一、生产者消息分区机制原理剖析
在使用Kafka 生产和消费消息的时候,肯定是希望能够将数据均匀地分配到所有服务器上。比如很多公司使用 Kafka 收集应用服务器的日志数据,这种数据都是很多的,特别是对于那种大批量机器组成的集群环境,每分钟产生的日志量都能以 GB 数,因此如何将这么大的数据量均匀地分配到 Kafka 的各个 Broker 上,就成为一个非常重要的问题。
1.1、kafka为什么分区?
kafka有主题(Topic)的概念,它是承载真实数据的逻辑容器,而在主题之下还分为若干个分区,kafka的消息组织方式是三级结构:主题 - 分区 - 消息。主题下的每条消息只会保存在某个分区中,而不会在多个分区中被保存多份。

分区的作用就是提供负载均衡的能力,就是为了实现系统的高伸缩性。不同的分区能够被放置在不同节点的机器上,而数据的读写操作也都是针对分区这个粒度而进行的,这样每个节点的机器都能独立地执行各自的分区的读写请求处理。还可以添加新的节点机器来增加整体系统的吞吐量。
利用分区也可以实现其他一些业务级别的需求,比如实现业务级别的消息顺序的问题。
1.2、kafka生产者分区策略
所谓分区策略是决定生产者将消息发送到哪个分区的算法。kafka为我们提供了默认的分区策略,同时也支持自定义分区策略。自定义分区策略需要显式地配置生产者端的参数partitioner.class。
1.2.1、轮询策略
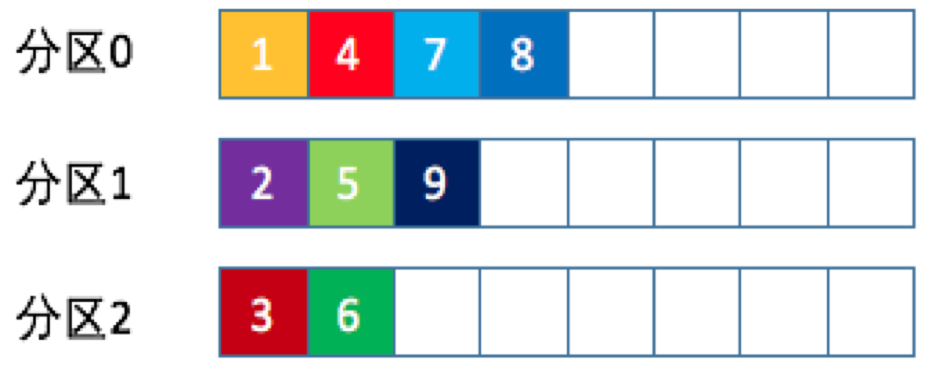
也称Round-robin策略,即顺序分配。比如一个主题下有3个分区,那么第一条消息被发送到分区0,第二条消息被发送到分区1,第三条被发送到分区2,以此类推。当第四条消息时又会重新开始,即分配到分区0。

轮询策略是kafka java生产者API默认提供的分区策略。如果未指定partitioner.class参数,那么你的生产者程序会按照轮询的方式在主题的所有分区均匀地“码放”消息。
轮询策略有非常优秀的负载均衡表现,它总是能保证消息最大限度地被平均分配到所有分区上,故默认情况下它是最合理的分区策略,也是最常用的分区策略之一。
1.2.2、随机策略
也称Randomness策略。所谓随机就是随意地将消息放置到任意一个分区上。
要实现随机策略只需要:先计算出该主题总分区数,然后随机返回一个小于它的整数值。从实际表现看,随机策略要逊于轮询策略,所以如果追求数据的均匀分布,还是使用轮询策略比较好。事实上,随机策略是老版本生产者使用的分区策略,在新版中已经改为轮询。
1.2.3、按消息键保序策略
kafka允许为每条消息定义消息键,简称Key。它可以是一个有着明确业务含义的字符串,比如客户代码、部门编号或是业务ID等;也可以用来表征消息元数据,特别是在kafka不支持时间戳的年代,在一些场景中,直接将消息创建时间封装进Key里面。
一旦消息被定义了Key,那么你就可以保证同一个Key的所有消息都进入到相同的分区里面,每个分区下的消息处理都是有顺序的,如下图所示:
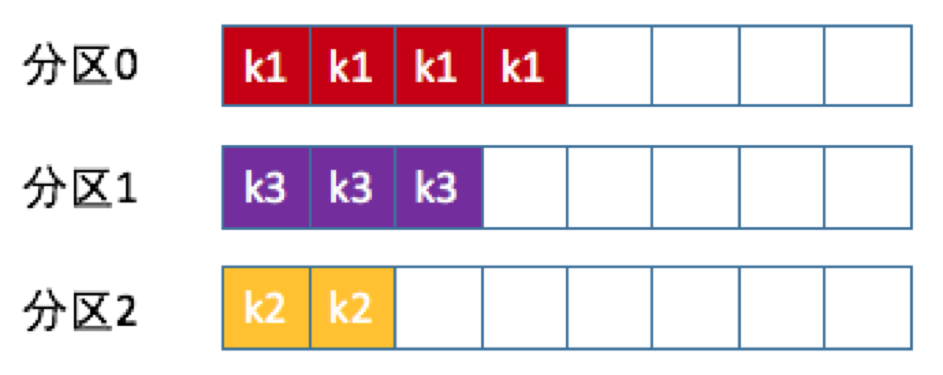
前面提到的kafka默认分区策略实际上同时实现了两种策略:如果指定了Key,那么默认实现按消息键保序策略;如果没有指定Key,则使用轮询策略。