



















Aprior算法流程
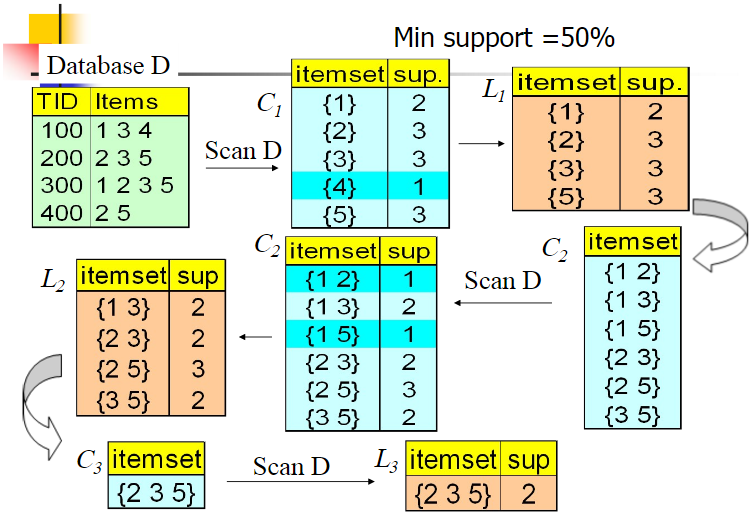
下面我们对Aprior算法流程做一个总结。
输入:数据集合D,支持度阈值αα
输出:最大的频繁k项集
1)扫描整个数据集,得到所有出现过的数据,作为候选频繁1项集。k=1,频繁0项集为空集。
2)挖掘频繁k项集
a) 扫描数据计算候选频繁k项集的支持度
b) 去除候选频繁k项集中支持度低于阈值的数据集,得到频繁k项集。如果得到的频繁k项集为空,则直接返回频繁k-1项集的集合作为算法结果,算法结束。如果得到的频繁k项集只有一项,则直接返回频繁k项集的集合作为算法结果,算法结束。
c) 基于频繁k项集,连接生成候选频繁k+1项集。
3) 令k=k+1,转入步骤2。
从算法的步骤可以看出,Aprior算法每轮迭代都要扫描数据集,因此在数据集很大,数据种类很多的时候,算法效率很低。

