第一章 测试概述
1.1基本定义
错误、缺陷:缺陷是错误的表现;
失效:缺陷执行时会产生失效,比如米开朗琪罗病毒。有效的评审可以做出很多遗漏的缺陷
事故;
测试:测试要处理错误、缺陷、失效、事故。测试有两个显著目标:找出失效或者演示正确的执行。
测试用例:测试用例有一个表示,并且与程序行为有关,还有一组输入和一组输出预期。
1.2测试用例
测试用例需要被开发、评审、使用、管理、保存
1.3通过维恩图理解测试
需求规格书&程序实现
测试要尽可能的多覆盖两者的交集、并集、交非集
1.4标识测试用例
1.4.1功能性测试
黑盒测试,唯一有效信息是软件规则说明书, 优点:功能性测试与软件实现没有关系、测试用例的设计可以与软件实现并行,缺点:局限于软件规则说明书
1.4.2结构性测试
白盒测试,局限于编程实现,
1.4.3功能性测试与结构性测试的比较
两者相结合
1.5错误与缺陷分类
可以从多个角度,常见的从严重程度
1.6测试级别
软件测试系列之软件测试过程模型 http://blog.csdn.net/caozhangyingfei0109/article/details/39989711
第二章 举例
啥意思
第三章 测试人员的离散数学
3.1集合
韦恩图
集合关系:子集、真子集、相等集合
3.2函数
定义域、值域
函数类型与测试的关系:一对一、一对多、多对一、多对多。一对一是要多测试的
集合关系
3.3关系
3.4命题逻辑
与或非
实践:等价类测试
第四章 测试人员的图论
图论是拓扑学的分支之一。
4.1图
图:节点集合和边集合
图定义: 图(graph)并不是指图形图像(image)或地图(map)。通常来说,我们会把图视为一种由“顶点”组成的抽象网络,网络中的各顶点可以通过“边”实现彼此的连接,表示两顶点有关联。注意上面图定义中的两个关键字,由此得到我们最基础最基本的2个概念,顶点(vertex)和边(edge)。直接上图吧。
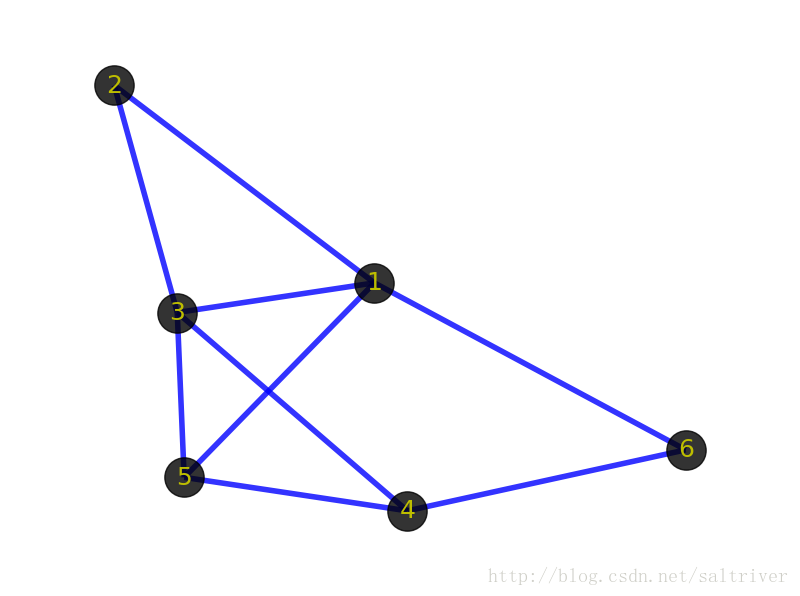
节点的度:deg(n1)=2,代表流行程度,你有两个关系
关联矩阵:拥有m个节点,n跳变的图G=(V,E)的关联矩阵是一个m*n矩阵,其中第i行第j列元素是1,当且仅当节点i是边j的一个端点,否则该元素为0。
常用的逻辑:任何列的表项和为2,每条边都恰好有两个端点。
相邻矩阵:m*m矩阵
路径:测试的结构化方法都以程序里的路径类型为核心。
上图中黑色的带数字的点就是顶点,表示某个事物或对象。由于图的术语没有标准化,因此,称顶点为点、节点、结点、端点等都是可以的。叫什么无所谓,理解是什么才是关键。
上图中顶点之间蓝色的线条就是边,表示事物与事物之间的关系。需要注意的是边表示的是顶点之间的逻辑关系,粗细长短都无所谓的。包括上面的顶点也一样,表示逻辑事物或对象,画的时候大小形状都无所谓。
先看看下面2张图: 

