一、前言
应用程序之间要想互相通信,一起配合来实现业务功能,还需要有一套传输协议来支持。设计传输协议,并没有太多规范和要求,只要是通信双方的应用程序都能正确处理这个协议,并且没有歧义就好了。
二、如何“断句”
传输协议也是一种语言,那么在应用程序之间“通话”的过程中,与我们人类用自然语言沟通有很多相似之处,但是需要处理的问题却不同。
现代语言都是通过标点符号来分隔句子的,这个叫“断句”。我们在传输数据的时候,首先要解决的就是断句问题。对于传输层来说,收到的数据就是一段一段的字节,但是,因为网络的不确定性,你收到的分段并不一定是我们发出去的分段。
1、在协议中加上标点符号
这个办法是可行的,也有很多传输协议采用这种方法,比如HTTP1协议,它的分隔符是换行( )。这个办法有一个问题比较难处理,在自然语言中,标点符号是专用的,它没有别的含义,和文字是有天然区分的。
在数据传输的过程中,无论你定义什么字符作为分隔符,理论上,它都有可能会在传输的数据中出现。为了区分“数据内的分隔符”和真正的分隔符,你必须得在发送数据阶段,加上分隔符之前,把数据内的分隔符做转义,收到数据之后再转义回来。这是个比较麻烦的过程,还要损失一些性能。
2、预置长度
我们给每句话前面加一个表示这句话长度的数字,收到数据的时候,我们按照长度来读取就可以了。比如:
03 下雨天 03 留客天 02 天留 03 我不留
1.这里面我们固定使用 2 位数字来存放长度,每句话最长可以支持到 99 个字。
2.接收后的处理就比较简单了,我们先读取 2 位数字 03,知道接下来的 3 个字是第一句话,那我们接下来就等着这 3 个字都收到了,就可以作为第一句话来处理了。
3.接下来再按照这个方法来读第二句话、第三句话。
这种方法就很好解决了断句的问题,并且它实现起来要比分隔符的方法简单很多,性能也更好,是目前普遍采用的一种分隔数据的方法。
如果使用预置长度的方法,数据中也含有数字,数据中的数字是不需要作任何处理的。因为在解析的时候,可以明确的知道当前读到的这个位置应该是长度还是真正的数据,它是不需要根据数据流中的内容来确定的。
三、用双工收发协议提升吞吐量
所谓的单工通信就是,任何一个时刻,数据只能单向传输,一个人说的时候,另外一个人只能听。
