这是第二次分析concurrentHashMap
先回顾一下
1.concurrentHashMap是在jdk1.5版本之后推出的,位于java.util.concurrent包中。
2.基于HashMap 对于多线程并发操作不安全,以及HashMap 效率低,才推出分段锁机制concurrentHashMap。
concurrentHashMap分析
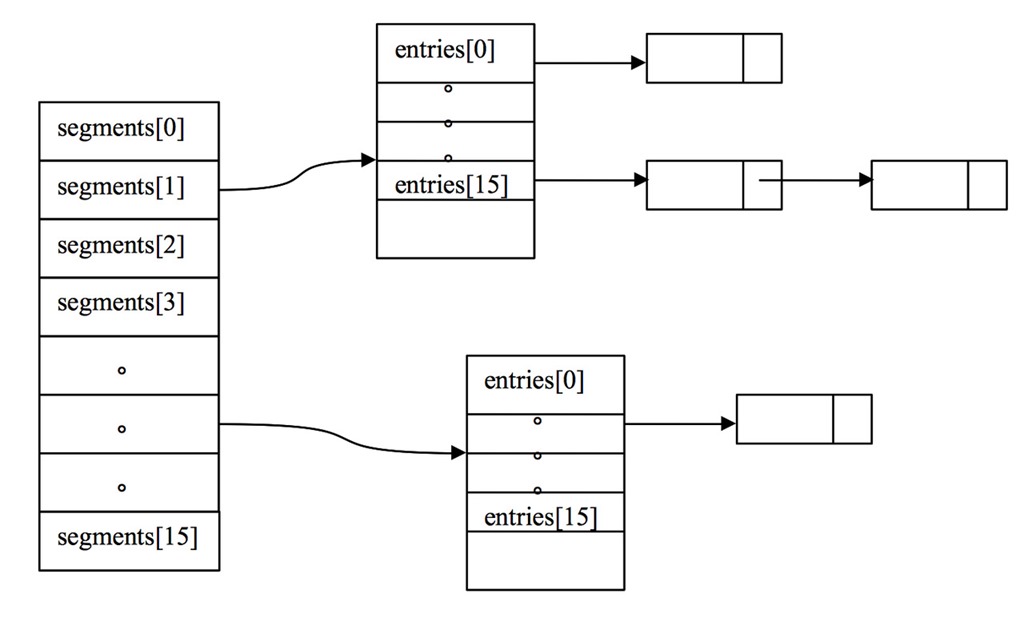
一、结构解析
三、源码解读
ConcurrentHashMap中主要实体类就是三个:ConcurrentHashMap(整个Hash表),Segment(桶),HashEntry(节点),对应上面的图可以看出之间的关系
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V> implements ConcurrentMap<K, V>, Serializable { //Segment数据 final Segment<K,V>[] segments; static final class Segment<K,V> extends ReentrantLock implements Serializable { //HashEntry数据 transient volatile HashEntry<K,V>[] table; } static final class HashEntry<K,V> { final int hash; //真实的K值 final K key; //真实的value值 volatile V value; //纸箱下一个HashEntry链表的引用 volatile HashEntry<K,V> next; } }
删除操作
可以看到除了value不是final的,其它值都是final的,这意味着不能从hash链的中间或尾部添加或删除节点,因为这需要修改next 引用值,所有的节点的修改只能从头部开始。对于put操作,可以一律添加到Hash链的头部。但是对于remove操作,可能需要从中间删除一个节点,这就需要将要删除节点的前面所有节点整个复制一遍,最后一个节点指向要删除结点的下一个结点。这在讲解删除操作时还会详述。为了确保读操作能够看到最新的值,将value设置成volatile,这避免了加锁。


put操作
@SuppressWarnings("unchecked")
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
//首先根据hash算法,定位到具体的segment
s = ensureSegment(j);
//然后在sement中,lock操作,添加
return s.put(key, hash, value, false);
}
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
参考:
http://www.cnblogs.com/yydcdut/p/3959815.html