首先你的感觉是这2个图肯定不一样。但从图(graph)的角度出发,这2个图是一样的,即它们是同构的。前面提到顶点和边指的是事物和事物的逻辑关系,不管顶点的位置在哪,边的粗细长短如何,只要不改变顶点代表的事物本身,不改变顶点之间的逻辑关系,那么就代表这些图拥有相同的信息,是同一个图。同构的图区别仅在于画法不同。
四、有向/无向图(Directed Graph/ Undirected Graph)
最基本的图通常被定义为“无向图”,与之对应的则被称为“有向图”。两者唯一的区别在于,有向图中的边是有方向性的。下图即是一个有向图,边的方向分别是:(1->2), (1-> 3), (3-> 1), (1->5), (2->3), (3->4), (3->5), (4->5), (1->6), (4->6)。要注意,图中的边(1->3)和(3->1)是不同的。有向图和无向图的许多原理和算法是相通的。 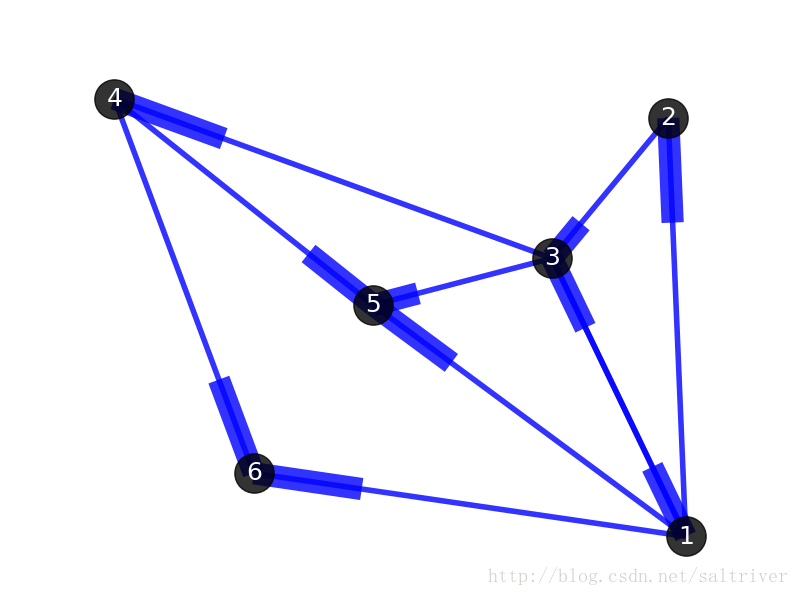
边的权重(或者称为权值、开销、长度等),也是一个非常核心的概念,即每条边都有与之对应的值。例如当顶点代表某些物理地点时,两个顶点间边的权重可以设置为路网中的开车距离。下图中顶点为4个城市:Beijing, Shanghai, Wuhan, Guangzhou,边的权重设置为2城市之间的开车距离。有时候为了应对特殊情况,边的权重可以是零或者负数,也别忘了“图”是用来记录关联的东西,并不是真正的地图。 
在图上任取两顶点,分别作为起点(start vertex)和终点(end vertex),我们可以规划许多条由起点到终点的路线。不会来来回回绕圈子、不会重复经过同一个点和同一条边的路线,就是一条“路径”。两点之间存在路径,则称这2个顶点是连通的(connected)。
还是上图的例子,北京->上海->广州,是一条路径,北京->武汉->广州,是另一条路径,北京—>武汉->上海->广州,也是一条路径。而北京->武汉->广州这条路径最短,称为最短路径。
路径也有权重。路径经过的每一条边,沿路加权重,权重总和就是路径的权重(通常只加边的权重,而不考虑顶点的权重)。在路网中,路径的权重,可以想象成路径的总长度。在有向图中,路径还必须跟随边的方向。
值得注意的是,一条路径包含了顶点和边,因此路径本身也构成了图结构,只不过是一种特殊的图结构。
环,也成为环路,是一个与路径相似的概念。在路径的终点添加一条指向起点的边,就构成一条环路。通俗点说就是绕圈。 
上图中,北京->上海->武汉->广州->北京,就是一个环路。北京->武汉->上海->北京,也是一个环路。与路径一样,有向图中的环路也必须跟随边的方向。环本身也是一种特殊的图结构。
八、连通图/连通分量(connected graph/connected component)
如果在图G中,任意2个顶点之间都存在路径,那么称G为连通图(注意是任意2顶点)。上面那张城市之间的图,每个城市之间都有路径,因此是连通图。而下面这张图中,顶点8和顶点2之间就不存在路径,因此下图不是一个连通图,当然该图中还有很多顶点之间不存在路径。 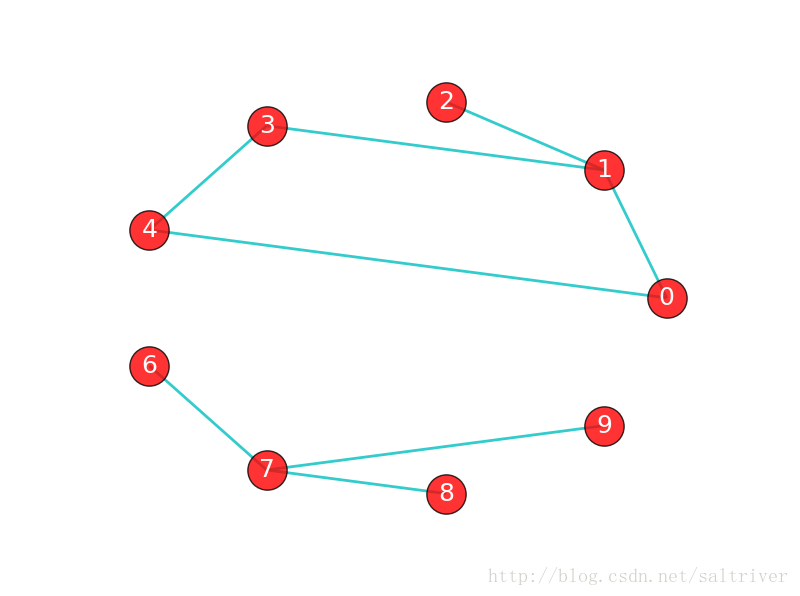