HTTP1 协议,就是这样一种单工协议,客户端与服务端建立一个连接后,客户端发送一个请求,直到服务端返回响应或者请求超时,这段时间内,这个连接通道上是不能再发送其他请求的。这种单工通信的效率是比较低的,很多浏览器和 App 为了解决这个问题,只能同时在服务端和客户端之间创建多个连接,这也是没有办法的办法。
单工通信时,一句对一句,请求和响应是按照顺序依次收发,有一个天然的对应关系。比如说,张大爷和李大爷俩大爷碰上了:
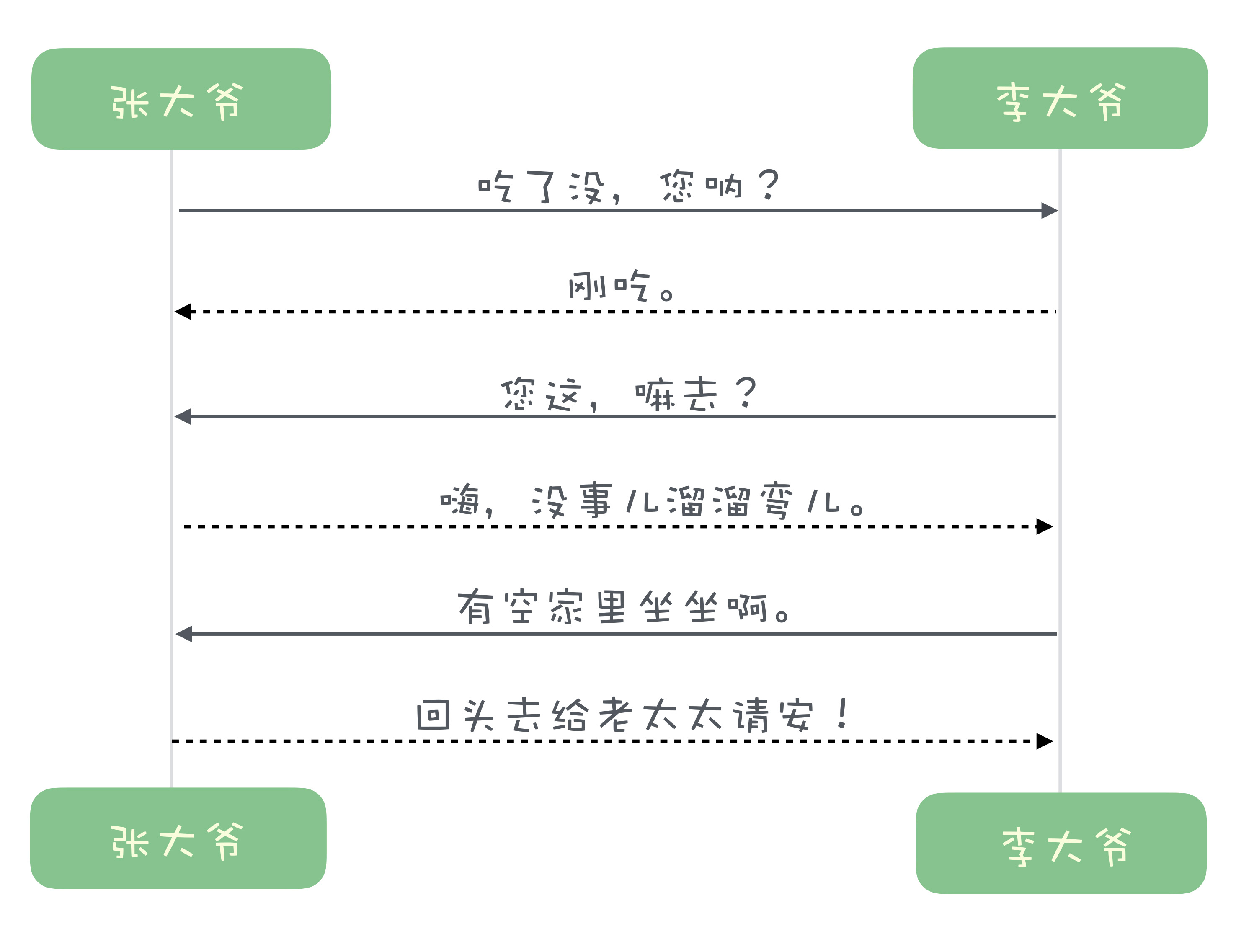
这个图里面,实线是请求,虚线是响应,一问一答,这是单工协议。
TCP 连接它是一个全双工的通道,你可以同时进行数据的双向收发,互相是不会受到任何影响的。要提高吞吐量,应用层的协议也必须支持双工通信。

这时候就出现一个问题,即使俩大爷有这个边听边说的本事,问题和答案可能已经对不上了。在多线程并发的环境下,顺序也没有办法保证。
在实际上设计协议的时候,我们一般不关心顺序,只要需要确保请求和响应能够正确对应上就可以了。这个问题我们可以这样解决:发送请求的时候,给每个请求加一个序号,这个序号在本次会话内保证唯一,然后在响应中带上请求的序号,这样就可以把请求和响应对应上了。

张大爷和李大爷可以对自己发出去的请求来编号,回复对方响应的时候,带上对方请求的编号就可以了。这样就解决了双工通信的问题。
如果结合上面提到的使用预置长度方法分隔数据,那传输的数据格式应该是:开头是数据长度,序号也是数据的一部分,所以应该在长度之后。
四、总结
- 在设计传输协议的时候,只要双方应用程序能够识别传输协议,互相交流就可以了,并没有什么一定要遵循的规范。
- 在设计传输协议的时候,需要解决如何断句的问题,提供了“分隔符”和“前置长度”两种断句的方法可以选择使用。
- 介绍的这种“使用 ID 来标识请求与响应对应关系”的方法,是一种比较通用的实现双工通信的方法,可以有效提升数据传输的吞吐量。
- 解决了断句问题,实现了双工通信,配合专用的序列化方法,你就可以实现一套高性能的网络通信协议,实现高性能的进程间通信。很多的消息队列、RPC 框架都是用这种方式来实现它们自己的私有应用层传输协议。