一、单向链表
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列节点组成,节点可以在运行时动态生成,链表利用节点来存储数据,节点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
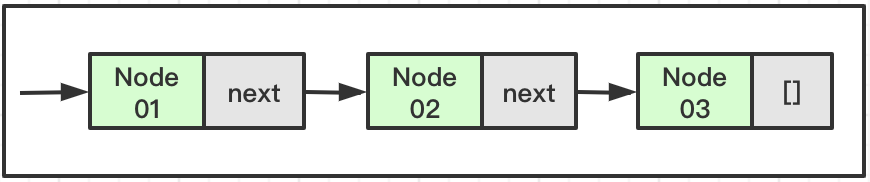
单向链表即一条线性链表,只能向下取值。通过下图我们可以知道,他只能从next上获取下一个节点的数据,而不能获取上一个。又因为链表可以不断是向后取值,所以如果我们只要知道其开始的头节点位置,那么就可以通过遍历链表来获取其中我们想要的数据。所以头结点在单向链表中是至关重要的。
特点:
- 物理存储上是无序且不连续的;
- 链表是由多个节点以链式结构组成;
- 逻辑层面上看形成一个有序的链路结构;
优点:
- 链表结构解决数组存储需要预先知道元素个数的缺陷,可以充分利用内存空间,实现灵活的内存动态管理。
- 插入和删除节点的时间复杂度最优能达到O(1),注意,这里是最优情况。关于时间复杂度分析,看这个博客https://blog.csdn.net/gaoxiangnumber1/article/details/44634485
缺点:只能从头到尾遍历。只能找到后继,无法找到前驱,也就是只能前进
# LinkedList.py
# 节点类
class Node(object):
# 初始化,需要传入节点的数据
def __init__(self, data):
self.data = data
self.next = None
# 链表类
class LinkList:
def __init__(self):
self.head = None
self._size = 0
def size(self):
return self._size
def is_empty(self):
return self.head is None
# 在链表中添加一个节点,其实就是把当前头指针的值先给这个节点的next。然后把当前的头指针指向这个节点对象
# add,在头部追加
def add(self, value):
node = Node(value)
node.next = self.head
self.head = node
self._size += 1
# append,在尾部追加
def append(self, value):
if self._size == 0:
self.add(value)
return
node = Node(value)
obj = self._find_index_obj(self._size - 1)
obj.next = node
self._size += 1
def contains(self, value):
cursor = self.head
while cursor:
if cursor.data == value:
return True
cursor = cursor.next
return False
def get(self, index):
obj = self._find_index_obj(index)
return obj.data
def set(self, index, value):
obj = self._find_index_obj(index)
obj.data = value
def remove(self, index):
obj = self._find_index_obj(index - 1)
obj.next = obj.next.next
self._size -= 1
def index_of(self, value):
cursor = self.head
index = 0
while cursor:
if cursor.data == value:
return index
cursor = cursor.next
index += 1
return -1
def clear(self):
self.head = None
self._size = 0
def _find_index_obj(self, index):
cursor = self.head
l = 0
while cursor:
if l == index:
return cursor
cursor = cursor.next
l += 1
raise IndexError('索引越界')
def _out_of_index(self, index):
self.size()
if index < 0 or index >= self._size:
raise IndexError('索引越界')
def linklist(self):
l = []
cursor = self.head
# print(cursor)
while cursor:
# print(cursor.data)
l.append(cursor.data)
cursor = cursor.next
return l
# 测试文件,test.py
if __name__ == '__main__':
from LinkedList import LinkList
link = LinkList()
link.add(4)
link.append(77)
link.append(88)
link.append(99)
link.add(3)
link.add(2)
# link.clear()
# print(link.size())
# print(link.is_empty())
# print(link.index_of(77))
# print(link.get(3))
# link.set(3,5)
# link.set(745,6)
# print(link.contains(47))
# link.remove(3)
# link.remove(3)
# link.remove(88)
print(link.linklist())