1. kafka是什么,主要应用在哪里
Kafka 是⼀个分布式流式处理平台。这到底是什么意思呢?
- 流平台具有三个关键功能:
- 消息队列:发布和订阅消息流,这个功能类似于消息队列,这也是 Kafka 也被归类为消息队列的原因。
- 容错的持久⽅式存储记录消息流: Kafka 会把消息持久化到磁盘,有效避免了消息丢失的⻛险。
- 流式处理平台: 在消息发布的时候进⾏处理, Kafka 提供了⼀个完整的流式处理类库。
- Kafka 主要有两⼤应⽤场景:
- 消息队列 :建⽴实时流数据管道,以可靠地在系统或应⽤程序之间获取数据。
- 数据处理: 构建实时的流数据处理程序来转换或处理数据流。
2. kafka的优势
- 极致的性能与生态系统的兼容性
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 高并发:支持数千个客户端同时读写
3. 队列模型,kafka的消息模型
-
队列模型
使⽤队列(Queue)作为消息通信载体,满⾜⽣产者与消费者模式,⼀条消息只能被⼀个消费者使⽤(消息最有一次性,消费了就没有了),未被消费的消息在队列中保留直到被消费或超时。无法做到不同的客户端重复消费。 -
kafka:发布-订阅模型
使⽤主题(Topic) 作为消息通信载体,类似于⼴播模式;发布者发布⼀条消息,该消息通过主题传递给所有的订阅者, 在⼀条消息⼴播之后才订阅的⽤户则是收不到该条消息的。若只有一个消费者,则和队列模型类似。
4.kafka的设计架构
4.1 简单架构如下
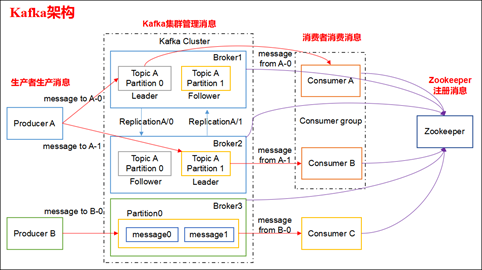
4.2 Kafka 架构分为以下几个部分
- Producer:消息生产者,就是向 kafka broker 发消息的客户端。
- Consumer:消息消费者,向 kafka broker 取消息的客户端。
- Topic:可以理解为一个队列,一个 Topic 又分为一个或多个分区。
- Consumer Group:这是 kafka 用来实现一个 topic 消息的广播(发给所有的 consumer)和单播(发给任意一个 consumer)的手段。一个 topic 可以有多个 Consumer Group。
- Broker:一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic。
- Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker上,每个 partition 是一个有序的队列。partition 中的每条消息都会被分配一个有序的id(offset)。将消息发给 consumer,kafka 只保证按一个 partition 中的消息的顺序,不保证一个 topic 的整体(多个 partition 间)的顺序。
- Offset:kafka 的存储文件都是按照 offset.kafka 来命名,用 offset 做名字的好处是方便查找。例如你想找位于 2049 的位置,只要找到 2048.kafka 的文件即可。
备注:
- Topic 是逻辑上的概念,而 Partition 是物理上的概念,每个 Partition 对应于一个 log 文件,该 log 文件中存储的就是 Producer 生产的数据
- Producer 生产的数据会不断追加到该 log 文件末端,且每条数据都有自己的 Offset
- 消费者组中的每个消费者,都会实时记录自己消费到了哪个 Offset,以便出错恢复时,从上次的位置继续消费
5.kafka的分区
-
分区原因
方便在集群中扩展,每个 Partition 可以通过调整以适应它所在的机器,而一个 Topic 又可以有多个 Partition 组成,因此可以以 Partition 为单位读写了。
可以提高并发,因此可以以 Partition 为单位读写了。 -
分区的原则
我们需要将 Producer 发送的数据封装成一个 ProducerRecord 对象。 -
分区可以减少吗
我们可以使用 bin/kafka-topics.sh 命令对 Kafka 增加 Kafka 的分区数据,但是 Kafka 不支持减少分区数。
Kafka 分区数据不支持减少是由很多原因的,比如减少的分区其数据放到哪里去?是删除,还是保留?删除的话,那么这些没消费的消息不就丢了。如果保留这些消息如何放到其他分区里面?追加到其他分区后面的话那么就破坏了 Kafka 单个分区的有序性。如果要保
证删除分区数据插入到其他分区保证有序性,那么实现起来逻辑就会非常复杂。
6. 副本机制的了解
kafka的分区有副本(replica)的概念,有一个leader和多个follow,生产者和消费者都之和leader交互,当leader挂掉以后,会重新从其他的副本中选取出一个新的leader
- 好处
1.Kafka 通过给特定 Topic 指定多个 Partition, ⽽各个 Partition 可以分布在不同的 Broker上, 这样便能提供⽐较好的并发能⼒(负载均衡)。
2.Partition 可以指定对应的 Replica 数, 这也极⼤地提⾼了消息存储的安全性, 提⾼了容灾能⼒,不过也相应的增加了所需要的存储空间。
7.如何保证消费的顺序性
7.1 kafka如何保证消息的顺序性
kafka 中的每个 partition 中的消息在写入时都是有序的,而且单独一个 partition 只能由一个消费者去消费,可以在里面保证消息的顺序性。但是分区之间的消息是不保证有序的。
