| 软件工程 | https://edu.cnblogs.com/campus/gdgy/informationsecurity1812 |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/gdgy/informationsecurity1812/homework/11155 |
| 作业目标 | 论文查重算法设计+单元测试+JProfiler+PSP表格+Git管理 |
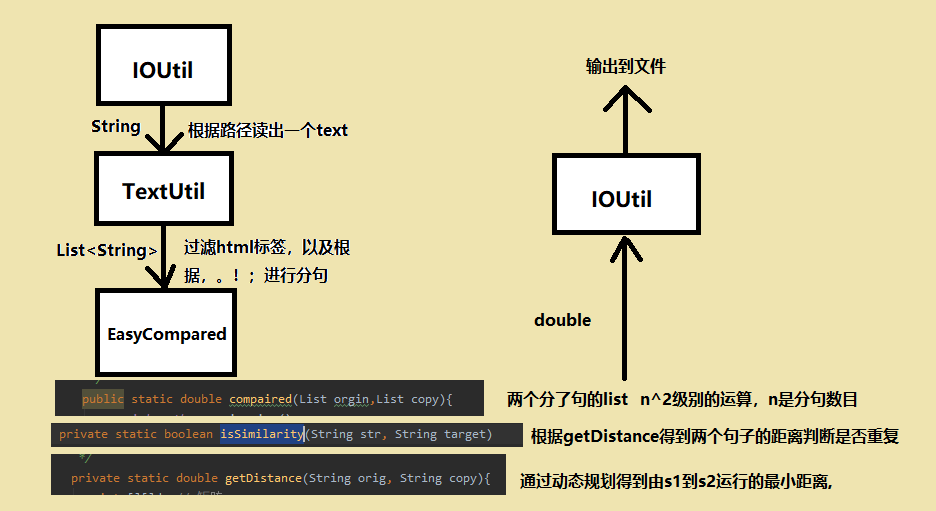
整体流程
- 程序入口MainApplication里面传入:需要检验重复的文章,要对比的文章,以及输出的文章。
- IOUtil进行io的读写操作,获得文本
- TextUtil过滤去html标签,同时分句,获得一个分句的list
- 两边要检测的文本进行m*n级别的比照
- 每句的比照重复使用EasyCompared中的compaired方法,利用动态规划getDistance获得两个句子之间最少的移动距离。最后根据移动的距离以及两个句子的长度,来计算这两个句子是否相似
- 最后根据相似的句子的数目,和总句子的数目来计算相似度。
- 最后输出将相似度写入文件
项目结构

主要的算法
//动态转移方程
d[i][j] = getMin(d[i - 1][j] + 1, d[i][j - 1] + 1, d[i - 1][j - 1]+ temp);
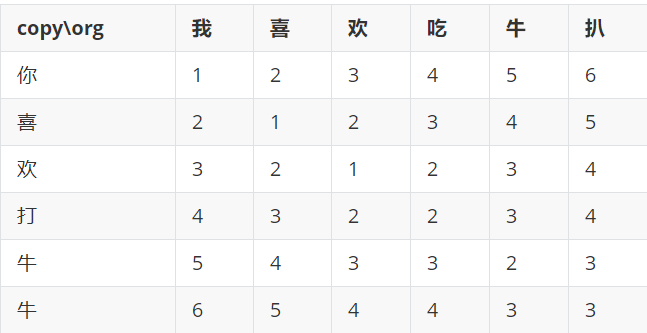
我们这个表是对比"我喜欢吃牛扒"和"你喜欢打牛牛"
可以看到(欢,欢)这个坐标是1,这个1表示的是,"我喜欢"和"你喜欢"之间的距离间隔着1,这两个词之间最少经过1次字符的变换就能得到另一个词。
那这个1怎么来的呢,我们可以试想一下,"你喜欢"和"我喜欢"的上一步,到底是怎么经过最少次变换得来的,可以找
"我喜"->"你喜欢"
"我喜欢"->"你喜"
"我喜"->"你喜"
分别对应的坐标是d[i - 1][j],d[i][j - 1],d[i - 1][j - 1]
只要我们知道,这三者的中最小的(上一次+本次变换步数)就可以得到到底变换了多少步骤。
最后就可以得出这条动态转移方程。
d[i][j] = getMin(d[i - 1][j] + 1, d[i][j - 1] + 1, d[i - 1][j - 1]+ temp);
距离得到了,那怎么判断这两个句子是否相似呢,这里我就设计了一个值,k
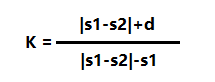
|s1-s2|是s1和s2之间的长度差
d是s1和s2的变换距离差。
根据算出来的k值再判断两个k是否相似。
k越小越相似!
一开始想设计d/s1,但是这样一想好像有点不对劲,因为"我"和"我喜欢吃蒜香鸡"这两个句子算的话d/s1就会是一个巨大的数据
于是假如|s1-s2|消除一下句子过长的影响。
这条式子其实可以再优化一下,不过概率论没学好,以后继续加油。
最后我们就可以得到,原文中存在重复句子的个数,
用原文/疑似原文就可以得到重复度。
时间复杂度分析
时间复杂大概是O(n2),首先进行m*n级别的句子匹配,每对句子之间要进行a2级别的匹配。但是总体来说,基本上每个字都要经历一次句子长度*疑似文本长度的运算。
代码测试的覆盖度
import org.junit.AfterClass;
import org.junit.BeforeClass;
import org.junit.Test;
public class MainApplicationTest {
@BeforeClass
public static void beforeTest(){
System.out.println("junit单元测试开始");
}
@AfterClass
public static void afterTest(){
System.out.println("junit单元测试结束");
}
/**
* 测试 正常的测试
*/
@Test
public void testForAdd(){
MainApplication.run("C:\homework\orig.txt","C:\homework\orig_0.8_add.txt","C:\homework\happy.txt");
}
/**
* 测试 删除orig_0.8_del.txt
*/
@Test
public void testForDel(){
MainApplication.run("C:\homework\orig.txt","C:\homework\orig_0.8_del.txt","C:\homework\happy.txt");
}
/**
* 测试 分割orig_0.8_dis_1.txt
*/
@Test
public void testForDis1(){
MainApplication.run("C:\homework\orig.txt","C:\homework\orig_0.8_dis_1.txt","C:\homework\happy.txt");
}
/**
* 测试 分割orig_0.8_dis_10.txt
*/
@Test
public void testForDis10(){
MainApplication.run("C:\homework\orig.txt","C:\homework\orig_0.8_dis_10.txt","C:\homework\happy.txt");
}
/**
* 测试 分割orig_0.8_dis_15.txt
*/
@Test
public void testForDis15(){
MainApplication.run("C:\homework\orig.txt","C:\homework\orig_0.8_dis_15.txt","C:\homework\happy.txt");
}
/**
* 测试 传入的文件路径错误
*/
@Test
public void testFororigpath(){
MainApplication.run("don't run","C:\homework\orig_0.8_dis_15.txt","C:\homework\happy.txt");
}
}
异常的处理