上图虽然不是一个连通图,但它有多个连通子图:0,1,2顶点构成一个连通子图,0,1,2,3,4顶点构成的子图是连通图,6,7,8,9顶点构成的子图也是连通图,当然还有很多子图。我们把一个图的最大连通子图称为它的连通分量。0,1,2,3,4顶点构成的子图就是该图的最大连通子图,也就是连通分量。连通分量有如下特点:
1)是子图;
2)子图是连通的;
3)子图含有最大顶点数。
注意:“最大连通子图”指的是无法再扩展了,不能包含更多顶点和边的子图。0,1,2,3,4顶点构成的子图已经无法再扩展了。
显然,对于连通图来说,它的最大连通子图就是其本身,连通分量也是其本身。
——————————————————————————————————————————————————————————
4.3 用于测试的图
4.3.1程序图
4.3.2有限状态机

* 状态总数(state)是有限的。
* 任一时刻,只处在一种状态之中。
* 某种条件下,会从一种状态转变(transition)到另一种状态。
4.3.3petri网
软件问题:软件工程问题的探讨已经很多了,以Brooks的“软件怪兽现象”最为著名。在“大型应用项目逐步分解为小模块,直至一个算法问题”的过程中,有3个问题无法解决:1、分解的正确性,2、衡量分解质量的有效性,3、最终的算法可实现性。
我们知道,计算机应用系统本质上都是一个物理系统,因为其最终要解决实践问题。而软件算法问题,本质上是一个数学模型,当我们把物理现象抽象为纯数学问题的时候,我们忽略了很多物理系统中的非数学的要素。
当我们把物理系统里的数学问题解决掉以后,这些非数学的因素就逐步显露出来的,而成为了计算机问题的主要矛盾。这就是软件问题的本质。
那么,物理系统中除了数学问题以外,还有什么本原问题呢?哲学,对了,就是哲学。所以在人类的某些文明里,哲学与数学一样,属于理学范畴。
那么petri的Petri网系统分析可以减少以上问题,
正确性分析:如果这个分解过程是遵循的Petri网论的话,那么可达性等系统正确性分析就可以验证这个过程是否正确。
性能和效率分析:petri中有不变量等系统性能与效率分析就是研究系统损耗的理论
4.3.4事件驱动的petri网
4.3.5状态图
图论算法简介:
https://blog.csdn.net/saltriver/article/details/54428685
很久以前某位大仙对petri网的总结:
https://blog.csdn.net/oney139/article/details/39120323
第五章 边界值测试
5.1边界值分析
边界值分析关注的是输入空间的边界。
边界值测试基本原理是错误更可能出现在输入变量的极值附近。因此基本思想是最小、略高于最小、正常、最大、略低于最大
单缺陷理论说,失效极少是由两个(或多个)缺陷同时引起的,所以遇到两个变量的边界值分析时,保持固定变量法。