ai)+bi,x+ai+aj)+bj
化简后为
max(y+bi+bj,x+ai+bi+bj,x+ai+aj+bj)
同理,这两位大臣交换后,c值较大的大臣的c值(ci)为
max(y+bi+bj,x+aj+bi+bj,x+ai+aj+bi)
假设不交换更优,则有
max(y+bi+bj,x+ai+bi+bj,x+ai+aj+bj)≤max(y+bi+bj,x+aj+bi+bj,x+ai+aj+b