7.2 如何保证消费的顺序性
1.一个Topic对应一个patition,太暴力,效率低,不支持
2.发送消息的时候指定key/partiton,对于同一类型的key,保存在同一个partition中,因为partition才能够真正保证消息的顺序性
8.如何保证消息不丢失
-
生产者丢消息
通过判断生产者的发送结果是否发生成功,设置重试间隔和重试次数 -
消费者丢消息
消费者拉取了分区的消息后,消费者会自动提交offset,这时候挂了,便会丢失数据
手动提交也会有问题,如果消费者已经消费了数据,但是还没有提交数据就挂了,这时相同的数据可能会被重复消费
大多数情况下还是会选择手动提交,选择手动提交,那么就要解决重复消费的问题,见下面 -
kafka弄丢了消息(leader挂了)
acks = all,⽣产者(Producer) 很重要的⼀个参数,all 代表则所有副本都要接收到该消息之后该消息才算真正成功被发送
replication.factor 》=3,保证每个分区至少有三个副本
min.insync.replicas> 1,消息⾄少要被写⼊到 2 个副本才算是被成功发送。 min.insync.replicas 的默认值为 1 ,在实际⽣产中应尽量避免默认值 1。
⼀般推荐设置成 replication.factor =min.insync.replicas + 1
9.如何保证消息不被重复消费
-
多线程消费模式下数据的重复消费
把这些线程放到一个消费者组,逻辑上一个消费者组对应一个消费者,一个Topic只能被一个消费者消费一次,消费者组内的多线程分别消费不同的partition即可 -
原因
- 原因1:强行kill线程,导致消费后的数据,offset没有提交。
- 原因2:设置offset为自动提交,关闭kafka时,如果在close之前,调用 consumer.unsubscribe() 则有可能部分offset没提交,下次重启会重复消费。
- 原因3(重复消费最常见的原因):消费后的数据,当offset还没有提交时,partition就断开连接。比如,通常会遇到消费的数据,处理很耗时,导致超过了Kafka的session timeout时间(0.10.x版本默认是30秒),那么就会re-blance重平衡,此时有一定几率offset没提交,会导致重平衡后重复消费。
- 原因4:当消费者重新分配partition的时候,可能出现从头开始消费的情况,导致重发问题。
- 原因5:当消费者消费的速度很慢的时候,可能在一个session周期内还未完成,导致心跳机制检测报告出问题。
10.ZK在kafka中的作用
11. 请简述下你在哪些场景下会选择 Kafka?
日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、HBase、Solr等。
消息系统:解耦和生产者和消费者、缓存消息等。
用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
流式处理:比如spark streaming和 Flink
12. 请谈一谈 Kafka 数据一致性原理
一致性就是说不论是老的 Leader 还是新选举的 Leader,Consumer 都能读到一样的数据。
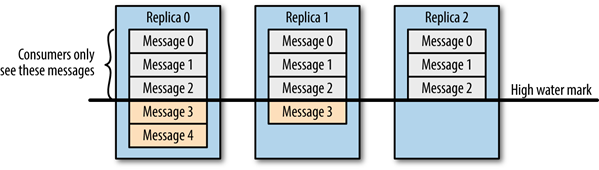
-
假设分区的副本为3,其中副本0是 Leader,副本1和副本2是 follower,并且在 ISR 列表里面。虽然副本0已经写入了 Message4,但是 Consumer 只能读取到 Message2。因为所有的 ISR 都同步了 Message2,只有 High Water Mark 以上的消息才支持 Consumer 读取,而 High Water Mark 取决于 ISR 列表里面偏移量最小的分区,对应于上图的副本2,这个很类似于木桶原理。
-
这样做的原因是还没有被足够多副本复制的消息被认为是“不安全”的,如果 Leader 发生崩溃,另一个副本成为新 Leader,那么这些消息很可能丢失了。如果我们允许消费者读取这些消息,可能就会破坏一致性。试想,一个消费者从当前 Leader(副本0) 读取并处理了 Message4,这个时候 Leader 挂掉了,选举了副本1为新的 Leader,这时候另一个消费者再去从新的 Leader 读取消息,发现这个消息其实并不存在,这就导致了数据不一致性问题。
-
当然,引入了 High Water Mark 机制,会导致 Broker 间的消息复制因为某些原因变慢,那么消息到达消费者的时间也会随之变长(因为我们会先等待消息复制完毕)。延迟时间可以通过参数 replica.lag.time.max.ms 参数配置,它指定了副本在复制消息时可被允许的最大延迟时间。
13. ISR、OSR、AR 是什么?
ISR:In-Sync Replicas 副本同步队列
OSR:Out-of-Sync Replicas
AR:Assigned Replicas 所有副本
ISR是由leader维护,follower从leader同步数据有一些延迟,超过相应的阈值会把 follower 剔除出 ISR, 存入OSR(Out-of-Sync Replicas )列表,新加入的follower也会先存放在OSR中。AR=ISR+OSR。