文件名不对的时候的报错

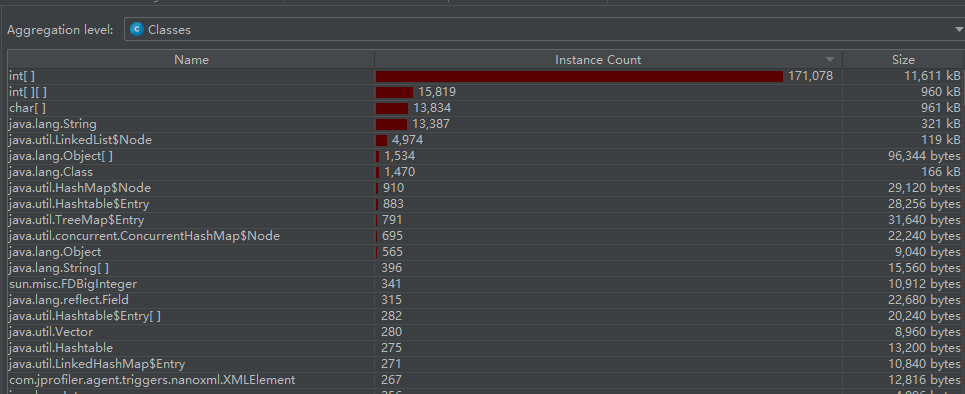
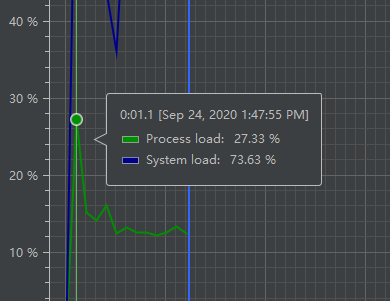
JProfile进行性能测试
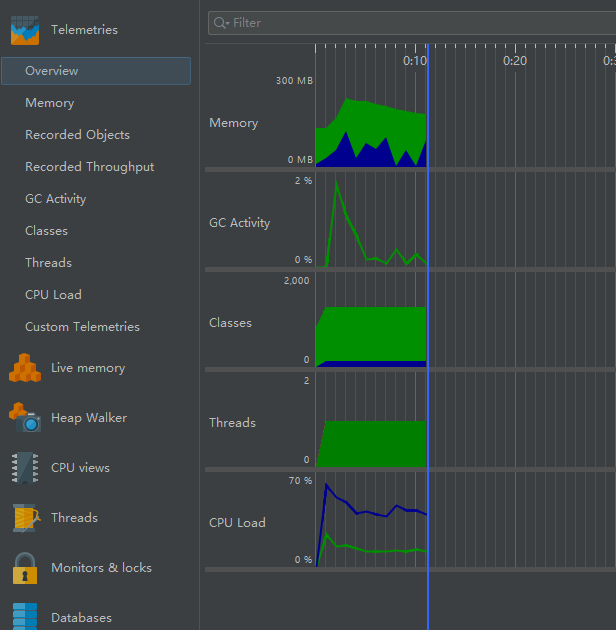
内存的使用情况
cpu的运行时间
耗时最长的地方

是getdistance方法,由于必须进行n^2级别的运算才能算完,而且已经是优化过后的动态规划了,所以改不了-3-。
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 180 | 250 |
| Development | 开发 | 30 | 35 |
| · Analysis | · 需求分析 (包括学习新技术) | 15 | 30 |
| · Design Spec | · 生成设计文档 | 25 | 25 |
| · Design Review | · 设计复审 | 15 | 15 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 30 |
| · Design | · 具体设计 | 25 | 25 |
| · Coding | · 具体编码 | 20 | 20 |
| · Code Review | · 代码复审 | 20 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 35 |
| Reporting | 报告 | 30 | 40 |
| · Test Repor | · 测试报告 | 30 | 40 |
| · Size Measurement | · 计算工作量 | 15 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| · 合计 | 485 | 625 |
总结
1.这次个人项目收获了挺多东西,尤其是第一次借助到测试这个工作,以及这些工具jProfile,还有使用junit进行单元测试
2.学到了不少算法,虽然写上去的还是自己想的,这个算法有优点也有缺点,优点就是,思路比较简单,不用依赖外部的库,而且是靠句子来分割的,判断重复的力度大一点,缺点也是很明显的,没有句意分析,同义词,以及时间复杂度过高的问题,看了不少大佬写的太优秀了。
3.最后发现自己还有很多不足的地方,以后要加把劲吼。